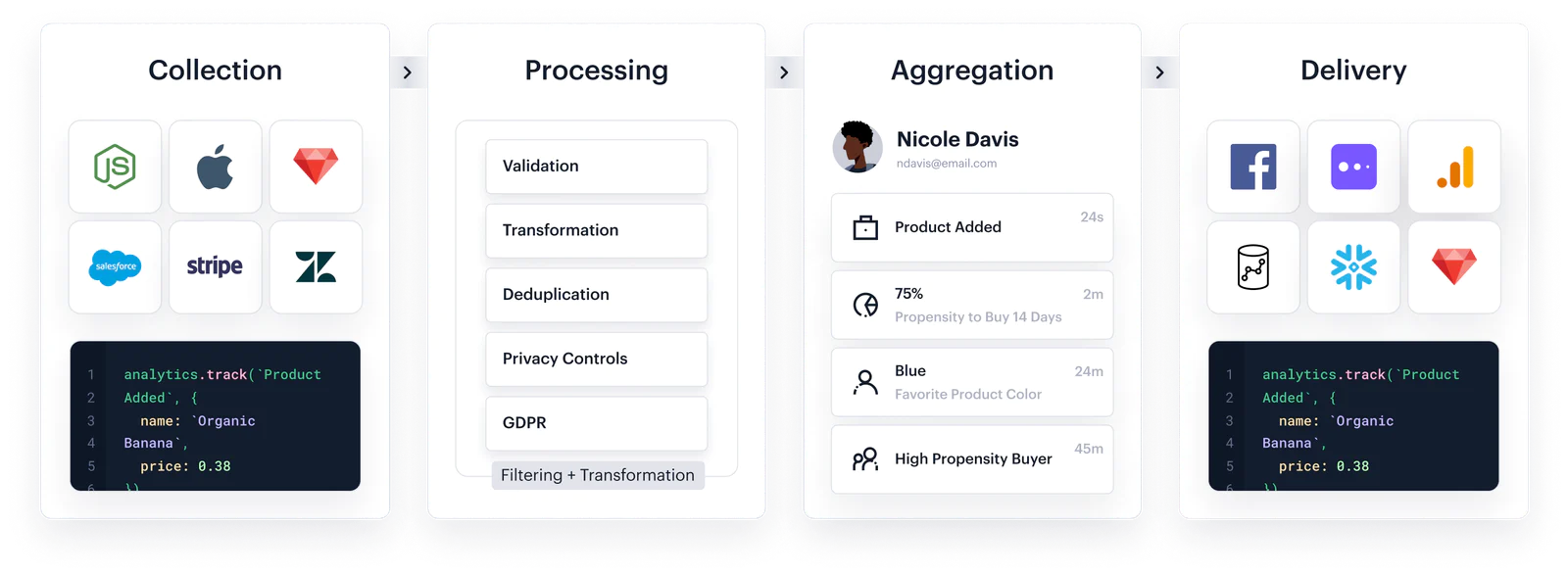
Collection
Customer data lives everywhere: your website, your mobile apps, and internal tools.
That’s why collecting and processing all of it is a tricky problem. Segment has built libraries, automatic sources, and functions to collect data from anywhere—hundreds of thousands of times per second.
We’ve carefully designed each of these areas to ensure they’re:
- Performant (batching, async, real-time, off-page)
- Reliable (cross-platform, handle rate-limits, retries)
- Easy (setup with a few clicks, elegant, modern API)
Here’s how we do it.

















