Why Microservices Work For Us
By Calvin French-Owen
At Segment, we’ve fully embraced the idea of microservices; but not for the reasons you might think.
The microservices vs. monoliths debate has been pretty thoroughly discussed, so I won’t completely re-hash it here. Microservices proponents say that they provide better scalability and are the best way to split responsibilty across software engineering teams. While the pro-monolith group say that microservices are too operationally complex to begin with.
But a major benefit of running microservices is largely absent from today’s discussions: visibility.
When we’re getting paged at 3am on a Tuesday, it’s a million times easier to see that a given worker is backing up compared to adding tracing through every single function call of a monolithic app.
That’s not to say you can’t get good visiblity from more tightly coupled code, it’s just rarer to have all the right visibility from day one.
Where does that visibility come from? Consider for a moment the standard tools that are part of our ops arsenal: htop, sysdig, iftop, ps, etc.
None of them monitor individual program execution: hot codepaths, stack size, etc. The battle-tested tools we’ve built over the past 20 years are all built around the concepts of hosts, processes, or drives.
With a distributed system, we can add in requests and network throughput to our metrics, but most tools still tend to aggregate at a host or service level.
The process-centric nature of monitoring tools makes it really difficult to get a sense of where a program is actually spending time. With a monolithic app, our best options to debug are either to run the program against a profiler or to implement our own timing metrics.
Now that’s kind of crazy when you think about it. Most of the reason flamegraphs are so useful is that we don’t have that detailed amount of monitoring at the level of individual function calls.
So instead of trying to shoe-horn lots of functionality into monoliths, at Segment we’ve doubled down on microservices. We’re betting that container scheduling and orchestration will continue to get easier and more powerful, while most metrics and monitoring will continue to be dominated by the idea of ‘hosts’ and ‘services’.
The caveat here is that microservices only work so long as it’s actually easy to create new services. Otherwise we’ve just traded a visibility problem for a provisioning problem.
In other posts, we’ve talked a little bit about what our services look like, and how we build them with terraform. And now, we’ve started splitting each service into modules, so we can re-use the exact configuration between stage and prod.
Here’s an example of a simple auth service, using terraform as our configuration to set up all of our resources:
For the curious, you can check out an example of the full module definition.
As long as there’s a singificant benefit (free metrics) and low cost (10-line terraform script), we remove the temptation to tack on different functionality into an existing service.
And so far, that approach has been working quite well.
Segment is a bit unusual–instead of microservices which are coordinating together, we have a lot of what I’d call “microworkers.” Fundamentally, it’s the same concept, but the worker doesn’t serve requests to clients. Instead, the typical Segment worker reads some data from a queue, does some processing on it, and then acks the message.
These workers end up being a lot simpler than services because there are no dependencies. There’s no coupling or worrying that a given problem with one worker will compound and disrupt the rest of a system. If a service is acting up, there’s just a single queue that ends up backing up. And we can scale additional workers to handle the load.
There are a few forces at work which make tiny workers the right call for us. But the biggest comes from our team size and relative complexity of what we’re trying to build.
Microservices are usually touted when the team grows to a size where there are too many people working on the same codebase. At that point, it makes sense to shard ownership of the codebase by team. But we’ve seen it be equally helpful with a small team as well.
Most folks I talk with are surprised at how small our engineering team is. To give you a rough sense of our scale:
400 private repos
70 different services (workers)
10 engineers
We’re in the postion of having a large product scope and a small engineering team. So if I’m currently on-call and get paged, it could be for code that I wrote 6-months ago and haven’t touched since.
And that’s the place where tiny, well-defined, services shine.
Here’s the typical scenario: first there’s an alert which gets triggered because a particular queue depth is backing up.
