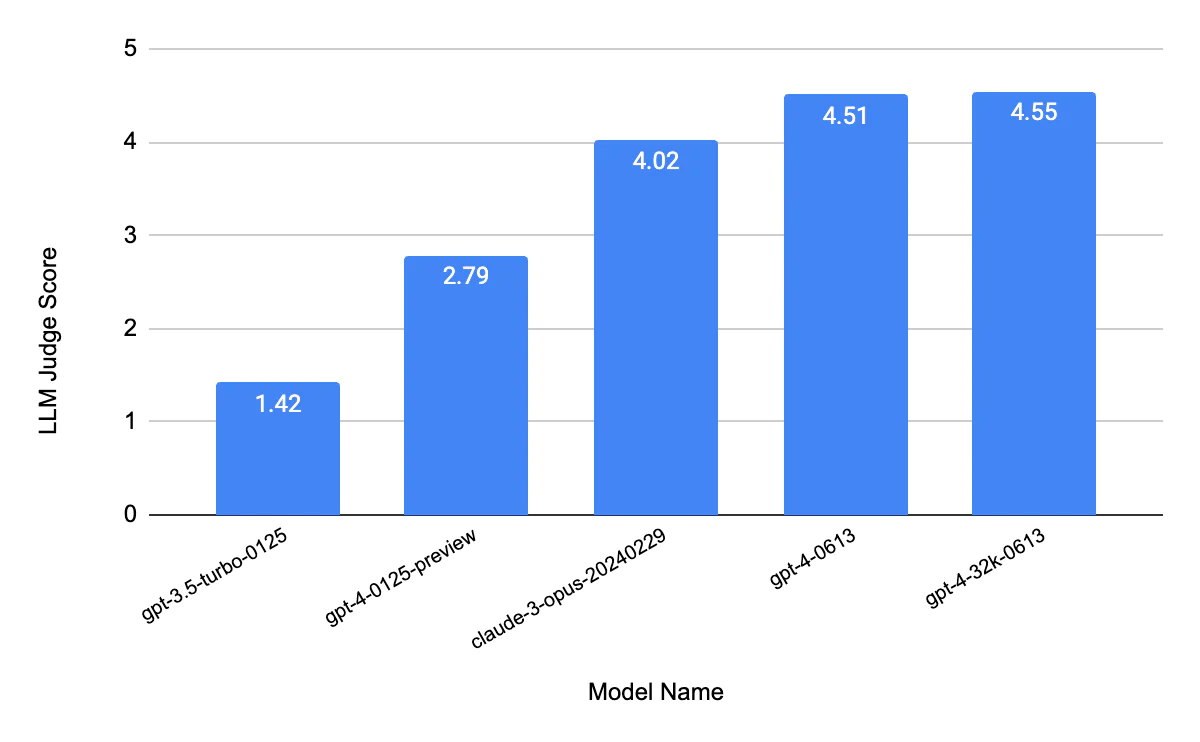
Further, these baseline scores enable us to compare future iterations & optimizations. For example, as we explore adding persistent memory via RAG. adopting a new model, or changing our prompting, we can compare the scores to determine the impact of improvements.
Privacy
At Twilio we believe building products using AI has to be built on three core principles: Transparent, Responsible, Accountable. You can refer to Generative Audiences Nutrition Facts Label for more details on how the data is used for this feature.
Next Steps
While we’re excited about the impact so far, there are additional optimizations we plan to introduce for our evals:
Improving the correlation between LLM Judge and human scores to ensure that our evaluation process aligns well with human judgment.
Orchestrating different agents using frameworks such as AutoGen, which will allow for better coordination and efficiency in the evaluation process.
Applying LLM Judge to different use cases for CustomerAI to explore its potential in various domains and applications.
Conclusion
Our mission at Twilio and Segment is to make magic happen by harnessing the power of LLMs to revolutionize the way marketers build audiences and customer journeys. As we look to the future, we are excited to delve deeper into the potential applications and optimizations of our LLM Judge system, with a focus on concrete advancements and collaborations across the industry.
We encourage those interested in learning more about our work or exploring potential partnerships to reach out to us. In this era of LLMs, we believe that sharing knowledge and learning from one another is crucial to driving innovation and unlocking the full potential of AI-driven solutions.
