Alas! We have reached our destination. While there were a couple of performance related sevs along the journey, we did not encounter any security incidents. We achieved the perfect safety record by following the steps meticulously. At the end of the one-month mark, the legacy service was sunsetted and we headed out for a celebration!
Lessons we’ve learned during the migration
The temptation to refactor while rewriting the service
Many of us saw this migration as an opportunity to refactor and improve the legacy authZ service. There were some structural issues and bugs we were itching to address. At the same time, we were also tasked to deliver within a certain timeframe.
After much discussion, the team leaned toward minimal changes because we knew any differences could potentially lead to issues needing investigation. A direct rewrite from Go to TypeScript was the way to go. This maximized available time for stabilizing the new service to reduce possible vulnerabilities. The decision paid off big time since we were able to finish new service implementation quickly, leaving us plenty of time to debug differences between the new and old systems. Similar code flows in both versions of the authZ service also helped us quickly locate the root cause for the bugs. The end result was a successful migration with no serious security incidents!
Perplexing intermittent permission diffs that are not reproducible!
Replication lag between primary and secondary database instances
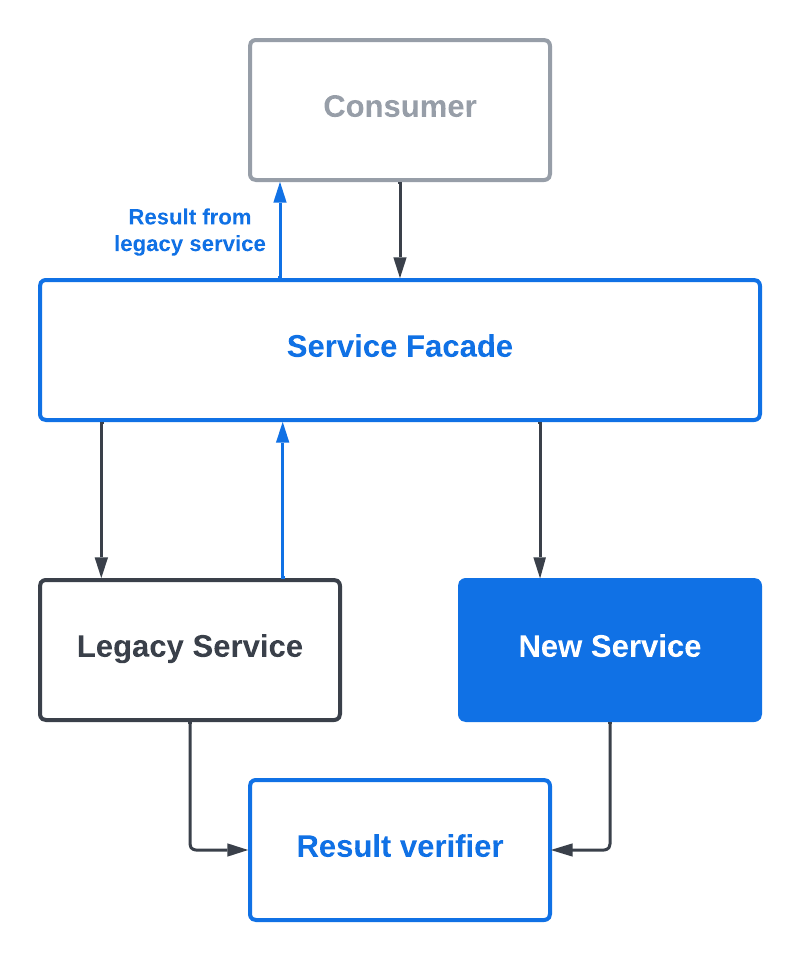
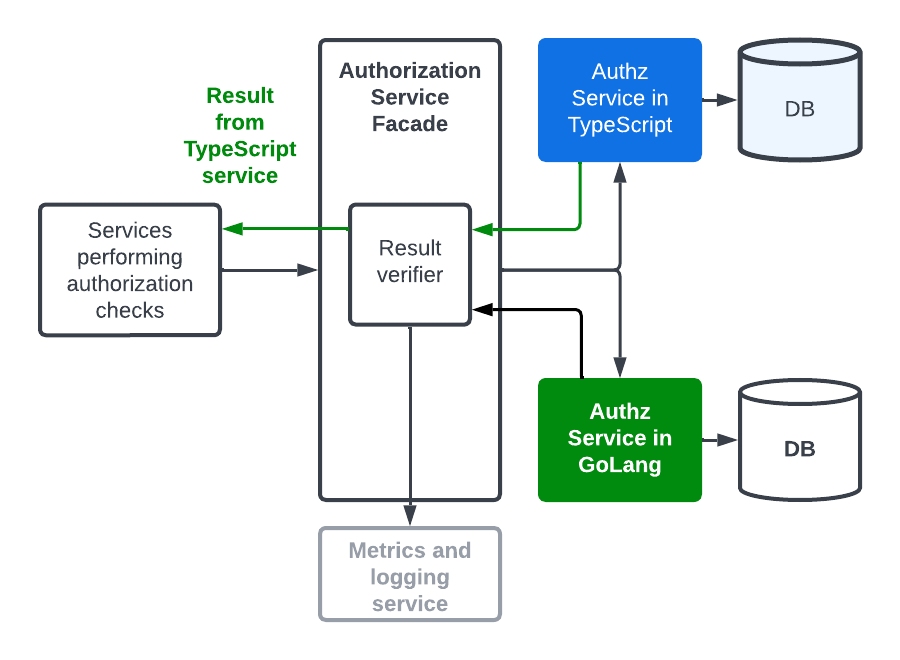
During the side-by-side comparison phase where the legacy service was still serving the responses, we started noticing failing tests and monitors whenever policies were updated. Permission differences would show up whenever policies were changed. And to make matters worse, we were not able to reproduce the differences when rerunning the permission check with the exact same set of parameters!
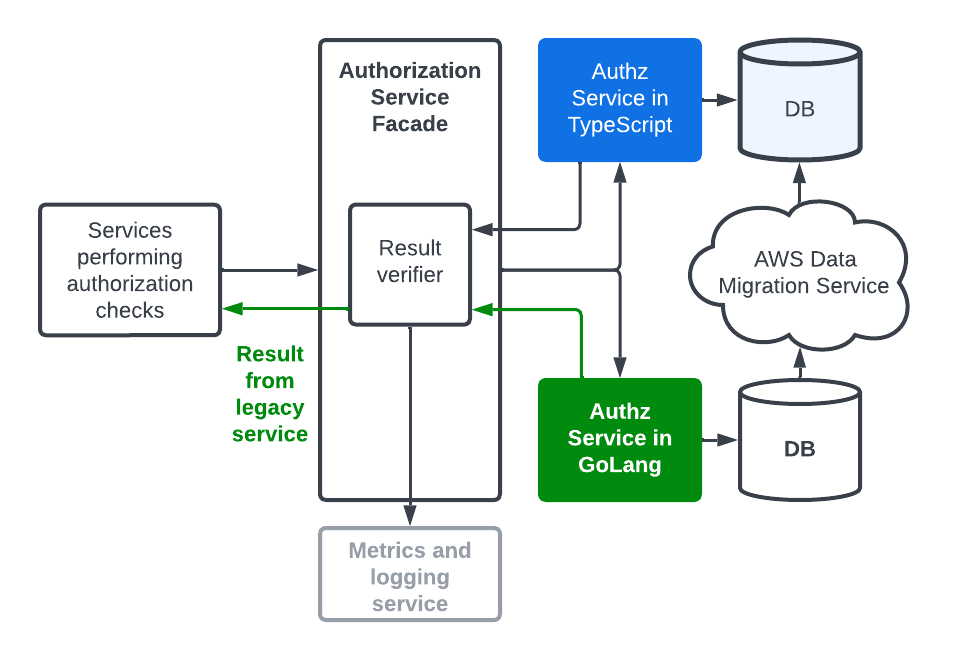
It took us a long time to figure out that database replication lag was the culprit. Prior to the migration, the legacy Authz service ran on a single database instance. Policy changes were reflected instantaneously in permission check results. The new service used a cluster of database instances to improve load balancing. The replication lag from the read/write primary to the read-only instances meant the policies were out-of-sync for a short period of time. If any permission checks were conducted during the time window, the results would be different.
