Building an internal search engine at Twilio Segment
We created a unified search engine for our technical teams, which improved developer productivity.
By Benjamin Yolken
We created a unified search engine for our technical teams, which improved developer productivity.
At Segment, our technical teams write a lot of internal documentation. Among other examples, we create system runbooks, technical design docs, product requirement docs, how-to guides for internal systems and workflows, and miscellaneous team and meeting notes. While some of this material is written once and then quickly forgotten, a significant fraction is consulted frequently and thus is critical for the smooth operation of our company.
Initially, all of this essential internal documentation lived in Dropbox Paper, which meant that employees could just use the latter product’s search UI to find things. Over time, however, some material drifted out of Paper and into systems like GitHub, Confluence, and Segment’s public documentation.
This document dispersion meant that users now had to run multiple searches in multiple places to be sure that they were getting the most complete, up-to-date answers to their queries. This was not only tedious, but also meant that important documentation was often hard to find. The end result was reduced productivity and, on the flip side of the coin, reduced incentives to create and update documentation; after all, if no one can find what you’re writing up, then what’s the point of devoting a lot of effort to it?
To address these issues, we decided to create a unified search engine for Segment’s technical teams, i.e. an internal “Google for Segment.” The goal of this project was to make it fast and easy to find internal documentation on a particular subject, no matter which “corpus” the material lived in.
In the remainder of this post, we describe how we approached designing and building this system, and what the final result looks like.
The technical core of any search engine is the backend system that indexes the documents and responds to queries with a ranked list of results. There are many, many choices here, ranging from fairly low-level, open-source systems like Elasticsearch to higher-level, hosted commercial offerings like those by Algolia and Coveo.
Although the number of choices initially seemed daunting, we had a number of requirements that quickly reduced the options. First, we wanted to stick to an “on-premises” solution that could run in one of our AWS accounts. Although it might have been possible to get security and legal approval to send our documents off to a third-party provider, this would have significantly delayed the rollout of the project and introduced additional administrative overhead.
Second, we wanted a low-level solution that provided APIs but would allow us to build our own crawlers and UIs around the former. Many solutions in this space focus on creating “knowledge bases” with their own UIs, creation workflows, and documentation management tools; this would be overkill for us because we either had these components already or wanted to build them ourselves.
In the end, the top two contenders were Elasticsearch and AWS Kendra. We ultimately chose the second because it offered a slightly easier out-of-the-box experience; among other examples, Kendra’s default boosting rules work pretty well, so only minimal tweaking is needed to get reasonable search results. Kendra’s support for “suggested answers” and adjusting rankings based on user feedback were plusses too, although they weren’t critical for us.
The two services have similar base APIs (e.g., send a query, get a ranked list of results), so the choice didn’t affect the rest of our architecture that much. In the future, we could switch to Elasticsearch or something else, but we’ve been pretty happy with Kendra so far.
Once we chose a backend, the next step was to get our documents into Kendra so they could be indexed by the latter system.
Kendra includes a number of “connectors” that automatically crawl and index third-party sources. However, these were missing for several of the key sources we wanted to index, including Dropbox Paper and GitHub. Some of our other sources, like Confluence or the public Segment docs, were nominally compatible with one or more pre-built connectors, but in each case we found that these were missing the level of customization we wanted.
In the end, therefore, we just decided to write our own tools to scan our sources, extract the documents, and write them to S3. We could then use Kendra’s S3 connector (the most basic one) to get them into the index.
High-scale, general-purpose web crawling is a challenging technical problem. In our case, however, the corpuses we’re scanning are fairly small (well under 100k documents), so we could use the following, simplified algorithm:
Start with some “seed” URLs from the corpus, and put them into a queue.
While the queue is non-empty:
Take the first element off the queue
Fetch the associated document and save its contents and metadata in S3
Parse the document, extract all the links
For each link that hasn’t been seen before, add it to the queue
We implemented this procedure in golang for each source (e.g., Dropbox, Confluence, GitHub, etc.), calling the appropriate, source-specific APIs for the “fetch” steps. The “seeds” were either hard-coded or generated by searching the source for particular terms or root folders.
The contents and metadata of each document are encoded in a simple JSON format. The following is an example:
We then wrote a separate tool, the “document loader” to convert these JSON blobs into the format required by Kendra so they could be read from S3 and added to the index.
