Infrastructure
The Segment Infrastructure
Under the hood of the system that processes 400,000 events every second.
Infrastructure
Under the hood of the system that processes 400,000 events every second.
Customer data lives everywhere: your website, your mobile apps, and internal tools.
That’s why collecting and processing all of it is a tricky problem. Segment has built libraries, automatic sources, and functions to collect data from anywhere—hundreds of thousands of times per second.
We’ve carefully designed each of these areas to ensure they’re:
Here’s how we do it.

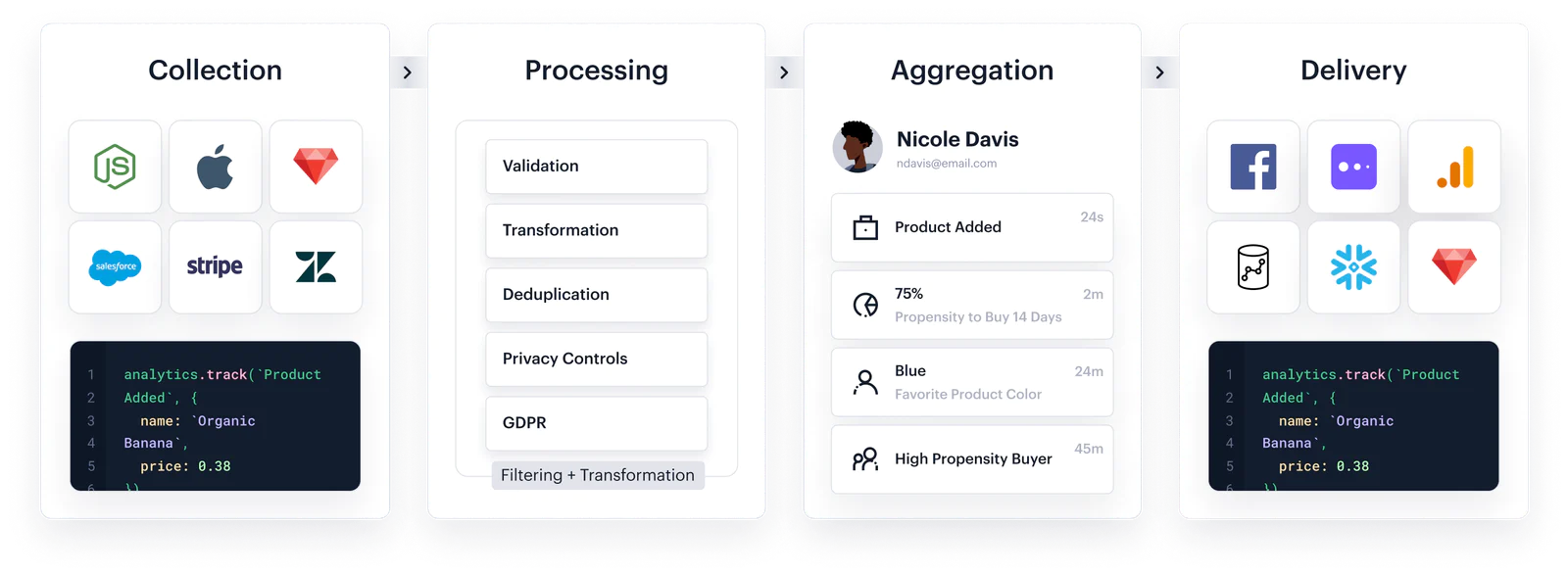
Collection
You need to collect customer data from your website and mobile apps tens of thousands of times per second. It should never crash and always work reliably. Here’s how we do it…
segmentio/analytics.js (4,500 stars)
No one likes having to fiddle around with REST APIs. We’ve built libraries in 12 major languages to get you up and running, quickly.
Each batch of requests is gzip compressed, decreasing the bytes on the wire by 10-20x. Thanks to this batching and compression, our SDKs reduce energy overhead by 2-3x. This means longer battery life for your users.
JavaScript, iOS, and Android all locally queue data to make sure you don’t miss events. Each library uses fast, atomic transactions to ensure fidelity.
If there’s a network failure due to a connection reset, timeout, or DNS error, our SDKs retry until the request is successful. This improves data deliverability by 0.6%, meaning that you never miss an event.

Collection
To fully understand your users, you’ll have to mirror the databases of your favorite SaaS tools (Adwords, Stripe, Salesforce, and more) into your systems of record. Here’s how we do it…
Salesforce, Stripe, and Zendesk dynamically rate limit from 60 requests per minute to 1,000 per hour. We automatically handle these limits and backoff to get fast data without triggering resets.
You shouldn’t need to pull all data, every time. If the API supports it, we’ll keep historically checkpoints and incrementally sync just the delta. This speeds sync times by 60-100x.
Some APIs will only give back changes in individual fields. You don’t have to materialize all of these changes yourself, we’ll nicely materialize these deltas into a single “merged” object.

