Imagine a data activation process where complex mappings are automatically generated using AI with just a few clicks, yet you still retain full control to modify the suggestions.
That ease of creation is possible with the introduction of Suggested Mappings, Twilio Segment’s latest feature designed to simplify and enhance the tedious task of data mapping. By leveraging AI technology, Suggested Mappings automates the mapping of data warehouse columns to destination fields, providing you with smart suggestions while allowing you to tweak and perfect each mapping. Experience the perfect blend of automation and customization, accelerating your path to activating your data.
The Challenge
In the current data activation workflow for RETL, users must manually connect data warehouses to various destinations, select necessary actions, and map each column individually.
There are several reasons why this process is both time-consuming and error-prone:
Data warehouses often contain complex and nested structures, making it challenging to understand and correctly map data to the appropriate fields.
With potentially hundreds or thousands of columns, the sheer volume of data adds to the labor-intensive nature of this task.
The diversity in data types and formats requires meticulous attention to detail, increasing the likelihood of errors.
The repetitive and tedious nature of manual mapping exacerbates these issues, leading to inconsistencies and human errors.
By using AI to assist users in this process, Suggested Mappings addresses these issues, providing a more efficient, accurate, and consistent way to map data from warehouses to destinations.
Our Solution
Here’s a detailed look at the key components and how they work together to achieve this:
1. JSON Schema for the Destination Action:
In Segment Action Destinations, each “Action” defines an operation to be performed in a third-party destination. This includes specifying the type of operation (e.g., creating a user, updating an object) and all the required/optional data and their types required to execute this operation. This comprehensive definition can be modeled using a JSON schema, effectively representing the “API” for the destination. The JSON schema serves as a blueprint that outlines the structure and data types expected by the destination, ensuring that all necessary fields are accurately populated.
2. Data Warehouse Schema and Sample Data:
The data that needs to be mapped originates from the user’s data warehouse. This data includes valuable information for the mapping process:
Schema: This is the structure of the data, consisting of column names and their respective data types.
Sample Data: The actual data stored in each column, providing real-world examples of the data that will be mapped. Sample data is crucial when column names in the schema are not informative enough, as it offers context and clarity. It also helps in identifying and correctly mapping nested JSON structures, ensuring that complex data types are handled accurately.
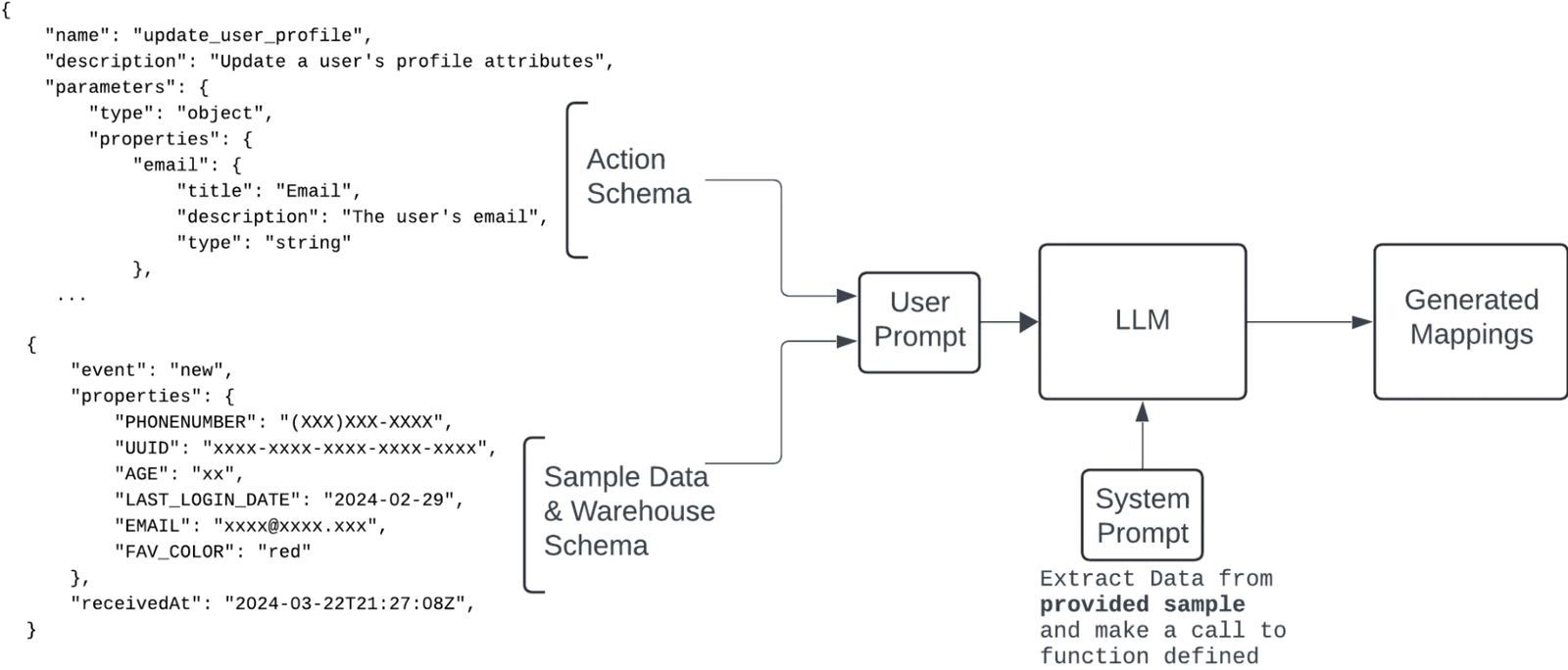
Using these two components, we can abstract the mapping problem as an LLM function calling problem, which LLMs are well-suited to handle. The process involves the following steps:
Schema Analysis: The LLM analyzes the JSON schema of the destination action to understand the required data fields and their types.
Data Extraction: The LLM examines the schema and sample data from the data warehouse, identifying the relevant columns and their data types.
Function Call Generation: The LLM uses the extracted data to generate a “Function Call” that conforms to the JSON schema of the destination action. This function call includes all the necessary parameters, mapped correctly from the data warehouse to the destination fields.
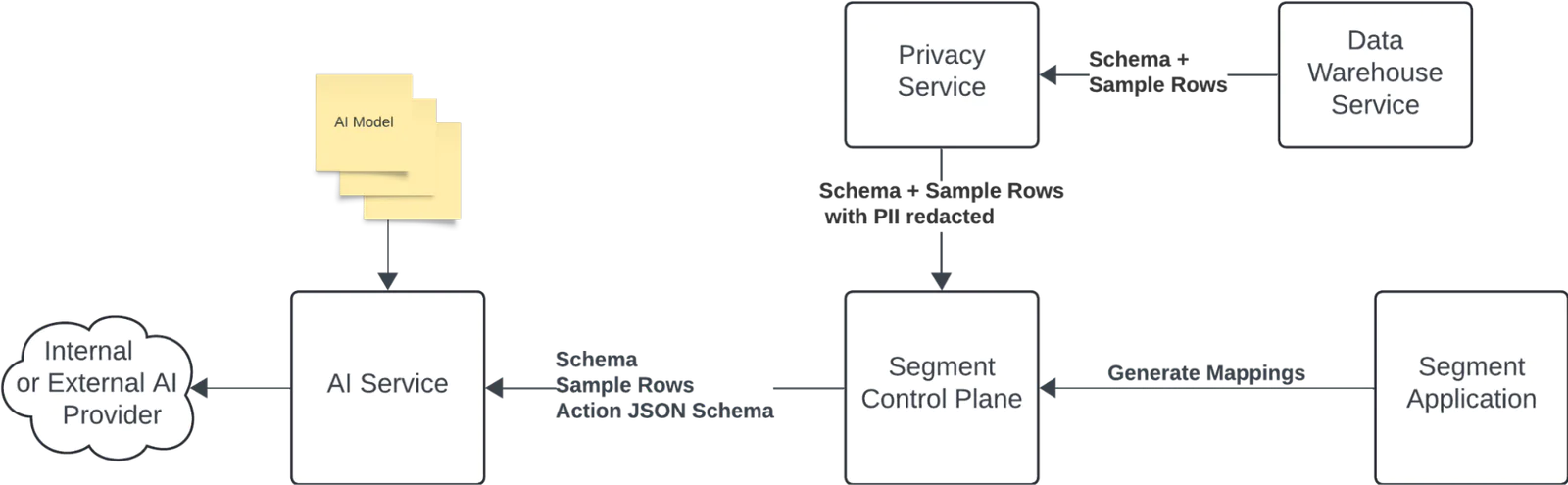
Figure 1 highlights the high-level approach that we use to generate mappings using LLMs.