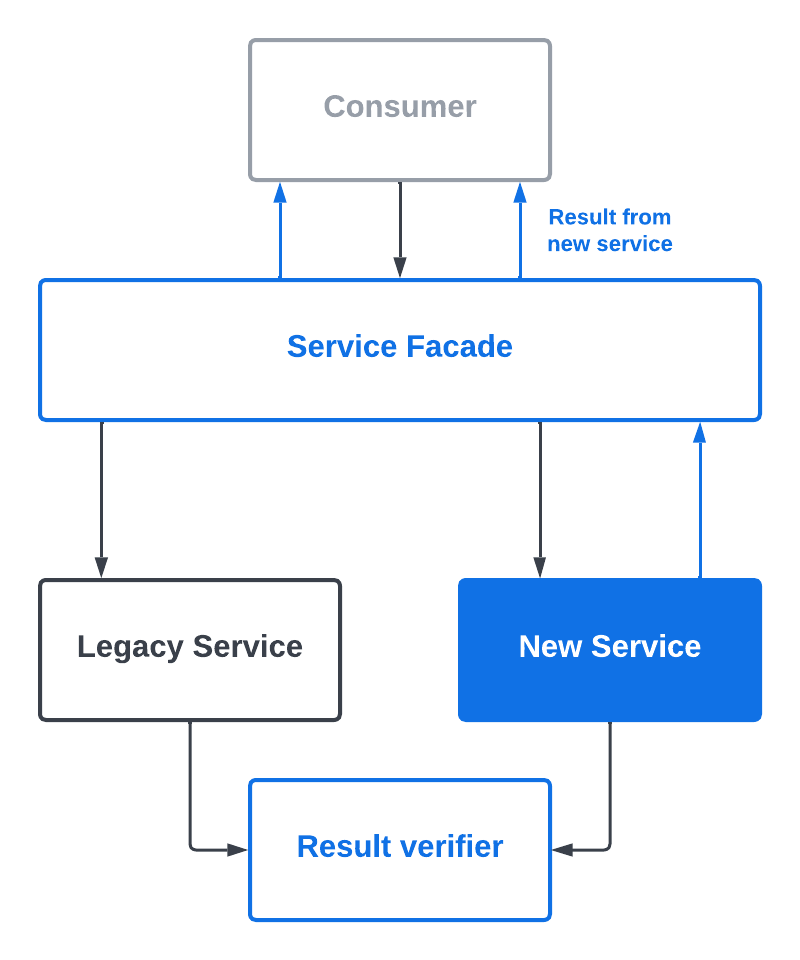
The problem presented a unique challenge for us. We had to find a balance between consistency and load-balancing. So we did a benchmark to gain visibility into the load for permission check on primary-only. To our pleasure, we found the load only resulted in a small single-digit percentage increase in cpu usage. Then the fix was easy: let’s always use the primary database instance for permission checks. This solution gave us immediate consistency while not impacting overall performance. Problem solved and everyone was happy!
Data sync delay caused by AWS Data Migration Service (DMS)
After switching to reading from primary, we saw a reduction in diffs. But! Diffs are still happening. Once again, we noticed the permission check diffs only occurred when updating policies. The cause this time lay with the AWS DMS. Because we relied on the legacy service to update policies, the data needed time to sync between the two databases. If a permission check is done prior to completing the synchronization, it would be different between two services.
