Thanks to OpenAI's ChatGPT feature, Artificial Intelligence is capturing the public’s imagination like never before. While OpenAI didn't invent AI, they have played a pivotal role in making generative AI widely accessible and engaging for the masses.
As individuals explore the creative side of AI, businesses are getting in on the fun, leveraging AI to enhance customer relationships. By focusing on tangible examples of AI solving real customer challenges, we can appreciate its true impact beyond the hype.
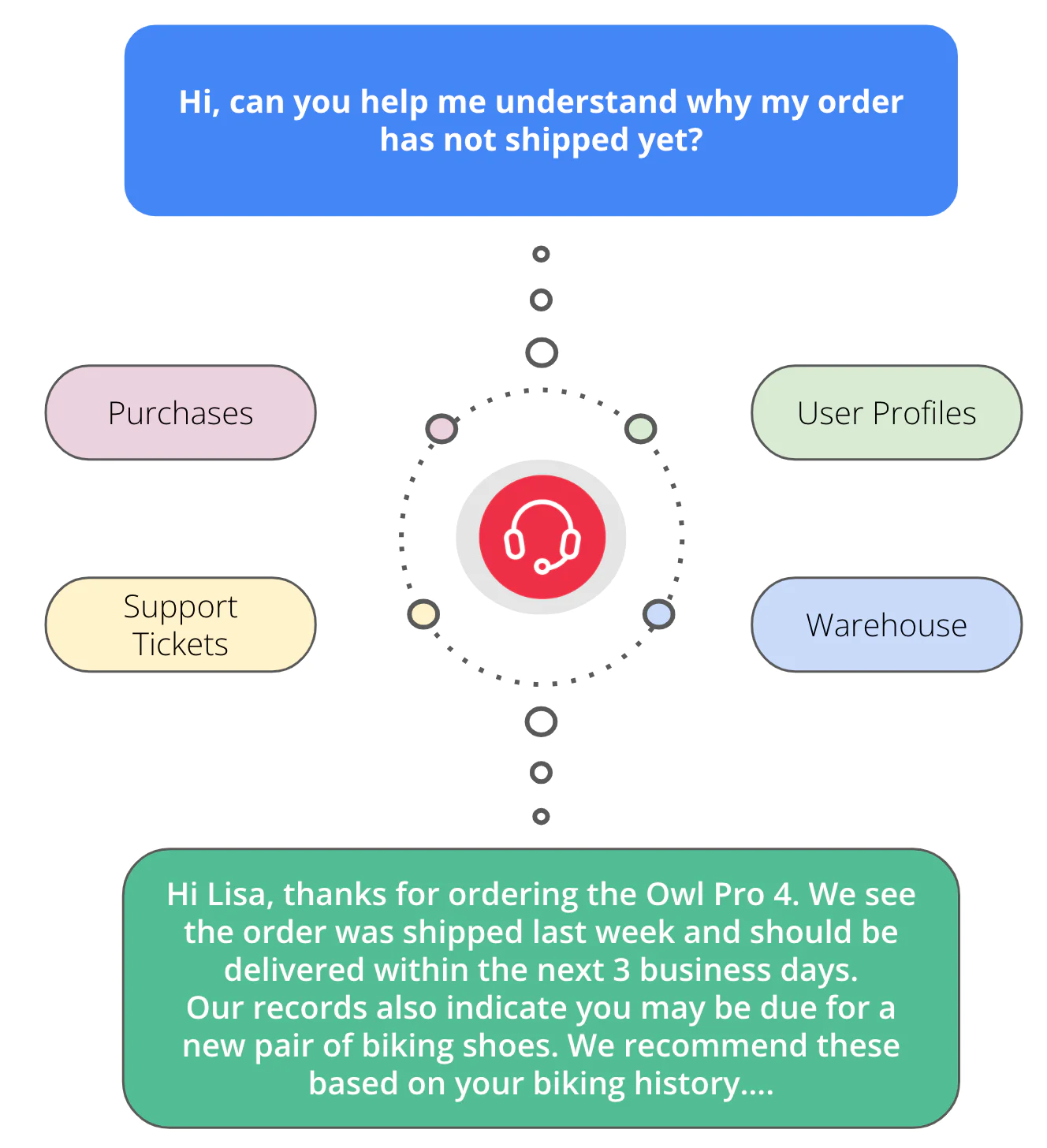
