What is a Data Pipeline? + How Do They Work
A data pipeline comprises the tools and processes that move data from source to destination. Here’s how to build one.
By Geoffrey Keating
A data pipeline comprises the tools and processes that move data from source to destination. Here’s how to build one.
In data science, the term data pipeline is used to describe the journey that data takes from the moment it is generated. The expression evokes the image of water flowing freely through a pipe, and while it’s a useful metaphor, it’s deceptively simple.
In reality, many things can happen as the water moves from source to destination. It could be cleaned, enriched, or mixed with other sources. It could also leak out.
The same could be said of data pipelines—the way you design them directly affects what you can do with the data that your organization collects. A well-designed, robust, and secure pipeline can help you extract valuable business insights from data.
To help you get started on building a data pipeline, we’ll walk through:
What is a data pipeline?
How do data pipelines work? 3 key components
Key tools and infrastructure of data pipelines
How to build a data pipeline in 5 steps
Create the most efficient, accurate, and reliable data pipeline with Segment
FAQs on data pipelines
A data pipeline is a system of tools and processes that lets data travel from point A (source) to point B (destination). Along the way, data is cleaned, classified, filtered, validated, and transformed. There’s a pipeline in action whenever you extract data from apps and devices and store it in a data management system or load it into an analytics tool.
By creating a pipeline, you’re separating your data collection and data analysis systems, which helps make the computing workloads more manageable. Having a pipeline also makes it easier for you to restrict access to either system. For example, you might want to grant a business intelligence consultant access to data only once it’s been categorized, anonymized, and validated.
When purchasing or designing components for your data pipeline, keep in mind the business goals and use cases that drive your company’s need for data in the first place. The more complex your use case, the more tools you will need.
Consider these three key components that make a data pipeline work.
Any business system that generates digital data can become a source for your pipeline.
Examples include:
Data repositories like databases, spreadsheets, or customer relationship management (CRM) software
Your website, social media pages, advertising channels, eCommerce store, mobile app, payment platform
Internet of Things (IoT) devices, equipment sensors, Software-as-a-Service (SaaS) platforms
Raw data may be transmitted and processed either through batch processing or stream processing.
In a batch processing pipeline, data is transmitted periodically in batches. This is ideal for simple and small-scale use cases.
Examples:
Point-of-sale (POS) system data is transmitted to a data warehouse once every 24 hours.
On a factory floor, production software is updated at the end of a shift to reflect the total number of products assembled.
In a stream processing pipeline, data is transmitted in real time. Complex use cases, big-data operations, and AI-driven systems require this type of pipeline as they need to continuously make calculations based on the most recent data.
Examples:
Data from POS, smart shelves, an eCommerce website, and a shopping app are transmitted in real time to a data warehouse for the purpose of tracking and updating inventory
Data from IoT sensors in a smart factory are processed as soon as they’re generated and fed to an analytics dashboard that monitors production levels and equipment usage and flags bottlenecks and downtimes
As it moves through the pipeline, data may remain raw, its properties unchanged. But it may also be transformed to meet regulations and formatting requirements, as well as evaluated to remove inaccuracies.
No matter how meticulously you design your data pipeline architecture, you’ll run into problems once in a while. A built-in monitoring and validation component will help maintain the integrity of your infrastructure even when certain steps or tools in your workflow break down. (More on this later!)
Aside from the components mentioned above, you’ll need some basic tools and infrastructure to create a data pipeline, such as:
Data warehouse: A central repository of historical data from multiple sources. Here, data may be semi-structured or structured, similar to a relational database. A data warehouse may be deployed on-premises or on the cloud.
Data lake: Storage for raw, unstructured data, including real-time data. This is useful if you’re not sure what to do with data or how you want to classify it. As data lakes are often used for big-data use cases, they are hosted on the cloud.
Customer Data Platform (CDP): A CDP combines data from multiple sources to create a centralized customer database that can be accessed and used by other software and systems. It can perform data transformation, monitoring, and validation. By enabling different teams to access data, CDPs can break down data silos—so, for example, production teams can see sales data and adjust their supply-and-demand planning accordingly.