Collection
Often, you’ll want to pull in data from arbitrary web services or internal sources. They’ll have webhooks for triggering new data entries, but no standardized way of getting that data. Here’s how we do it…
You don’t have to worry about setting up a server, terminating connections, or other configuration. We handle all of the plumbing, so you write your business logic and go.
We’ll automatically scale functions up and down, as well as handle their concurrency. Any data which is discarded is automatically published to a Dead Letter Queue for later processing.
No need to copy and paste little bits of JSON. Sample one live request, and then let autocomplete handle all of the rest.

Collection
To collect all this data, you need an API that never goes down. We’ve ensured that our high-performance Go servers are always available to accept new data. With a 30ms response time, and “six nines” of availability, we’re collecting 1M rps, handling spikes of 3-5x in minutes.
We have our servers intentionally scaled down at the edge. It allows us to ingest events even with news spikes or live events.
Our Tracking API is written as a high-performance golang service. Each instance can handle tens of thousands of requests concurrently. We’re collecting more than 800,000 RPS.
We queue all data at the edge locally first. In case of a network partition, we can continue processing.
None of our tracking servers require configuration data. Under times of more load, we can bring up new servers without degrading our QoS.

Data can be messy. As anyone who has dealt with third-party APIs, JSON blobs, and semi-structured text knows that only 20-30% of your time is spent driving insights. Most of your time is spent cleaning the data you already have.
At minimum, you’ll want to make sure your data infrastructure can:
Here’s how we do it.

Processing
Sometimes the data you’re collecting isn’t always in the format you want. It’s important that anyone—PMs, marketers, engineers—be able to help clean the data you’re collecting to match your needs.
segmentio/encoding: Our zero-allocation JSON library (598 stars)
It’s not easy to parse and match thousands of requests per second flowing. We’ve built our own custom JSON parser which does zero-memory allocations, and optimized regex parsers to ensure that your data keeps moving.
It’s simple to build a basic transformation worker… but what happens when you have 20 different versions of mobile apps out in the wild, each using different tracking? Our transformations and filters are versioned from the start to let you apply your controls with fine-grained matchers.

Processing
What’s worse than missing data? Duplicated data. It’s impossible to trust your analysis if events show up 2, 3, or more times. That’s why we’ve invested heavily in our Deduplication Infrastructure. It reduces duplicate data by 0.6% over a 30d window.
Delivering billions of messages exactly once (133 Comments)
segmentio/kafka-go (2,500 stars)
We’ve partitioned Kafka based upon the ID of each message. Whenever a deduplication worker starts, it first reads the Kafka output topic as the “source of truth” before processing messages.
Each dedupe instance queries from a RocksDB instance, which is replicated via EBS. If a database ever goes missing, it can be re-built from the log. Each one stores 1TB of message IDs on disk.
Most new messages won’t be duplicated at all. RocksDB uses Bloom Filters to ensure that most IDs don’t have to load from disk.

Processing
If you’re working with data today, you must be compliant with the GDPR and CCPA. Both grant individual users the ability to request that their data be deleted or suppressed. It’s sort of like finding 100k needles in 100 billion haystacks—but here’s how we do it.
An internal service called Cerebro manages all of the state machines and cleanup work around user suppression and deletion. It’s backed by Kafka and MySQL, replicated 3 times to ensure data ia actually deleted.
For every deletion and suppression request logged, we store the receipt in an audit database. It helps provide peace of mind (and compliance) that your data has actually been deleted.
Each userId is automatically replicated to a local sqlite instance attached to the worker. It ensures that lookups are fast and reliable. Read more.

Individual events don’t tell the full story of a user. For that, you need to combine that data all into the notion of a single profile.
This is where most systems hit their scaling limits. Not only do they need to process tens of thousands of events per second, but they need to route that data to a single partition. This requires:
Here’s how we do it.

Aggregation
Emails, device IDs, primary keys in your database, account IDs—a single user might be keyed in hundreds of different ways! You can’t just overwrite those ties or endlessly traverse cycles in your identity graph. You need a bullet-proof system for tying those users together. Here’s how we do it.
We’ve partitioned Kafka based upon the ID of each message. Whenever a deduplication worker starts, it first reads the Kafka output topic as the “source of truth” before processing messages.
You have your own scheme for managing customers: emails, userIds, device identifiers. customize merging by blocking individual values, limit the number of merged user profiles, or adjust the priority and precedence of individual user IDs.
We’ve built our algorithms to always be deterministic. Under the hood, we create a graph of identities and a separate merge table so that you can always trace how an identity was merged, and then unmerge it down the road.

