How we automated ourselves out of on-call burnout… and you can too!
At Segment, we automated the traditionally time-consuming, repetitive response tasks time with an open-source tool for a more energy-saving future!
By Prima Virani
At Segment, we automated the traditionally time-consuming, repetitive response tasks time with an open-source tool for a more energy-saving future!
The repetitive nature of response tasks is the biggest cause of fatigue and burnout among Incident Responders. Anyone who’s been on-call on a Security team can remember how many hours they’ve spent opening the same tabs, clicking the same buttons, copy and pasting the same indicator data, and performing other similar tasks repeatedly. Imagine if that time was spent building stronger detection capabilities instead, or even better, on taking a break from the screen and going out for a walk!
While this issue can be solved by outsourcing the frontline response capabilities, it is costly in terms of time and money to identify a proficient vendor, obtain approvals, finalize the contract, and pay for the service...
What if I told you that at Segment, we built this capability with an open-source tool in the same amount of time it would take a team to do all of the above, with the time and resources of a single full-time security engineer? Welcome to the story of our Response Automation journey!
While selecting the tool, our goals were simple—we wanted something that let us automate repetitive checks and connect to various systems once an alert fired. We also looked for something that was cloud-native and could be managed as code.
SOCless was our tool of choice here as it ticked all of those boxes. Because it's open source, it also allowed us a greater level of customizability and control in our internal implementation.
We thought about going down the commercial tool route, but quickly realized that unlike the SIEM or Endpoint Detection spaces, the Security Orchestration and Automation Response (SOAR) space did not yet have any industry-standard commercial tools. Even though there were a few tools available, most were either a spin on SIEM or a case management tool, which was not what we wanted.
SOCless’ high-level concept is simple and elegant. It was created by software engineers at Twilio (see the Github repo here!) and is AWS-native. Every automated task is a Lambda and the Lambdas are tied together to form steps of a playbook in an AWS Step Function. For example, the playbook below is for investigating a suspicious SHA-256 hash. The playbook is a “State Machine” inside a Step Function and every step represents a Lambda function.
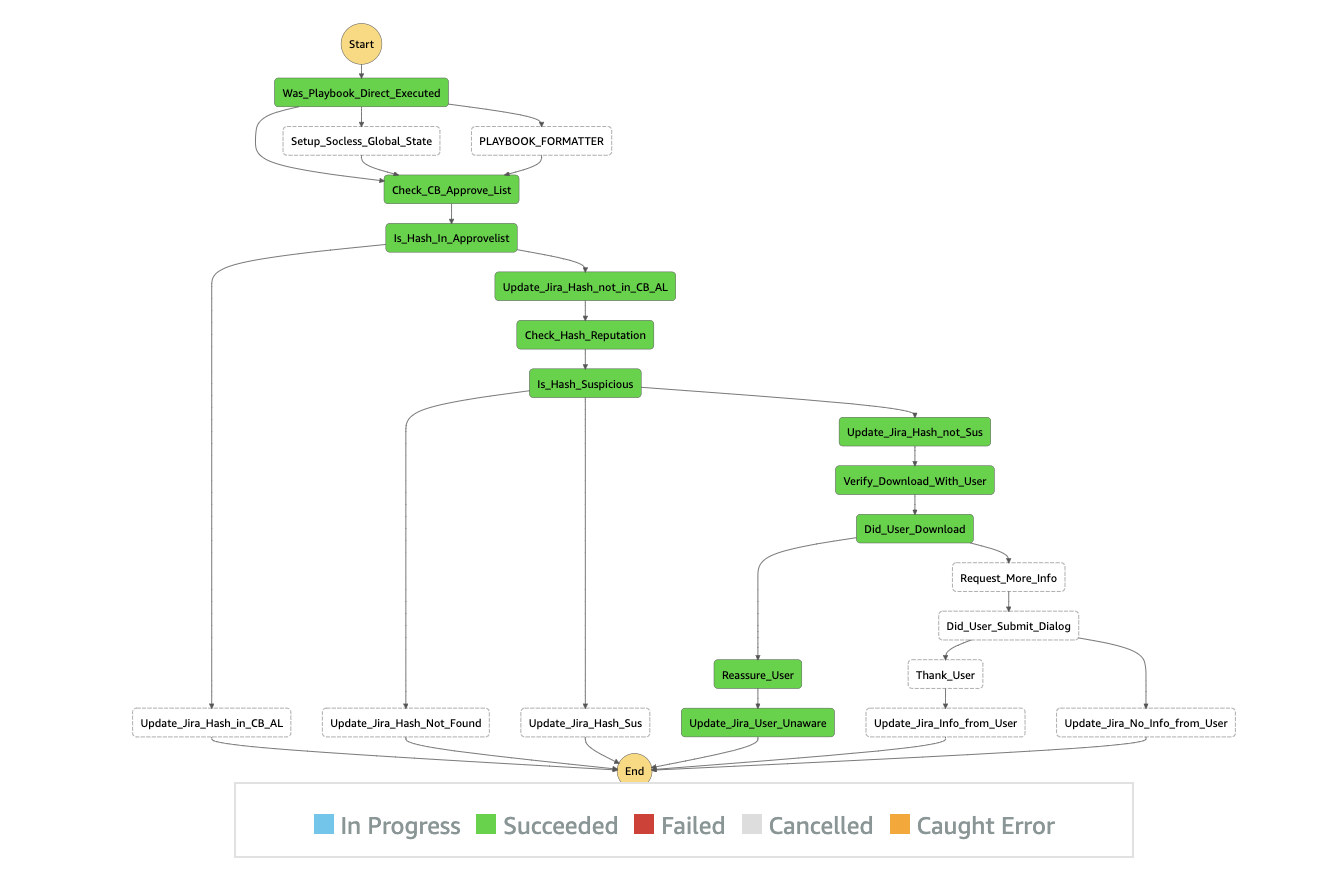
As you can see in the diagram, there are many steps starting with “Update_Jira…” Every one of those steps invokes the same Lambda function with different comments, which makes every Lambda function reusable. It can be invoked as many times as needed inside the same playbook and across other playbooks.
The tool is created using the “Serverless Framework” and it can be deployed from a local machine with “npm”. The playbook triggers received by the AWS API Gateway with an endpoint Lambda attached to it, which passes the trigger data on to another Lambda, which kicks off the appropriate playbook inside the Step Functions. However, there are many considerations and modifications that went into our internal implementation.