The last big technical chunk of the project was building a frontend for users to interact with the system. This required two subsystems, described in more detail below.
First, we created a small HTTP server in golang that would serve as the “backend of the frontend.” This server would be a translation layer between the clients (i.e., browsers) and the underlying Kendra search APIs; it was also needed to host our static content.
Second, we needed to create the search UI that would be rendered in user browsers. For this, we used a combination of Next.js, TypeScript, and Segment’s Evergreen UI component library. This stack was already used for a number of other UIs at Segment, so it was the easiest way to bootstrap our app and get help from others on the team when we needed it.
After much trial-and-error (we’re a little rusty on frontend development!), we created a Google-inspired search UI for our indexed content. We decided to call the app “Waldo” as an oblique reference to the children’s book series:
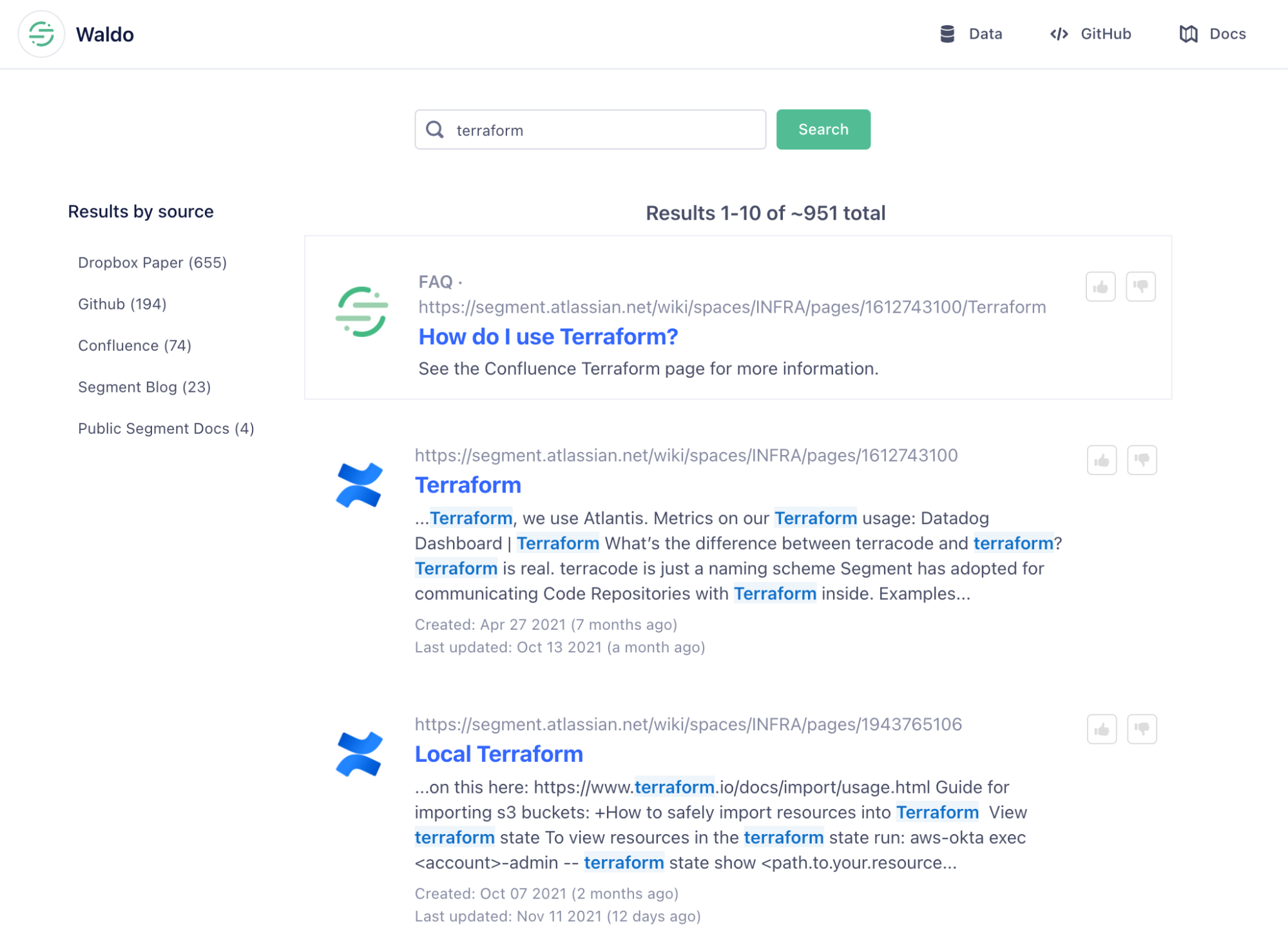
Note that the UI takes advantage of several Kendra features including faceting (in this case just by the source), hand-curated “FAQ” results, and the ability to provide feedback on individual documents.
