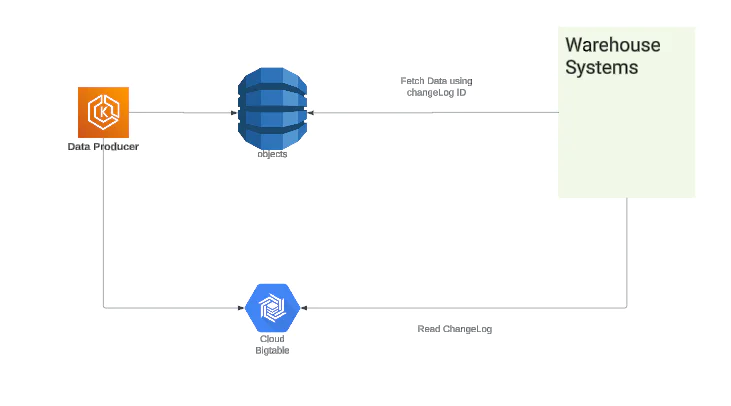
At Twilio Segment, the objects pipeline processes hundreds of thousands of messages per second and stores the data state in a DynamoDB table. This data is used by the warehouse integrations to keep the customer warehouses up-to-date. The system originally consisted of a Producer service, DynamoDB, and BigTable. We had this configuration for the longest time, with DynamoDB and BigTable being key components which powered our batch pipeline.
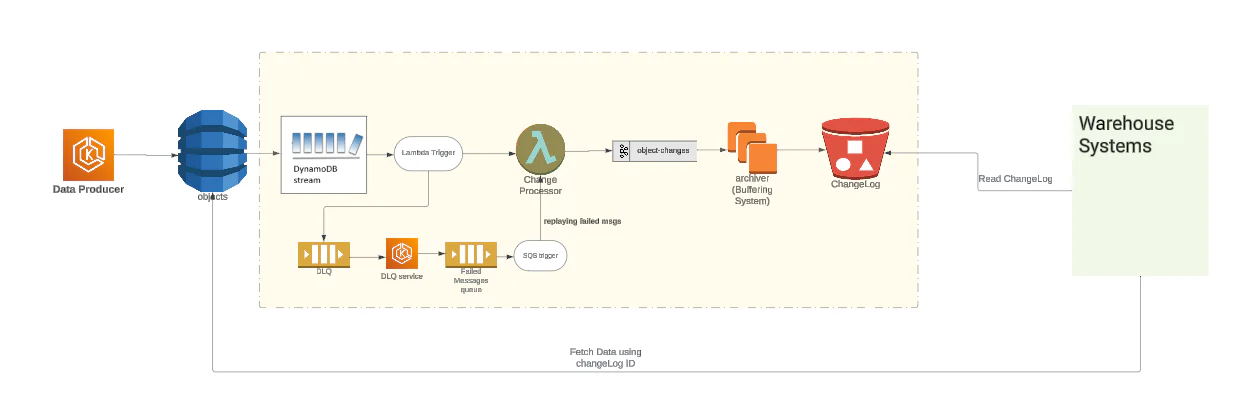
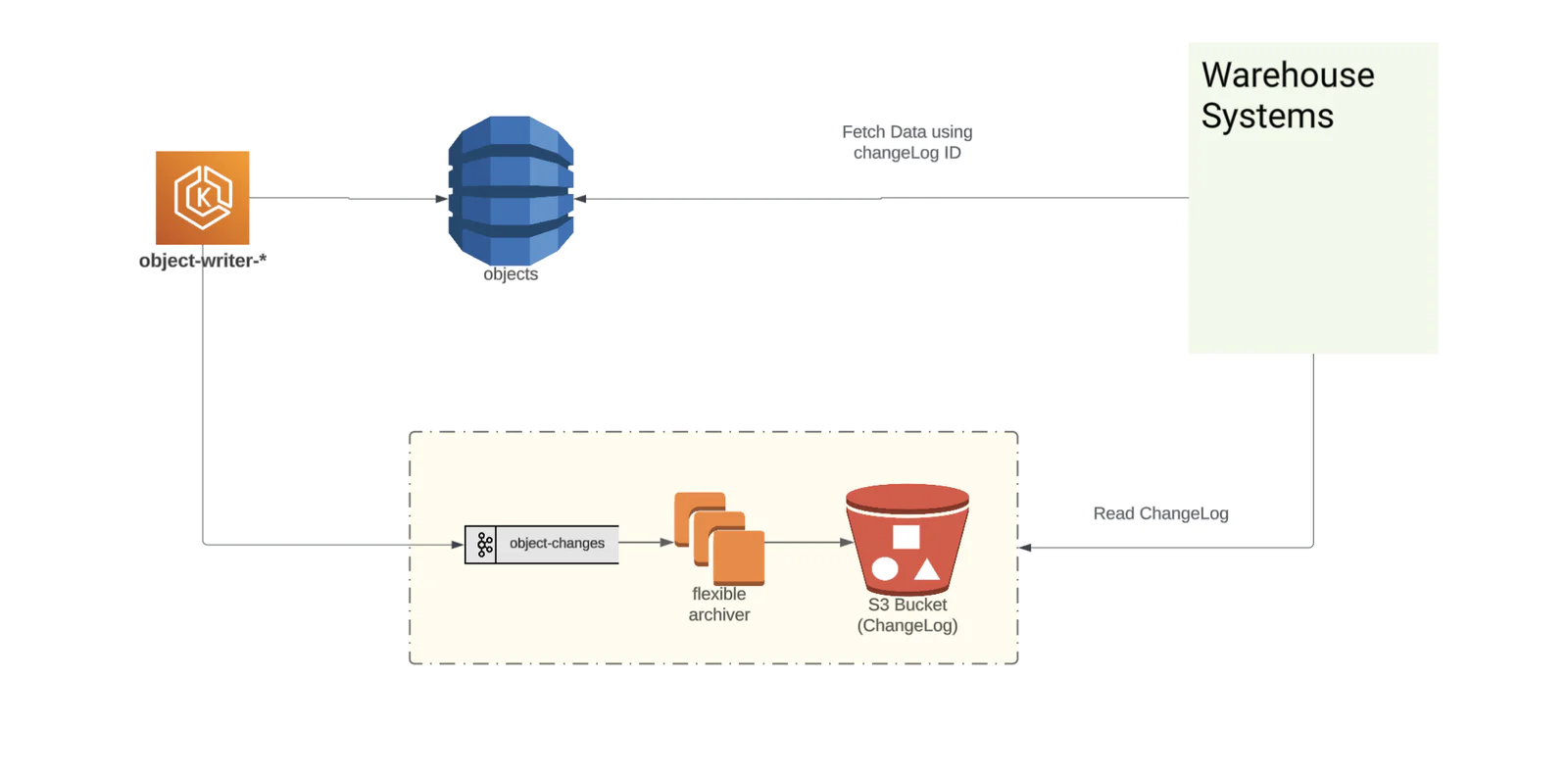
We recently revamped our platform by migrating from BigTable to offset the growing cost concerns, consolidate infrastructure to AWS, and simplify the number of components.
In this blog post, we will take a closer look at the objects pipeline, specifically focusing on how the changelog sub-system which powers warehouse products has evolved over time. We will also share how we reduced the operational footprint and achieved significant cost savings by migrating to S3 as our changelog data store.
Why did we need a changelog store?
The primary purpose of changelog in our pipeline was to provide the ability to query newly created/modified DynamoDB Items for downstream systems. In our case, these were warehouse integrations. Ideally, we could have easily achieved this using DynamoDB’s Global Secondary Index which would minimally contain:
But due to the very large size of our table, creating a GSI for the table is not cost-efficient. Below are some numbers related to our table:
Avg size of item is 900 Bytes
Monthly storage costs $0.25/GB
Total size of the table today is ~1 PetaByte
The total number of items back then was 399 Billion. Today it is 958 Billion and still growing.
Initial System, V1
In the V1 system, we used BigTable as our changelog as it suited our requirements quite well. It provided low-latency read and write access to data, which made it suitable for real-time applications.