Read on to learn about some of them.
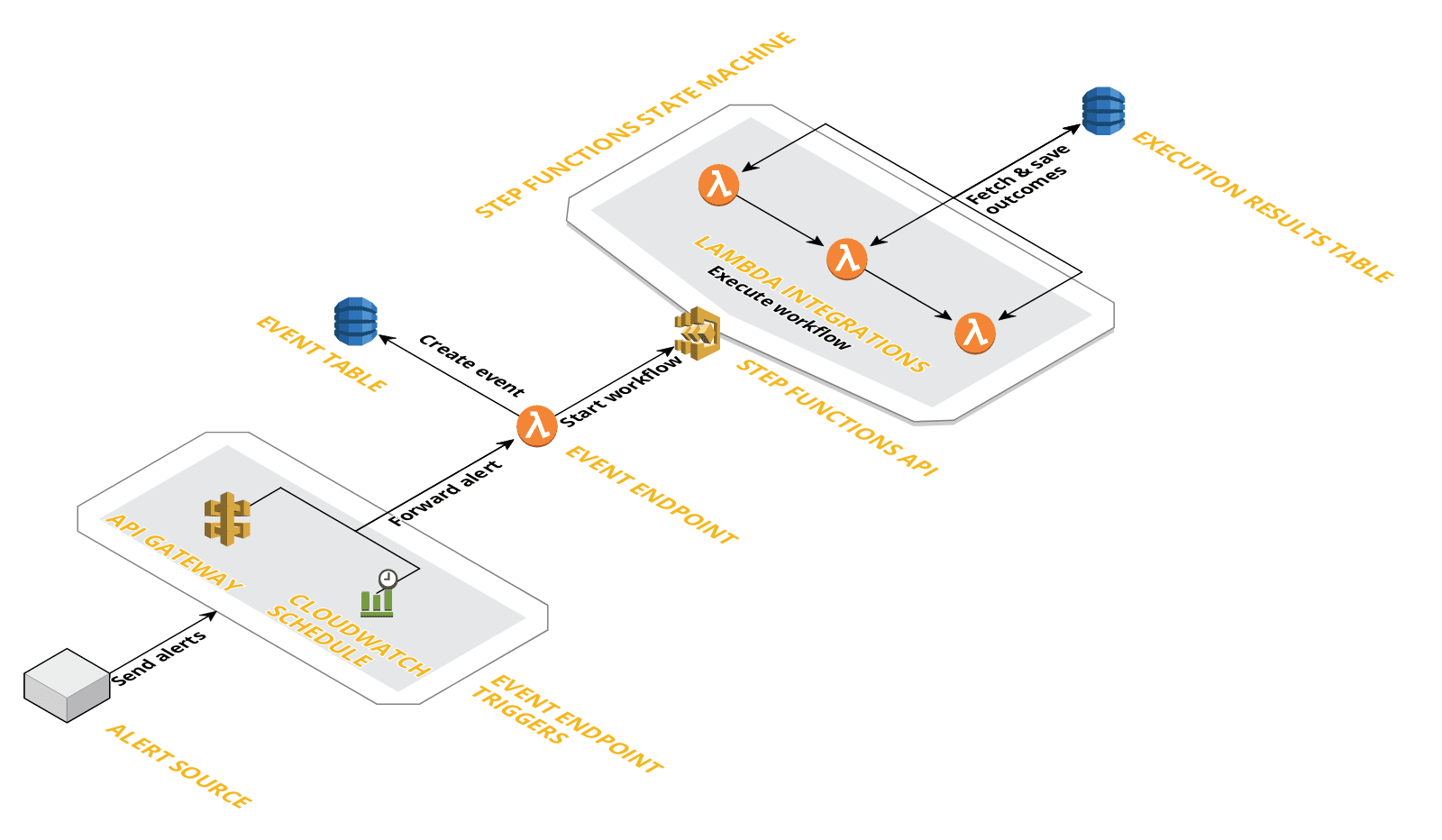
No tool—open-source or commercial—could be implemented and used in production without production readiness and implementation discussions. In addition to those discussions, we also customized the tool to make other improvements.
Dev, Stage and Prod environment segregation
SOCless was designed to use four different regions of a single AWS account to segregate Dev, Stage, and Prod environments. In our implementation, we chose to use three separate accounts for the Dev, Stage, and Prod implementations to ensure better access control.
Playbook error monitoring and alerting using Datadog+Slack
We built visibility into Lambda failures in the Dev, Stage, and Prod environments with Datadog. To ensure we could accurately monitor all the SOCless Lambdas with a single monitor and a simple one-line logic, all Lambda and Step Function names began with socless, so it was easy to monitor them for errors. We received a message posted to a dedicated channel on Slack whenever a Lambda or Step Function entered the error state.
CI/CD
We configured our CI/CD such that every pull request made on the SOCless repo was built and auto-deployed to the Stage environment. Successful deployment to Stage and at least one peer approval were required to merge to the default branch. Once these requirements were met, the branch was auto-deployed to the Production environment.
Thanks to our wonderful Access Service system, we could ensure that no user had read or write permissions to the SOCless AWS Accounts (Stage and Prod) without explicit permission and that access was restricted to only the administrators of the service.
