Goodbye Microservices: From 100s of problem children to 1 superstar
By Alexandra Noonan
Unless you’ve been living under a rock, you probably already know that microservices is the architecture du jour. Coming of age alongside this trend, Segment adopted this as a best practice early-on, which served us well in some cases, and, as you’ll soon learn, not so well in others.
Briefly, microservices is a service-oriented software architecture in which server-side applications are constructed by combining many single-purpose, low-footprint network services. The touted benefits are improved modularity, reduced testing burden, better functional composition, environmental isolation, and development team autonomy. The opposite is a Monolithic architecture, where a large amount of functionality lives in a single service which is tested, deployed, and scaled as a single unit.
In early 2017 we reached a tipping point with a core piece of Segment’s product. It seemed as if we were falling from the microservices tree, hitting every branch on the way down. Instead of enabling us to move faster, the small team found themselves mired in exploding complexity. Essential benefits of this architecture became burdens. As our velocity plummeted, our defect rate exploded.
Eventually, the team found themselves unable to make headway, with 3 full-time engineers spending most of their time just keeping the system alive. Something had to change. This post is the story of how we took a step back and embraced an approach that aligned well with our product requirements and needs of the team.
Segment’s customer data infrastructure ingests hundreds of thousands of events per second and forwards them to partner APIs, what we refer to as server-side destinations. There are over one hundred types of these destinations, such as Google Analytics, Optimizely, or a custom webhook.
Years back, when the product initially launched, the architecture was simple. There was an API that ingested events and forwarded them to a distributed message queue. An event, in this case, is a JSON object generated by a web or mobile app containing information about users and their actions. A sample payload looks like the following:
As events were consumed from the queue, customer-managed settings were checked to decide which destinations should receive the event. The event was then sent to each destination’s API, one after another, which was useful because developers only need to send their event to a single endpoint, Segment’s API, instead of building potentially dozens of integrations. Segment handles making the request to every destination endpoint.