As we continue to refine our approach and explore new use cases, we remain committed to fostering transparent, responsible, and accountable AI-driven solutions that empower businesses and individuals alike. We hope that by sharing our experiences and learnings, we can inspire others to embark on their own LLM journeys and contribute to the collective growth of the AI community. Together, we can shape the future of audience building and create a world where the magic of LLMs is accessible to all.
Appendix
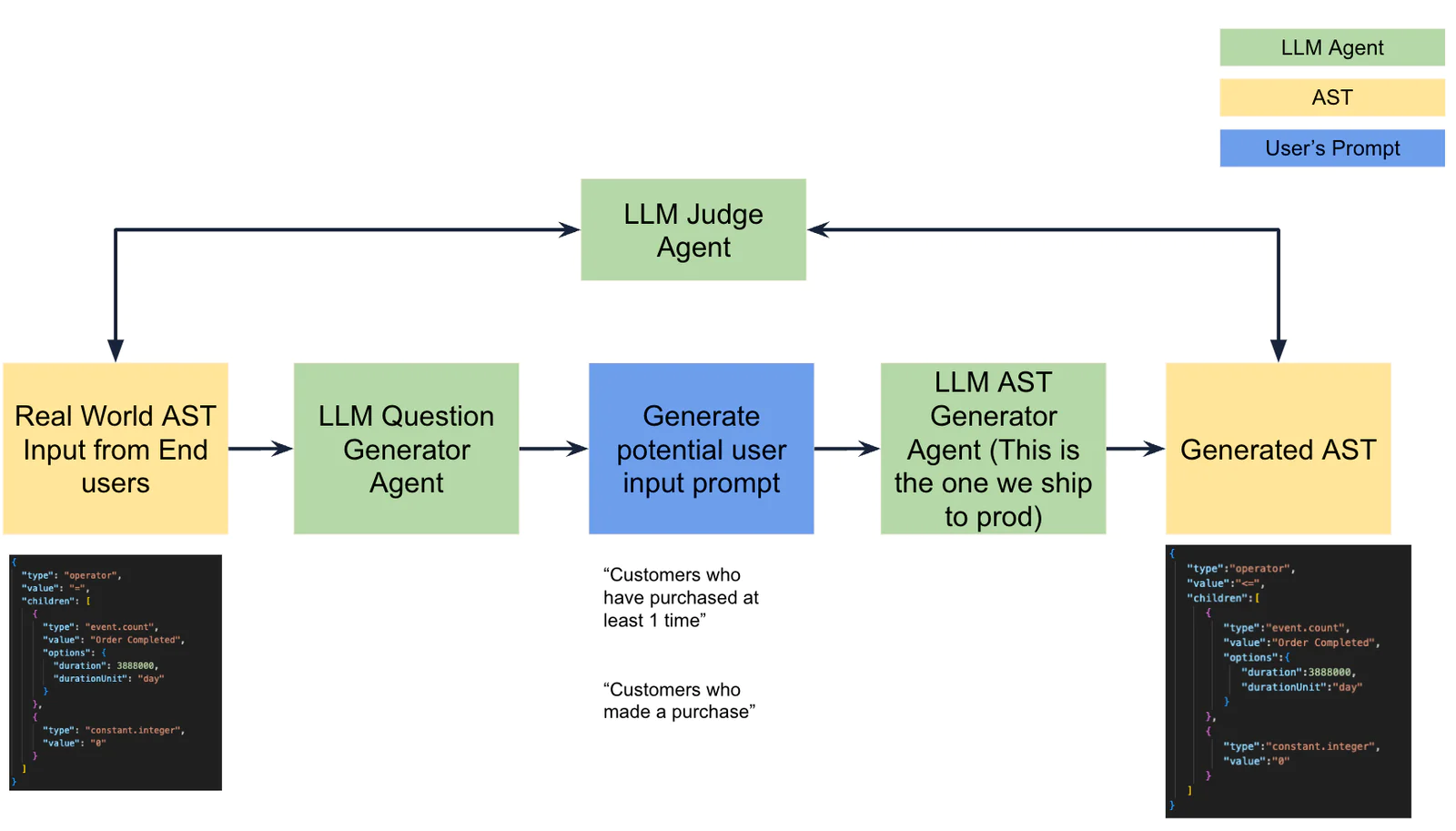
To provide a more in-depth understanding of the generative audience evaluation process, let's look at the steps involved.