To mitigate this delay, the team came up with an ingenious solution: a delayed retry!
We calculated the average time needed for synchronization to complete. Whenever a diff was encountered, the code would wait a bit longer than the average before checking again. If the second check had the same result as the old service, we knew the diff was caused by data replication delay and it would be considered as a non-issue.
With this additional logic, we eliminated a whole class of errors needing to be investigated. This saved a huge amount of time!
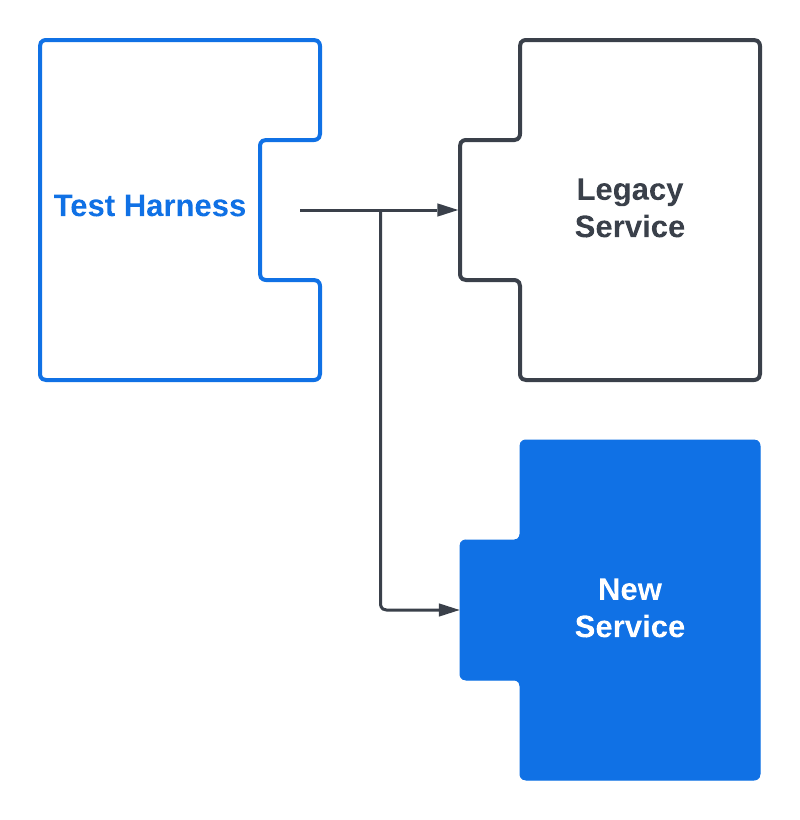
Test harness = peace of mind
Tests, tests, tests! Get them to cover as many scenarios as possible, and run them as early and as often possible in the CI/CD pipeline. These tests catch violations early and give you peace of mind when your changes reach production. We used them as the litmus test for reaching feature parity with the legacy service. Many months after finalizing the migration, the test harness we created during the first phase continues to guard against broken access control vulnerabilities.
With our authorization service fully migrated, we looked back and reviewed each of the goals we set out to achieve:
-
The new service is now sitting in an ecosystem in which the majority of developers are comfortable making changes.
-
Automated tests in all environments ensure access control integrity is checked continuously. Alarms will sound if any violation is detected.
-
Now we have the details of each permission check in the logs allowing for a quick response in the case of any access control issues.
To sum it up: mission accomplished!
We laid a solid foundation to enable future changes to the authorization service and we completed a critical milestone which allowed the Organizations project to become a reality.
Last but not the least, the migration would not have been possible without countless colleagues contributing to the effort. All the brilliant ideas and thoughtful planning are the sole reason for our success. It was a long journey and a big shoutout to everyone on the team for carrying the migration to completion.