If one of the requests to a destination fails, sometimes we’ll try sending that event again at a later time. Some failures are safe to retry while others are not. Retry-able errors are those that could potentially be accepted by the destination with no changes. For example, HTTP 500s, rate limits, and timeouts. Non-retry-able errors are requests that we can be sure will never be accepted by the destination. For example, requests which have invalid credentials or are missing required fields.
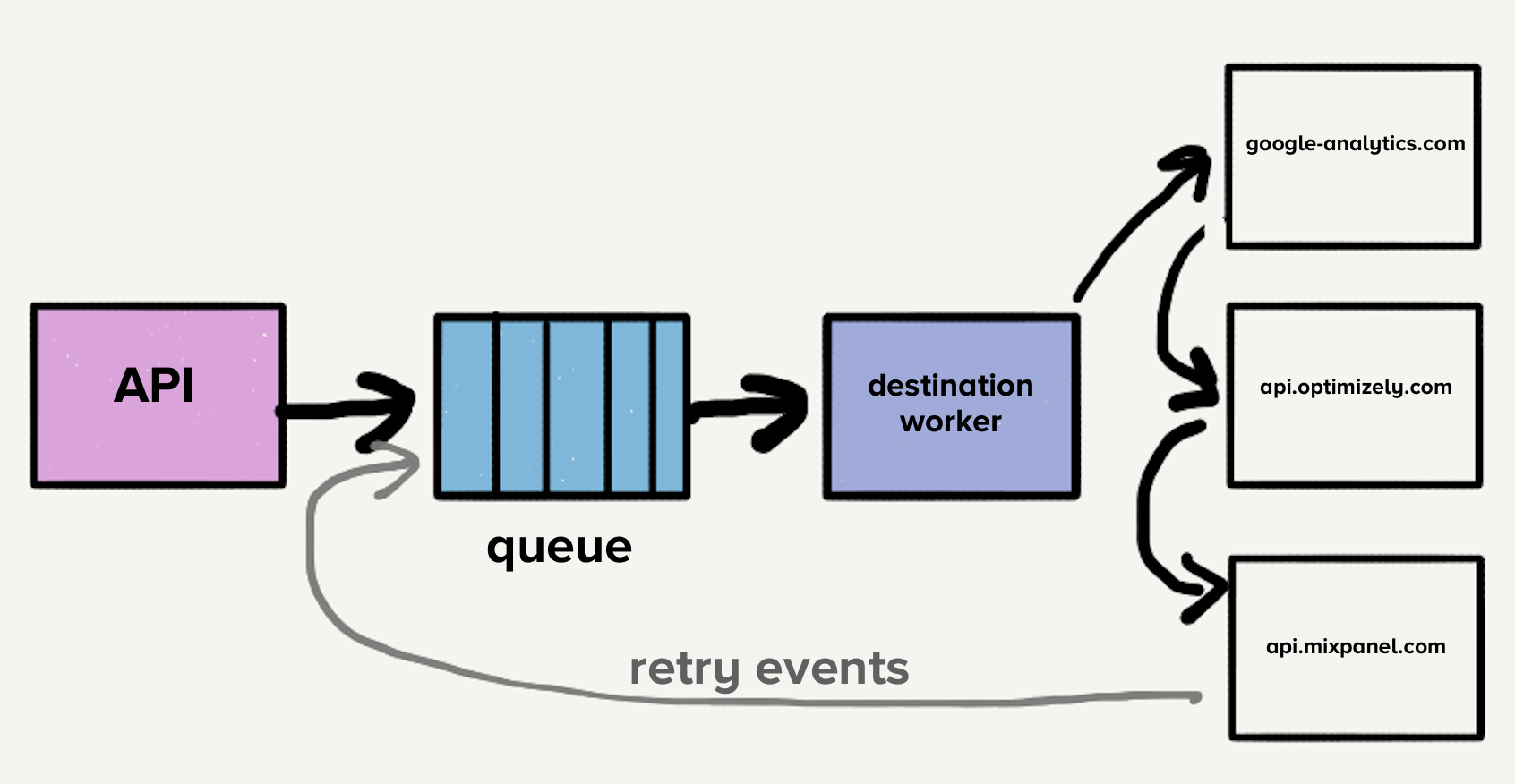
At this point, a single queue contained both the newest events as well as those which may have had several retry attempts, across all destinations, which resulted in head-of-line blocking. Meaning in this particular case, if one destination slowed or went down, retries would flood the queue, resulting in delays across all our destinations.
Imagine destination X is experiencing a temporary issue and every request errors with a timeout. Now, not only does this create a large backlog of requests which have yet to reach destination X, but also every failed event is put back to retry in the queue. While our systems would automatically scale in response to increased load, the sudden increase in queue depth would outpace our ability to scale up, resulting in delays for the newest events. Delivery times for all destinations would increase because destination X had a momentary outage. Customers rely on the timeliness of this delivery, so we can’t afford increases in wait times anywhere in our pipeline.
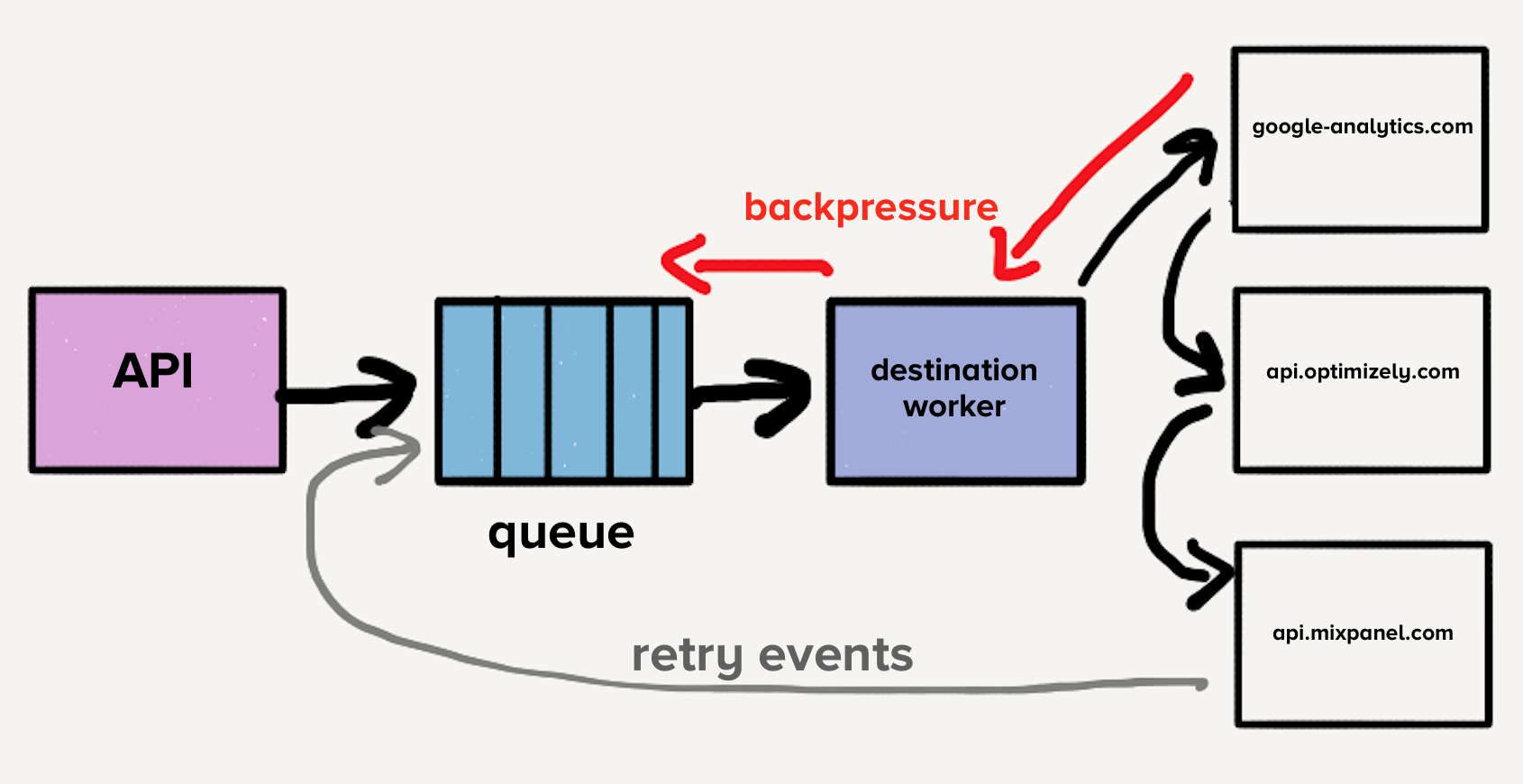
To solve the head-of-line blocking problem, the team created a separate service and queue for each destination. This new architecture consisted of an additional router process that receives the inbound events and distributes a copy of the event to each selected destination. Now if one destination experienced problems, only it’s queue would back up and no other destinations would be impacted. This microservice-style architecture isolated the destinations from one another, which was crucial when one destination experienced issues as they often do.
Each destination API uses a different request format, requiring custom code to translate the event to match this format. A basic example is destination X requires sending birthday as traits.dob in the payload whereas our API accepts it as traits.birthday. The transformation code in destination X would look something like this:
Many modern destination endpoints have adopted Segment’s request format making some transforms relatively simple. However, these transforms can be very complex depending on the structure of the destination’s API. For example, for some of the older and most sprawling destinations, we find ourselves shoving values into hand-crafted XML payloads.
Initially, when the destinations were divided into separate services, all of the code lived in one repo. A huge point of frustration was that a single broken test caused tests to fail across all destinations. When we wanted to deploy a change, we had to spend time fixing the broken test even if the changes had nothing to do with the initial change. In response to this problem, it was decided to break out the code for each destination into their own repos. All the destinations were already broken out into their own service, so the transition was natural.
The split to separate repos allowed us to isolate the destination test suites easily. This isolation allowed the development team to move quickly when maintaining destinations.
As time went on, we added over 50 new destinations, and that meant 50 new repos. To ease the burden of developing and maintaining these codebases, we created shared libraries to make common transforms and functionality, such as HTTP request handling, across our destinations easier and more uniform.
For example, if we want the name of a user from an event, event.name() can be called in any destination’s code. The shared library checks the event for the property key name and Name. If those don’t exist, it checks for a first name, checking the properties firstName, first_name, and FirstName. It does the same for the last name, checking the cases and combining the two to form the full name.
The shared libraries made building new destinations quick. The familiarity brought by a uniform set of shared functionality made maintenance less of a headache.
However, a new problem began to arise. Testing and deploying changes to these shared libraries impacted all of our destinations. It began to require considerable time and effort to maintain. Making changes to improve our libraries, knowing we’d have to test and deploy dozens of services, was a risky proposition. When pressed for time, engineers would only include the updated versions of these libraries on a single destination’s codebase.