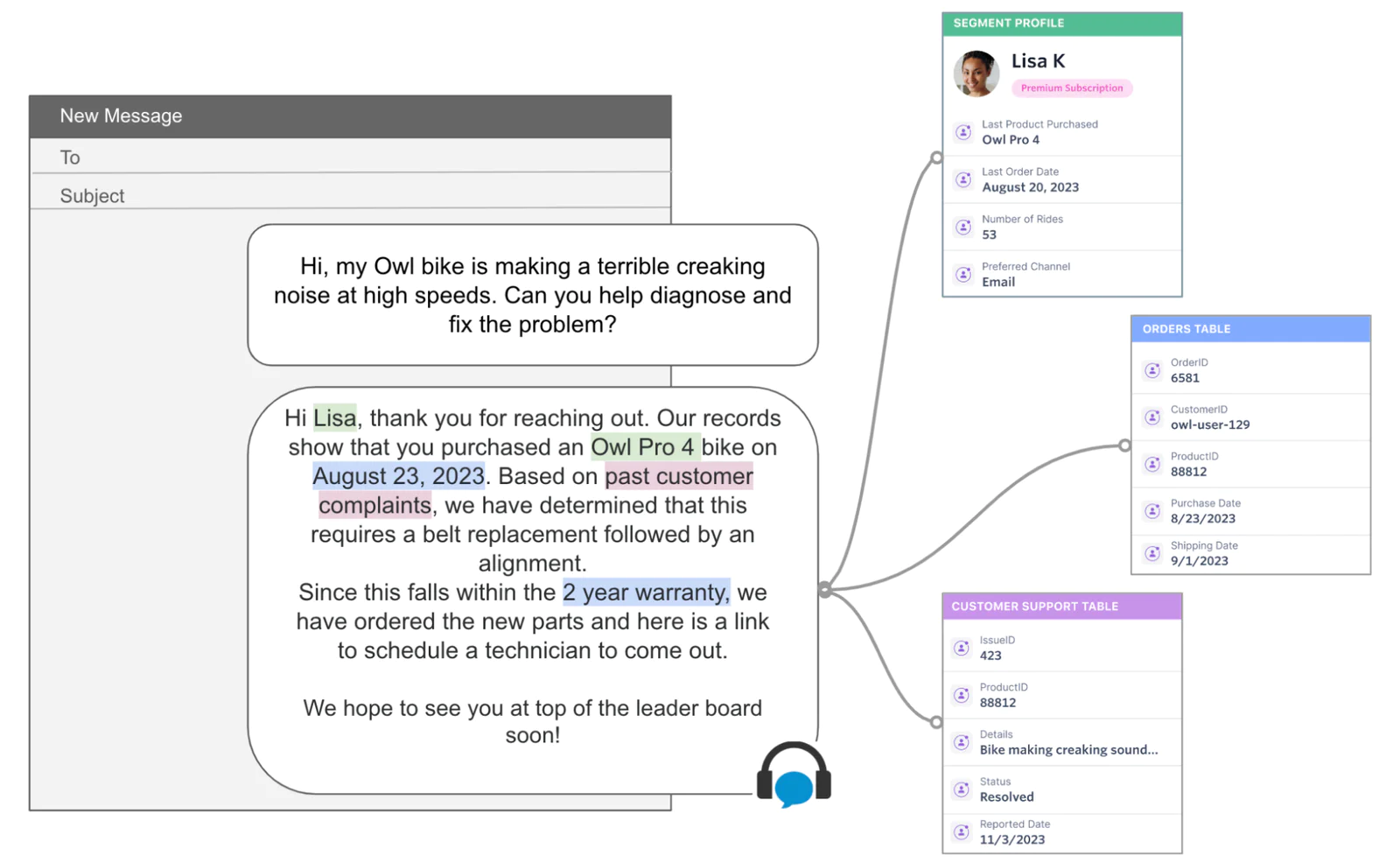
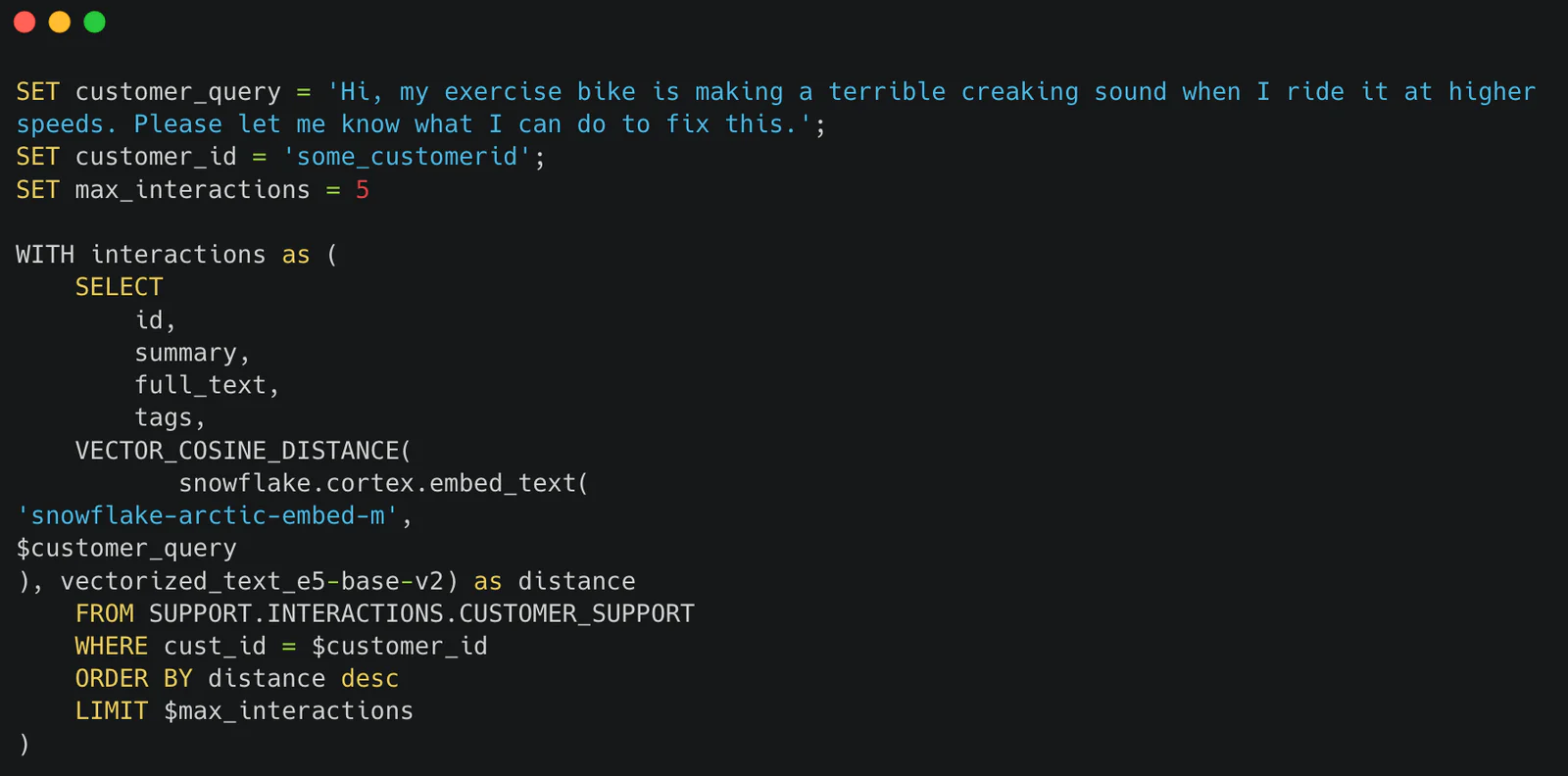
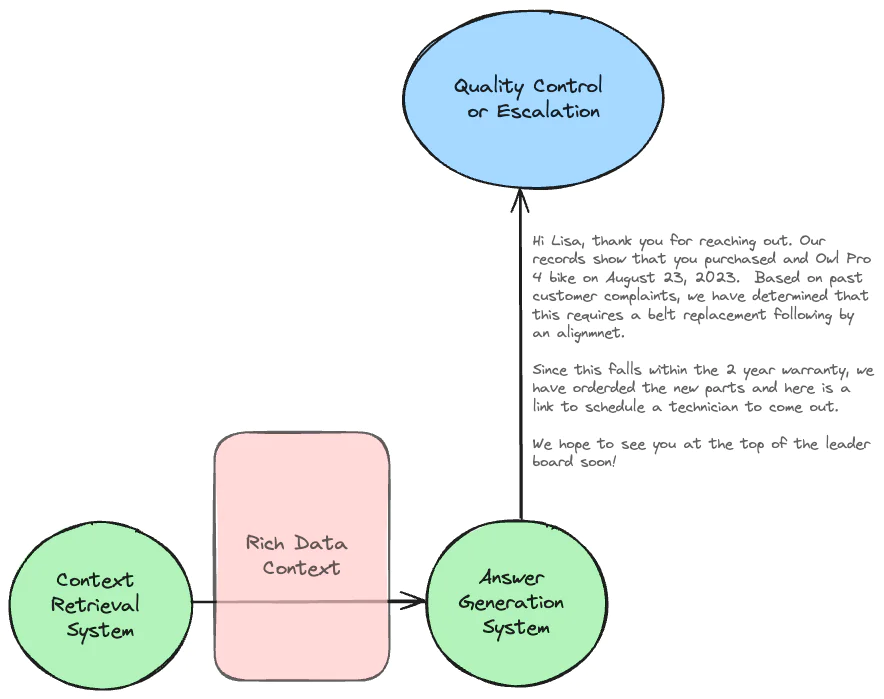
In this blog, we will introduce an example of how Twilio Segment uses an AI powered customer support workflow that is able to understand a full 360 view of the customer, including their previous purchases, documentation of those productions, and prior support interactions. This rich context, sourced from a data warehouse, greatly increases the chance of an appropriate tailored response to the support request and reduces the need to escalate to expert agents.