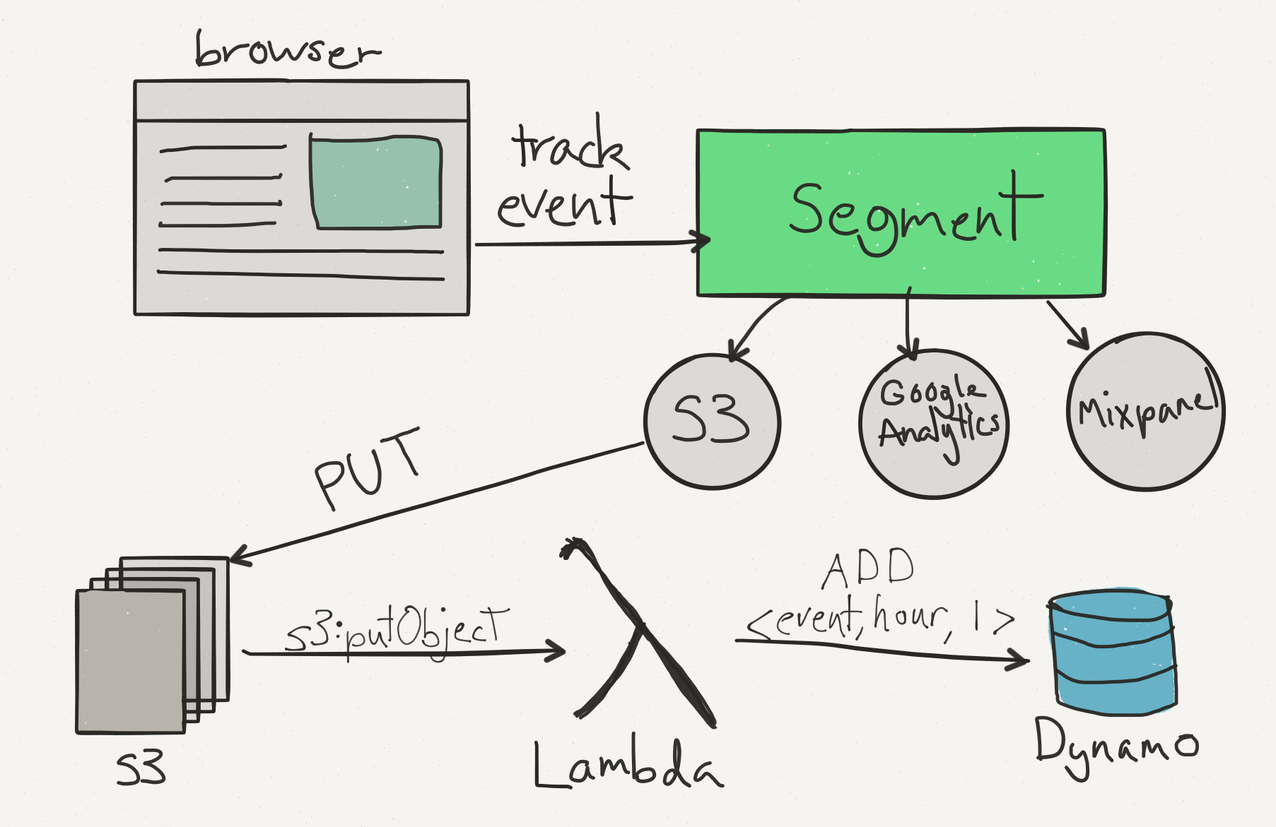
Example of where a CDP (like Segment) fits in a data pipeline
Once you map the key components to your data use cases, you’ll have an idea of the tools and infrastructure you need to build your pipeline. Ideally, you’ll talk to all teams in your organization to identify the data sources that they use, as well as the kinds of business insights they need. Such information will also help you build your case to the finance department once you identify vendors and propose a budget.
It also helps to discuss with data engineers and developers to determine if you need to build some components in-house or if you can work with customizable, off-the-shelf products. For instance, do you need to develop an intelligent monitoring system from scratch, or is there an automation tool that can meet your requirements?
At Segment, we believe that clean data starts with the collection process. If you find dirty data flowing through your pipeline, chances are high that your data collection and governance strategy are weak.