Over time, the versions of these shared libraries began to diverge across the different destination codebases. The great benefit we once had of reduced customization between each destination codebase started to reverse. Eventually, all of them were using different versions of these shared libraries. We could’ve built tools to automate rolling out changes, but at this point, not only was developer productivity suffering but we began to encounter other issues with the microservice architecture.
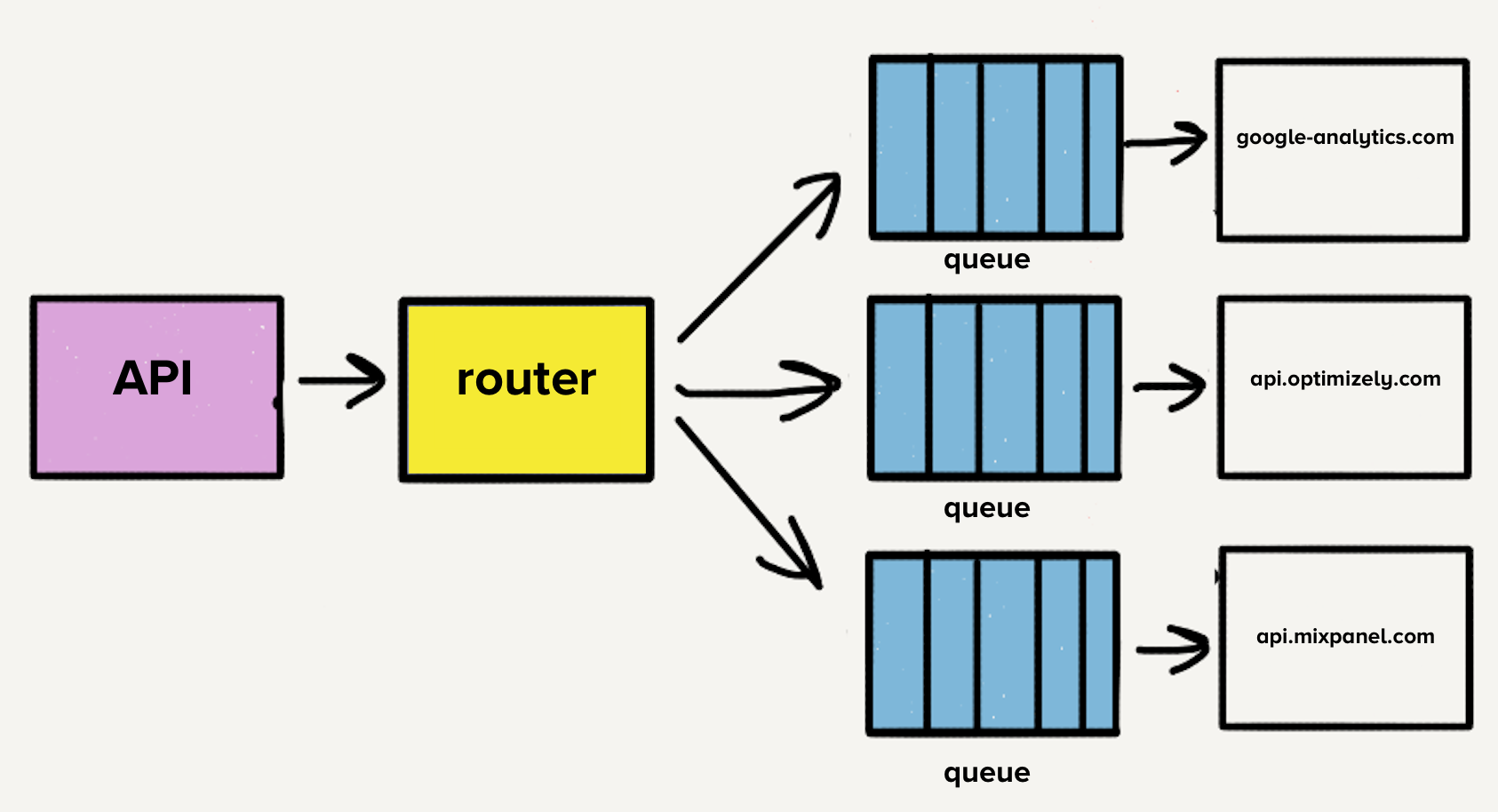
The additional problem is that each service had a distinct load pattern. Some services would handle a handful of events per day while others handled thousands of events per second. For destinations that handled a small number of events, an operator would have to manually scale the service up to meet demand whenever there was an unexpected spike in load.
