Classic Twilio Engage Audiences let you group users or accounts based on event behavior and traits tracked within Segment. Now, Linked Audiences makes it easy to combine real-time behavioral data, Customer AI predictive traits, and rich entity data from your own data warehouse, all within a simple audience builder. This ensures that marketers no longer need to wait for data teams to build rich targeted audiences lists.
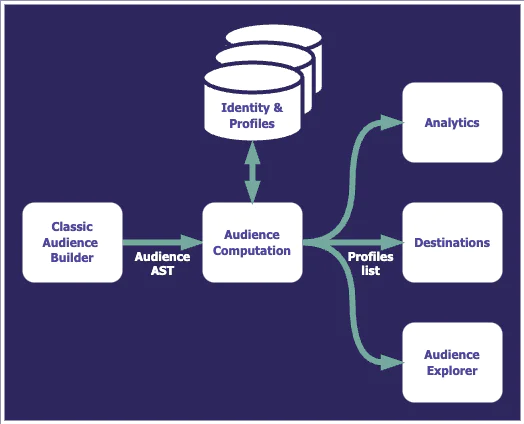
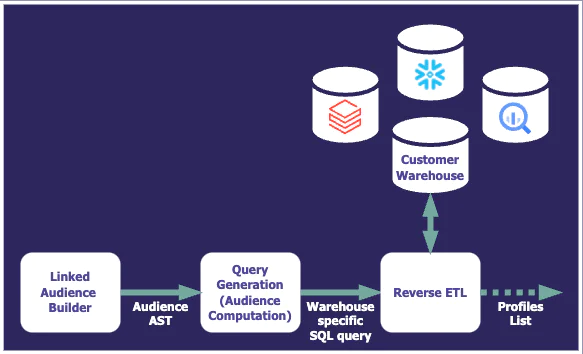
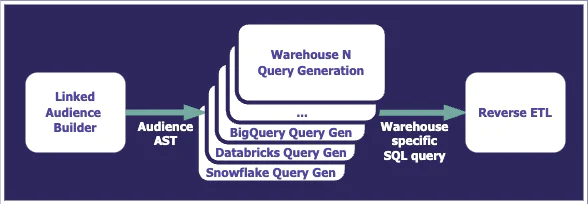
The audience computation
In an audience flow, the interactive input from the Audience Builder (or from the CreateAudience API) is converted into an abstract syntax tree (AST) that represents the audience. This AST is then used by an audience computation service that will find the profiles fitting the audience targeting criteria, using the power of Segment’s identity resolution, event tracking, and trait data associated with them. The resulting list of matching profiles then can be synchronized to hundreds of Destinations, and you can access them with the Profile API, download them as a CSV file, or visualize them through the Audience Explorer.