With all of the core components developed, we just needed to productionize our setup and connect the pieces. Our final architecture was the following:
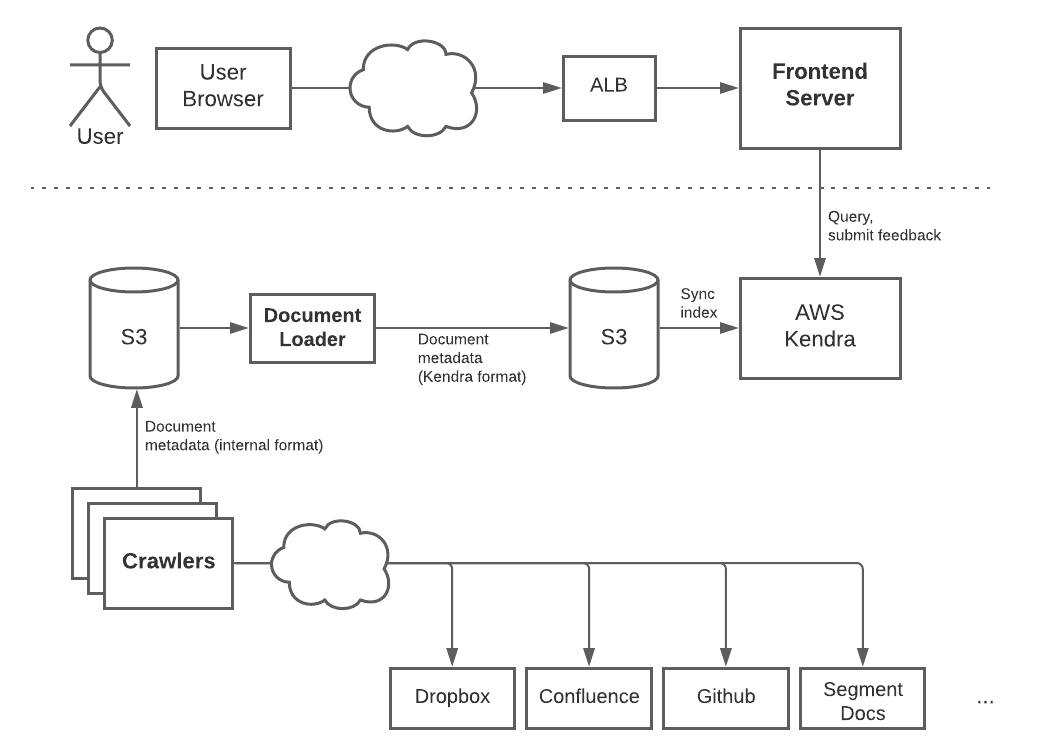
For the frontend flow, user requests go through an ALB to our HTTP server, which then forwards query requests to Kendra. The server instances run in EKS, Amazon’s hosted Kubernetes service.
On the backend, we use Argo Workflows in EKS to kick off the data pipeline each night and coordinate the resulting crawling and loading steps. As described previously, this pipeline generates files in S3, which are then scanned and indexed by Kendra.
We were able to build an internal search engine for Segment using a small number of low-level, off-the-shelf components. The end result has made it faster and easier to find technical documentation across our various internal sources including Dropbox Paper, Confluence, and GitHub.
At both Segment and our previous employers, we’ve found that adding internal search is a great way to improve developer productivity and motivate people to create better documentation. The Kendra-based solution described here works well for us, but depending on your organization’s needs, a higher-level commercial offering might be easier to set up and maintain. Be sure to check out the various solutions in this space before building your own.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.