While we did have auto-scaling implemented, each service had a distinct blend of required CPU and memory resources, which made tuning the auto-scaling configuration more art than science.
The number of destinations continued to grow rapidly, with the team adding three destinations per month on average, which meant more repos, more queues, and more services. With our microservice architecture, our operational overhead increased linearly with each added destination. Therefore, we decided to take a step back and rethink the entire pipeline.
The first item on the list was to consolidate the now over 140 services into a single service. The overhead from managing all of these services was a huge tax on our team. We were literally losing sleep over it since it was common for the on-call engineer to get paged to deal with load spikes.
However, the architecture at the time would have made moving to a single service challenging. With a separate queue per destination, each worker would have to check every queue for work, which would have added a layer of complexity to the destination service with which we weren’t comfortable. This was the main inspiration for Centrifuge. Centrifuge would replace all our individual queues and be responsible for sending events to the single monolithic service.
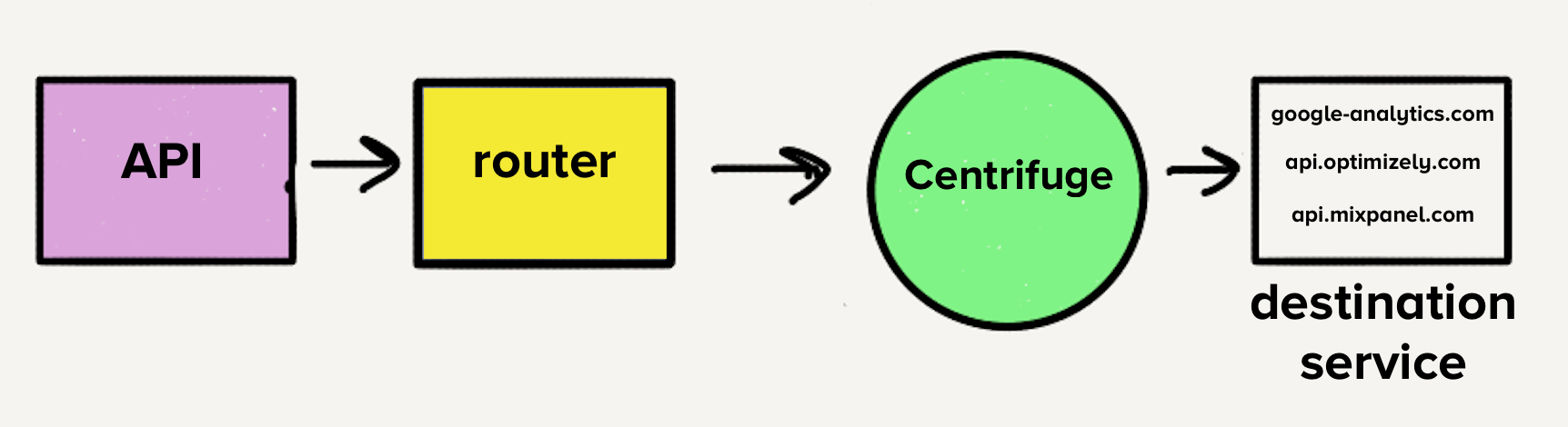
Given that there would only be one service, it made sense to move all the destination code into one repo, which meant merging all the different dependencies and tests into a single repo. We knew this was going to be messy.
For each of the 120 unique dependencies, we committed to having one version for all our destinations. As we moved destinations over, we’d check the dependencies it was using and update them to the latest versions. We fixed anything in the destinations that broke with the newer versions.
With this transition, we no longer needed to keep track of the differences between dependency versions. All our destinations were using the same version, which significantly reduced the complexity across the codebase. Maintaining destinations now became less time consuming and less risky.
We also wanted a test suite that allowed us to quickly and easily run all our destination tests. Running all the tests was one of the main blockers when making updates to the shared libraries we discussed earlier.
Fortunately, the destination tests all had a similar structure. They had basic unit tests to verify our custom transform logic was correct and would execute HTTP requests to the partner’s endpoint to verify that events showed up in the destination as expected.
Recall that the original motivation for separating each destination codebase into its own repo was to isolate test failures. However, it turned out this was a false advantage. Tests that made HTTP requests were still failing with some frequency. With destinations separated into their own repos, there was little motivation to clean up failing tests. This poor hygiene led to a constant source of frustrating technical debt. Often a small change that should have only taken an hour or two would end up requiring a couple of days to a week to complete.