Background Context
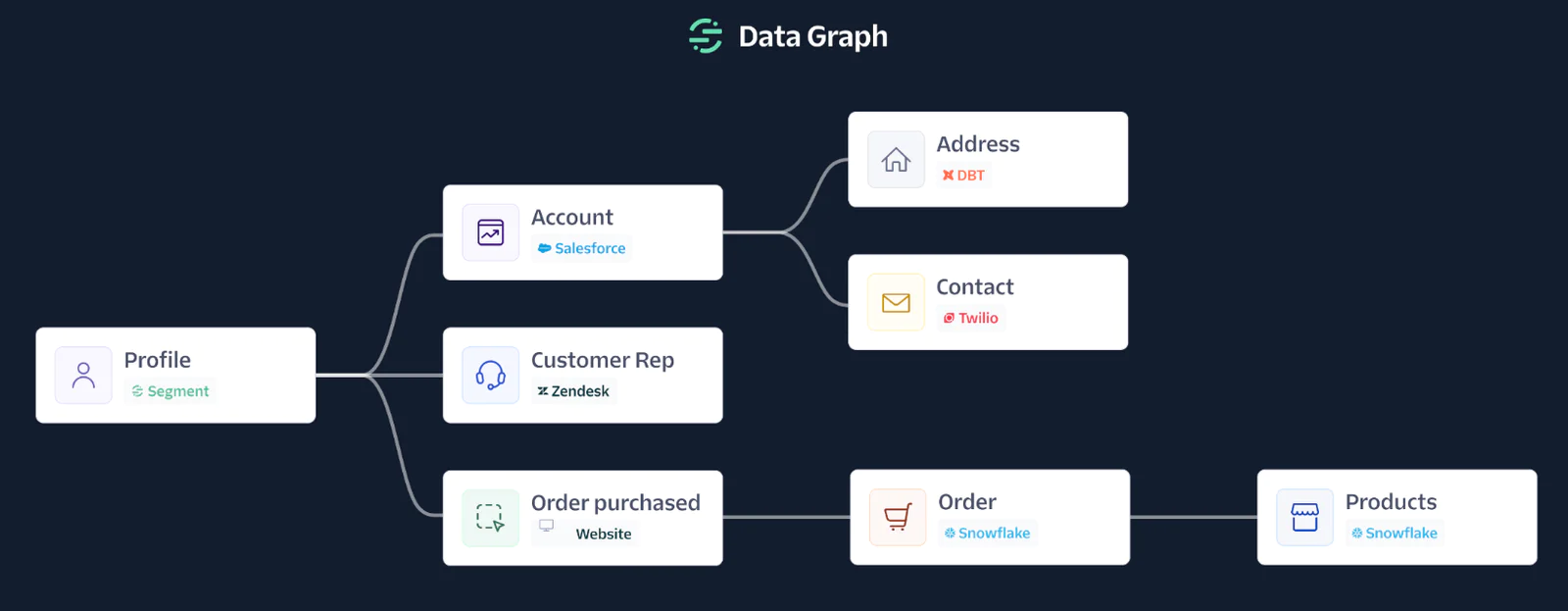
Companies have vast amounts of data stored in their data warehouses, but don’t always have the capability to turn these data stores into actionable value. This is where a semantic layer such as Segment’s Data Graph comes into play.
By enabling businesses to map and understand the relationships between different datasets about their customers with tremendous flexibility, data becomes democratized by empowering marketers and business teams with all the data they need to create personalized experiences.
Foundation model LLMs can produce impressive results all on their own, but an increasingly common approach is the use of Retrieval Augmented Generation (RAG) in order to provide valuable context to reduce hallucinations and ensure personalized results. This approach is well suited for many use cases: legal document analysis, medical diagnostics, e-commerce product recommendations, and academic research. A core commonality of these use cases is the need for highly specialized and relevant contextual information. Without enriching the base generative model with this context, the answers will be limited in the specificity and salience.