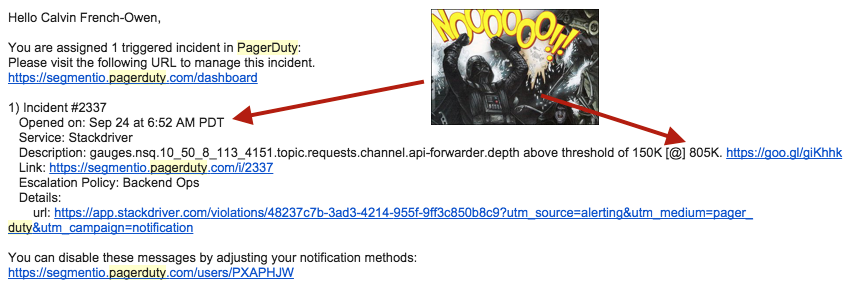
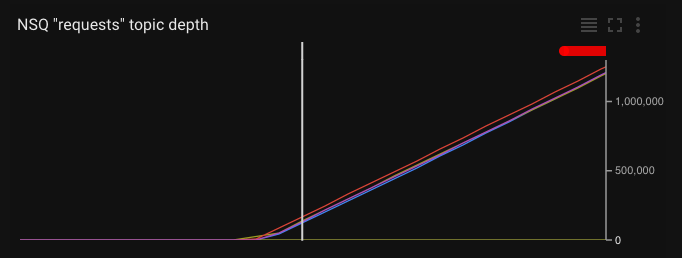
We can verify this is really the case (and isn’t getting better) by checking the queue depth in our monitoring tools.
At that point we know exactly which worker is backing up (since each worker subscribes to a single queue), and which logs to look at. Each service logs with its own tags, so we don’t have to worry about unrelated logs interleaving within a single app for multiple requests.
We can look at Datadog for a single dashboard containing that worker’s CPU, Memory, and the responses and latency coming from it’s ELB. Once we’ve identified the problem, it’s a question of reading through 50-100 line file to isolate exactly where the problem is happening (let’s play spot the memory leak!).
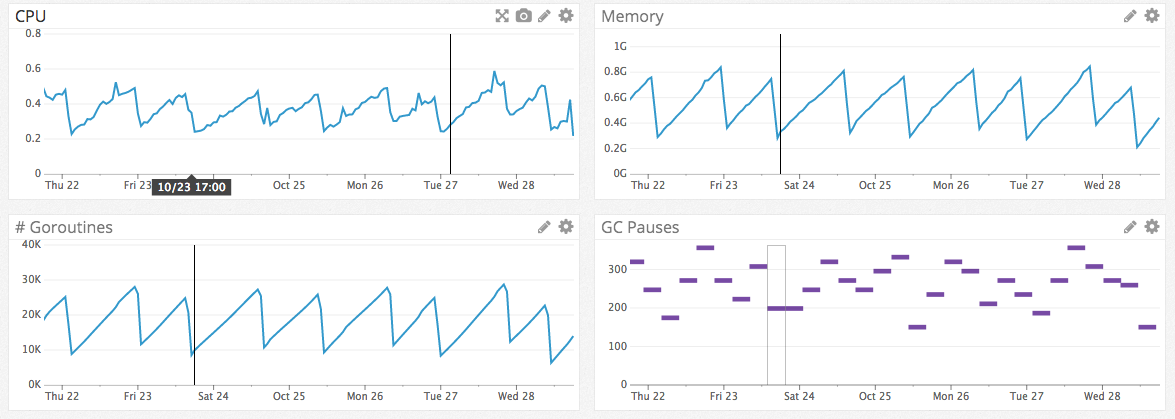
With a monolith, we could add individual monitoring specifically for each endpoint. But why bother when we get it for free by running code as part of its own process?
Not to mention the fact that we also get isolated CPU, memory, and latency (if the service sits behind an ELB) out of the box. It’s infinitely easier to track down a memory leak in a hundred-line worker with a single codepath than it is in a monolithic app with hundreds of endpoints.
I understand this approach won’t work for everyone. And it requires a pretty significant investment in up-front tooling to make sure that creating a new service from scratch has everything it needs. Depending on your team, workload, and product scope, it might not make sense.
But for any product operating with a high level of operational complexity and load, I’d choose the microservice architecture every time. It’s made our infrastructure flexible, scalable, and far easier to monitor–without sacrificing developer productivity.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.