The outbound HTTP requests to destination endpoints during the test run was the primary cause of failing tests. Unrelated issues like expired credentials shouldn’t fail tests. We also knew from experience that some destination endpoints were much slower than others. Some destinations took up to 5 minutes to run their tests. With over 140 destinations, our test suite could take up to an hour to run.
To solve for both of these, we created Traffic Recorder. Traffic Recorder is built on top of yakbak, and is responsible for recording and saving destinations’ test traffic. Whenever a test runs for the first time, any requests and their corresponding responses are recorded to a file. On subsequent test runs, the request and response in the file is played back instead requesting the destination’s endpoint. These files are checked into the repo so that the tests are consistent across every change. Now that the test suite is no longer dependent on these HTTP requests over the internet, our tests became significantly more resilient, a must-have for the migration to a single repo.
I remember running the tests for every destination for the first time, after we integrated Traffic Recorder. It took milliseconds to complete running the tests for all 140+ of our destinations. In the past, just one destination could have taken a couple of minutes to complete. It felt like magic.
Once the code for all destinations lived in a single repo, they could be merged into a single service. With every destination living in one service, our developer productivity substantially improved. We no longer had to deploy 140+ services for a change to one of the shared libraries. One engineer can deploy the service in a matter of minutes.
The proof was in the improved velocity. In 2016, when our microservice architecture was still in place, we made 32 improvements to our shared libraries. Just this year we’ve made 46 improvements. We’ve made more improvements to our libraries in the past 6 months than in all of 2016.
The change also benefited our operational story. With every destination living in one service, we had a good mix of CPU and memory-intense destinations, which made scaling the service to meet demand significantly easier. The large worker pool can absorb spikes in load, so we no longer get paged for destinations that process small amounts of load.
Moving from our microservice architecture to a monolith overall was huge improvement, however, there are trade-offs:
Fault isolation is difficult. With everything running in a monolith, if a bug is introduced in one destination that causes the service to crash, the service will crash for all destinations. We have comprehensive automated testing in place, but tests can only get you so far. We are currently working on a much more robust way to prevent one destination from taking down the entire service while still keeping all the destinations in a monolith.
In-memory caching is less effective. Previously, with one service per destination, our low traffic destinations only had a handful of processes, which meant their in-memory caches of control plane data would stay hot. Now that cache is spread thinly across 3000+ processes so it’s much less likely to be hit. We could use something like Redis to solve for this, but then that’s another point of scaling for which we’d have to account. In the end, we accepted this loss of efficiency given the substantial operational benefits.
Updating the version of a dependency may break multiple destinations. While moving everything to one repo solved the previous dependency mess we were in, it means that if we want to use the newest version of a library, we’ll potentially have to update other destinations to work with the newer version. In our opinion though, the simplicity of this approach is worth the trade-off. And with our comprehensive automated test suite, we can quickly see what breaks with a newer dependency version.
Our initial microservice architecture worked for a time, solving the immediate performance issues in our pipeline by isolating the destinations from each other. However, we weren’t set up to scale. We lacked the proper tooling for testing and deploying the microservices when bulk updates were needed. As a result, our developer productivity quickly declined.
Moving to a monolith allowed us to rid our pipeline of operational issues while significantly increasing developer productivity. We didn’t make this transition lightly though and knew there were things we had to consider if it was going to work.
We needed a rock solid testing suite to put everything into one repo. Without this, we would have been in the same situation as when we originally decided to break them apart. Constant failing tests hurt our productivity in the past, and we didn’t want that happening again.
We accepted the trade-offs inherent in a monolithic architecture and made sure we had a good story around each. We had to be comfortable with some of the sacrifices that came with this change.
When deciding between microservices or a monolith, there are different factors to consider with each. In some parts of our infrastructure, microservices work well but our server-side destinations were a perfect example of how this popular trend can actually hurt productivity and performance. It turns out, the solution for us was a monolith.
The transition to a monolith was made possible by Stephen Mathieson, Rick Branson, Achille Roussel, Tom Holmes, and many more.
Special thanks to Rick Branson for helping review and edit this post at every stage.

It’s free to connect your data sources and destinations to the Segment CDP. Use one API to collect analytics data across any platform.