Custom API gateway URL protected behind API token
When a new API was created on the API Gateway, AWS created a URL with random characters in order to access it. For example, https://cbacba123d.execute-api.ap-east-2.amazonaws.com/stage. However, it became tricky to route to it if you had a service in another account (let’s say account 7654321) that tried to reach the URL. AWS started to think of it as an internal URL inside account 7654321 instead of the SOCless account and failed to reach it.
A custom API Gateway URL (for example, responseautomation.example.com) was an easy way to prevent that from occurring.
For an additional layer of security, we protected the Gateway behind API Key based authentication in our internal implementation. We highly recommend this for everyone who uses a similar implementation.
New default Lambda role
The default role that SOCless came with was created and managed by the Serverless Framework and the permissions were very broad, which didn’t work for Segment. To remedy this, we tightened the permissions around the Lambdas and created a new default role with minimal access policies which all our Lambdas now run with.
This role and its policies are now created and managed with Terraform (vs. Serverless Framework). Not only is this Segment's standard method for managing internal IAM permissions, but it makes our Cloud Security Team happier as well!
Secret handling
SOCless was designed to load secrets from the Parameter Store into the Environment Variables, which were applied to all the Lambdas. However, we modified it to access the specific parameters from the Parameter Store directly with the Python library, Boto3. This helped us run the Lambdas with the least privilege by preventing Lambas written for one service from accessing the keys of another Lambda.
Lambda log retention duration
Default setup retained the Lambda error logs indefinitely at that time. We set a log retention period on all of our Lambdas to be 30 days because the Cloudwatch logs were meant to be an indicator of errors. This helped us keep the attack surface narrow and the costs low.
All the steps taken to make the system production ready helped us ensure that multiple team members could contribute toward the automation efforts simultaneously without overwriting another teammate’s work, and also ensured quality control with peer review. This helped us move quickly once the focus of the project shifted to writing the Lambdas for the run-books and converting them to SOCless playbooks.
We sorted our alerts by the frequency of triggers and automated the most frequent alerts first for maximum impact. In the first automation cycle, we focused on partially covering as many alerts as possible, instead of an entirely animated single playbook. A dozen partially automated playbooks were more valuable than two or three fully automated playbooks. This is because usually the complicated and difficult-to-automate steps were later in the playbook. In many cases the automation could close out a response before the manual steps were even reached. We kept track of steps that continued to require manual processes with the intention to revisit these later when we had more time.
We also acknowledged that there were many parts of a response procedure that may not be automatable (not yet, at least!) or not worth the time spent automating at that time.
As with anything, no approach was a silver bullet. In this case, simply automating the manual steps was not enough. It was equally important to communicate the outcomes of every step in the right place where other engineers could easily observe what had been done already and what remained to be done.
In light of that, we highly recommend logging the outcome of every step in your ticket management tool (Jira, Zendesk, etc.) so that response engineers have as much detail as possible about the steps that have been completed automatically and their outcomes.
Another benefit of logging the outcomes at every step is that if the playbook encounters an error or exits abruptly at any point, responders have the data from all steps successfully completed before they encountered the error. Last but not least, it’s important to remember that the playbooks are only as good as the response plans the automations are modeled after.
In about six months we’ve partially or fully automated approximately 85% of our playbooks. The ease and velocity of playbook creation increased with every playbook because with every new playbook we created, the number of new Lambdas we needed to create decreased significantly.
For example, if our first playbook involved a step that required us to send a message to a user on Slack, we would have to create a Lambda. This Lambda is now available for all future playbooks.
As we automated more playbooks, the chances of using an existing Lambda function increased. As a result, our mean time to resolve has gone down by almost 30% and most importantly, our responder experience has improved dramatically. We would like to acknowledge and thank the creators of this tool at Twilio for making it open source and available to all of us in the industry!
SOCless - created and open source by Twilio Security Engineering Org

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.