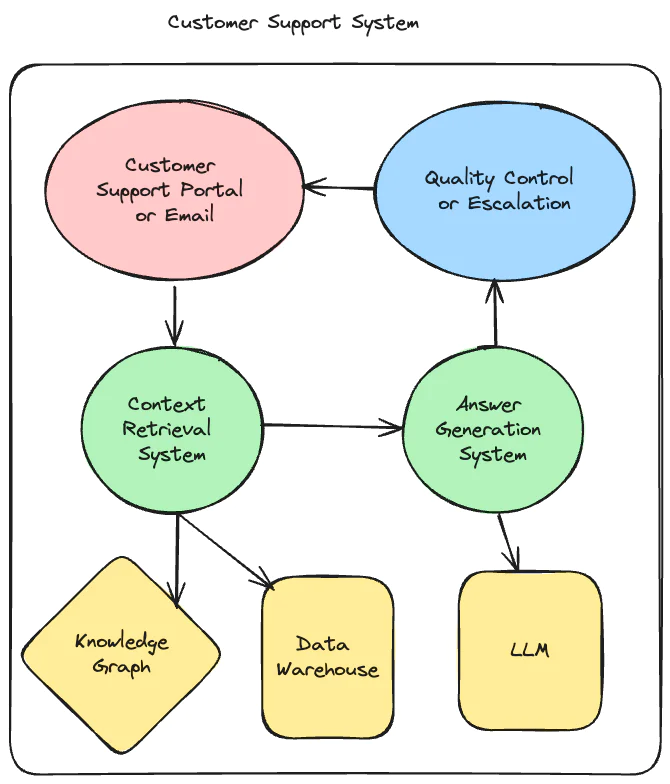
In today’s example, we will walk through an in-depth example to combine these concepts by having a knowledge graph powered by RAG architecture to provide excellent automated customer support. In-context learning is extremely powerful and can often be sufficient to avoid the need for more complicated solutions like fine tuning. Leveraging increasingly large context windows is an excellent way to improve LLM results. However, this approach comes with distinct operational tradeoffs including increased latency, higher costs, and the need to manage RAG infrastructure. For any use case, finding the right balance between these tradeoffs will likely require experimentation. Being able to optionally include additional context or altering the amount of that context that is provided is one path to such experimentation.
Problem
You want to provide an automated customer support experience that can handle as many of the easy cases as possible to preserve the expertise of your customer support specialists for more difficult cases. This is because:
However, AI can only handle routine customer support if we use an appropriate AI architecture. Otherwise, the results could be quite wild, providing hallucinations with incorrect replies.
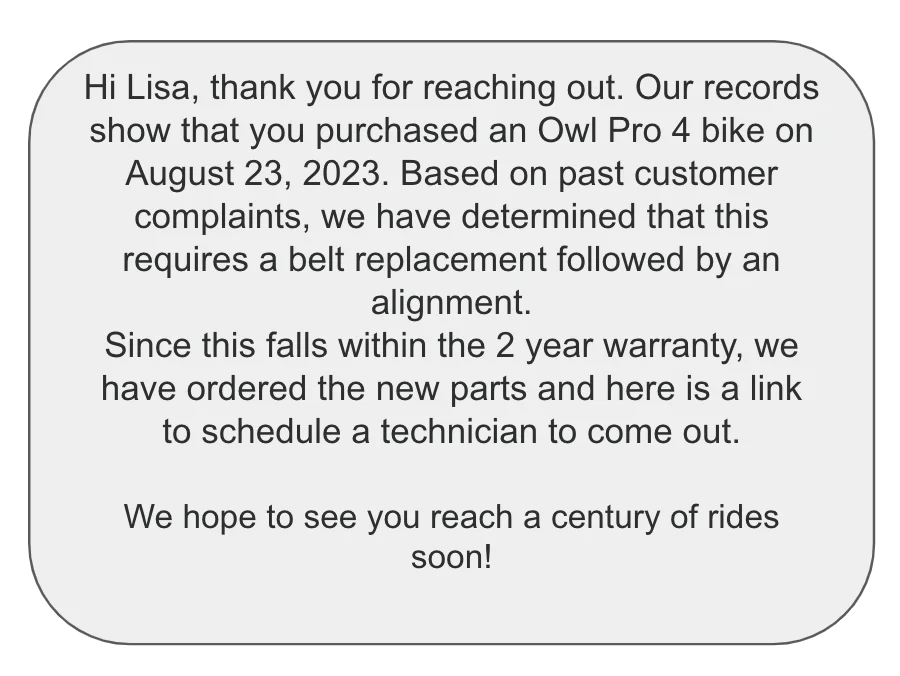
Here’s a concrete example that we can use to understand the use case and have a clear reference point for walking through the details.