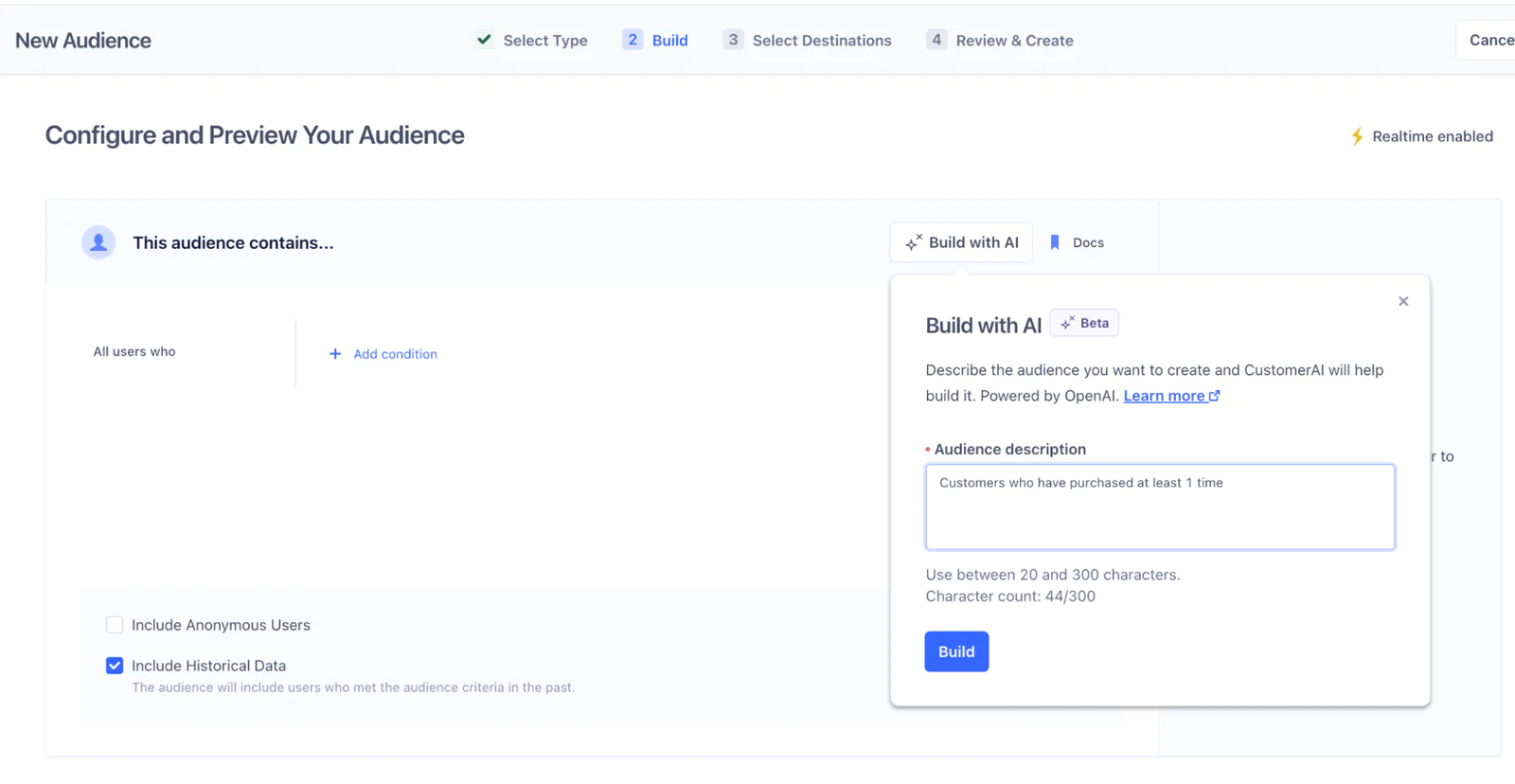
1. A user provides a prompt, such as "Customers who have purchased at least 1 time."
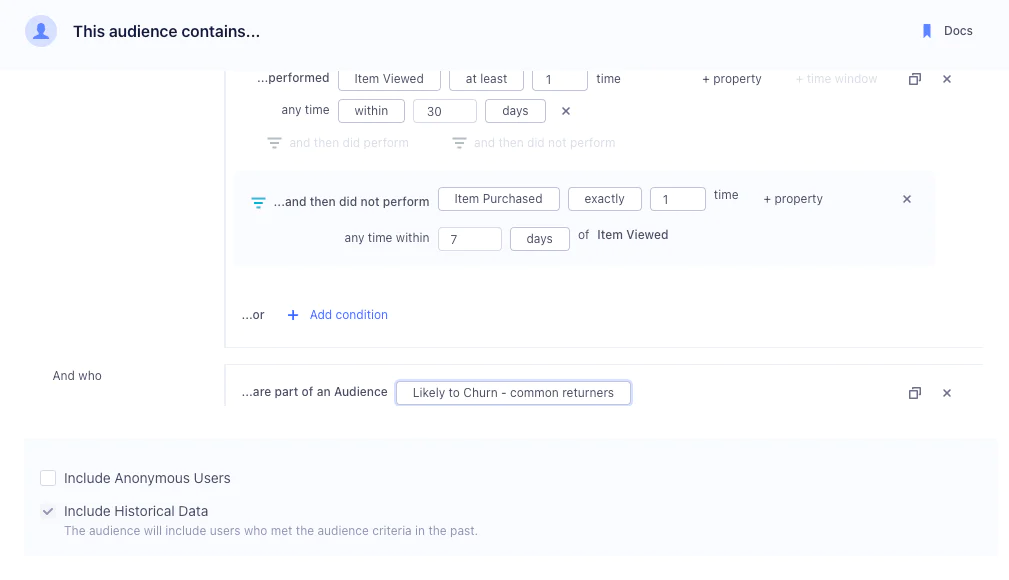
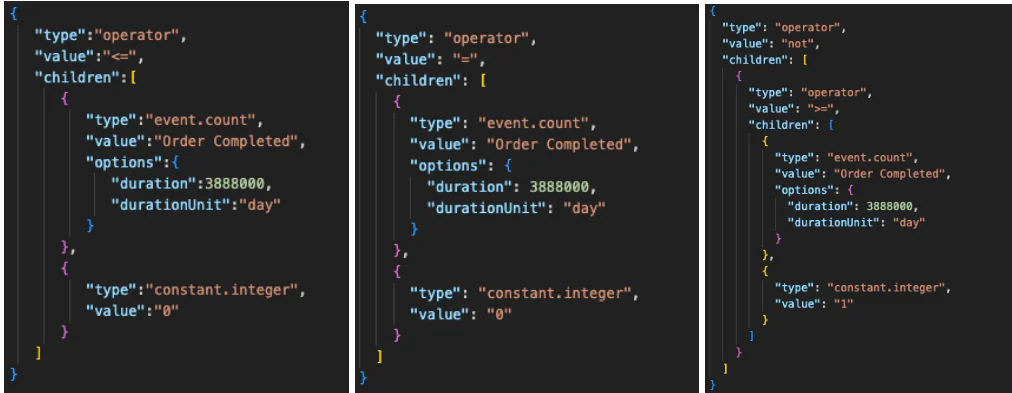
2. The prompt is converted into an AST, which is a tree-like data structure representing the code structure. In our case, the AST is similar to a JSON object.
3. We need to evaluate if the generated AST is robust enough to be shipped to production.
To accomplish this, we use the "ground truth" ASTs provided by customers as a reference for evaluation. However, there can be multiple valid ways to represent the same code structure, making it difficult to determine the best AST representation. This is where LLMs can play the role of a judge, helping us evaluate and improve the quality of generated code.
However, there are some challenges.
1. LLMs struggle with continuous scores. For example, if asking LLM to give a score from 0 to 100, LLM tends to only output discrete values such as 0 and 100. To address this, we ask the model to provide scores on a discrete 1-5 scale, with 1 being "very bad" and 5 being "perfect." This helps us obtain more interpretable results.
2. The LLM Judge also needs a Chain of Thought (CoT) to provide reasoning for the scores, which can improve the model's capability and facilitate human evaluation. Implementing CoT allows the model to explain its decisions, making it easier for engineers to understand and trust the evaluation process. By using CoT, the alignment with human increase from roughly 89% to 92%.
3. We adopt OpenAI’s GPT-4 model as the actual LLM Judge model. Surprisingly, we find that using other strong models such as Claude 3 Opus achieve similar scores with GPT-4, which shows that the alignment between different models and human.
LLMs have proven to be a powerful tool for evaluating and improving code generation in the context of Segment and Twilio engineering. By using LLMs as judge, we can enhance the quality of our generated code and provide better recommendations to our users. As we continue to refine our approach and explore new use cases, we expect LLMs to play an increasingly important role in our engineering efforts, leading to more efficient and effective solutions.