Aggregation
Personalizing your website isn’t easy. You need millisecond response times to be able to get the page to load quickly. You need a full event history of your user. And you need to be able to make those decisions as the page is loading. Here’s how we do it.
We’ve invested heavily in our infrastructure to ensure that 99% of queries are completed in <300ms
Our Profile API has scaled to meet the personalization requirements of some of the biggest brands in the world. It currently handles millions of requests per day.
Getting the right data to personalize can be difficult. There’s lots of cryptic variables for individual audiences, which aren’t fully tied together. We’ve made it easy by passing back the events as JSON. They’re easy to reason about and fit with your overall tracking plan.

Warehouse data activation
Bring enriched data from your warehouse and activate it anywhere. Reverse ETL makes it easy for data teams to get marketers access to the data they need to build.
Whether you’re sending data to Salesforce, Braze, or any other destination - manage compute costs and ensure teams have access to timely data.
Send data from your warehouse to the Segment destination where it can be merged into identity-resolved profiles that can be synced back to the warehouse.
With access to 450+ destinations, Segment customers can send data from the warehouse down to any supported destination.

Aggregation
Searching through billions of user actions to find who loaded a particular page more than 3 times in a month isn’t easy. You have to run complex aggregations, set up your data structure so they can be quickly and efficiently queried, and run it all on core infra.
We’ve built a custom Flink pipeline to ensure that users get routed with affinity, and quickly. Our pipeline can re-compute membership in audiences in real-time.
To re-build historical audiences, we leverage BigQuery. We’ve created wide tables that allow us to run these audience re-computes over terabytes of data on the fly.
We’ve built an intuitive, simple UI, to create audiences. Under the hood, we parse this into an AST which allows users to dynamically update their audiences with complex aggregations.

Once you finally have data in one spot, there’s one last step—using that data. That means getting it into all of the different consumers and end tools.
In a controlled environment, this is easy. But over the open internet, it’s anything but.
You’re connecting to dozens of APIs. What if one fails? What if it gets slow? What if an API mysteriously changes? How do you ensure nothing goes missing?
You have all sorts of semi-structured data. How do you map it into structured forms like a data lake or a data warehouse.
It’s not easy, but here’s how we’ve built it.
Centrifuge: a reliable system for delivering billions of events per day (65 comments)

Delivery
APIs fail. At any given time, we see dozens of endpoints timing out, returning 5xx errors, or connection resets. We built Centrifuge, infrastructure to reliably retry and deliver messages even in cases of extreme failure. It brings up our message delivery by 1.5% on average.
Centrifuge: a reliable system for delivering billions of events per day (65 comments)
Events which fail once are 10x more likely to fail on a retry. Centrifuge prioritizes real-time events to ensure that failing events don’t back up the queue.
Kafka acts as the backbone for Centrifuge, persisting data across availability zones and ensuring that data will never be lost.
We retry data over a four hour period with exponential backoff. Any data which is not delivered is archived on S3.
Any time one of your events is rejected, we’ll log the error and the message. No need to plumb through error logs, the full request/response payload will show up in the Segment app.

Delivery
Writing integrations is fussy. There’s new APIs to learn, tricky XML and JSON parsing, authentication refreshes, and mapping little bits of data. Often these APIs have little documentation and unexpected error codes. We’ve built out our destinations to handle all of these tiny inconsistencies at scale.
Not all APIs are created equal. SOAP, XML, cryptic error codes and invalid JSON messages are often par for the course.
Each day, our integrations pipeline processes data from 25,000+ companies sending to 700+ integrations. we automatically map every variation of “User Signed Up” “Signed Up” “signup” and “user_signup” so you don’t have to.
Any time one of your events is rejected, we’ll log the error and the message. No need to plumb through error logs, the full request/response payload will show up in the Segment app.

Delivery
Most companies load data into a data warehouse. It’s the source of truth for various analytics deep dives. Getting data in there can be challenging, as you need to consider schema inference, data cleaning, loading at off peak hours, and incrementally syncing new data. Here’s how we do it.
Our warehouses pipeline syncs 6T rows each month across thousands of Snowflake, BigQuery, and Redshift warehouses.
Our customizable scheduler ensures that loading queries don’t block your analysis team. You can schedule at off-peak hours, or run overnight.
We run each part of our pipeline as an individual container job. Even if the last load step fails, we can re-run from the transformed dataset saving hours of sync time.
We’ll take free-form JSON and automatically convert it into whichever database types make the most sense pulled from our schema registry.
A warehouse is only as useful as the ability for analysts to query it. We materialize views of users and objects so that it is easy to join together data as part of a query and intuitive for analysts.

Start connecting your data with Segment.