Strengthen your strategy by:
Creating a data tracking plan, which includes identifying the user traits and events that are relevant to your business goals
Establishing data collection best practices, such as standards for naming your data events and properties
Implementing controls to help you comply with privacy laws and industry-specific data governance standards
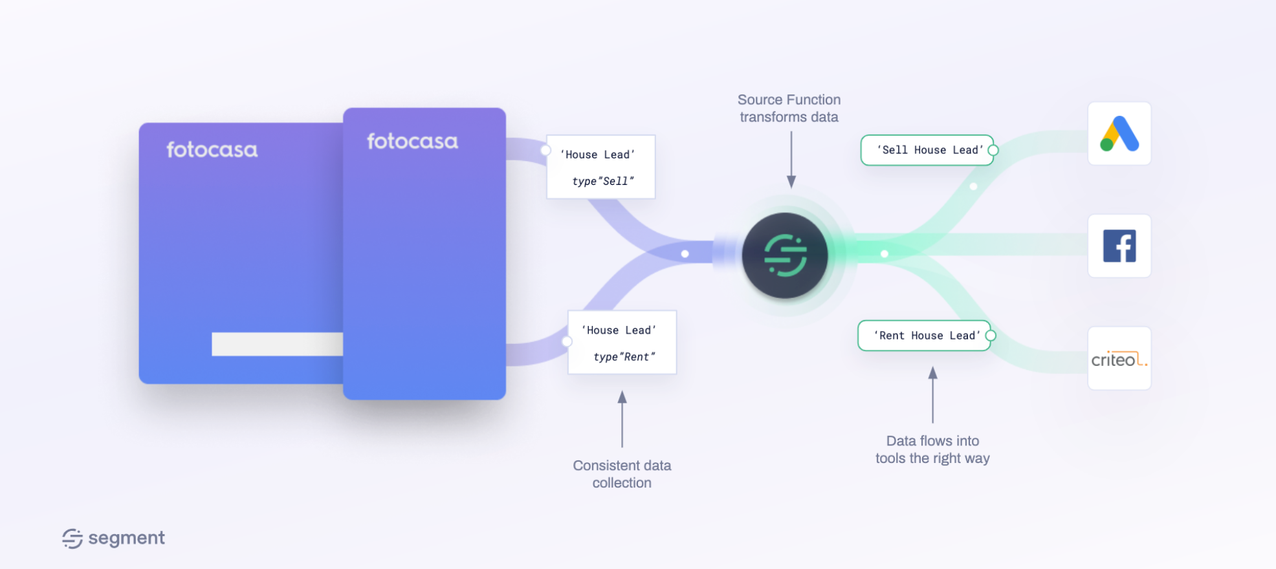
How Fotocasa uses Segment to ensure data quality and improve ad campaigns
One common problem with poorly designed or maintained pipelines is that they allow inconsistent, incomplete, and inaccurate data to pass through.
Prevent this from happening by building the following capabilities into your pipeline:
Filter out irrelevant and unnecessary data
Mask identifiers to protect user privacy and comply with privacy laws
Remove duplicates, errors, and blanks
Put together data from various sources
Change the data schema to match its destination’s required format
These steps can either be automated or achieved with just a few clicks using a CDP.
A CDP may also have identity resolution capabilities that integrate data collected from different sources to create unified customer profiles. This function is driven by machine learning rather than being a manual process. It’s useful for eliminating silos, as two disparate data sets might, in fact, pertain to one and the same customer.
Even the most meticulously designed machine needs maintenance, and the same can be said of data pipelines. A pipeline that functions perfectly today might let dirty data slip through the cracks tomorrow.
For example, you might collect data that is invalid or incomplete. The data schema or format you created last year may be outdated because your business has grown, and you now have more data to collect, or the types of data you need have changed. A source might change the schemas it uses, or a new analytics suite might require an entirely different way of structuring the data. Also, your filters might not be compliant with the latest data privacy laws.
With so much data flowing through your pipeline, your best move would be to automate the monitoring process. One way to do this is by uploading your tracking plan to your CDP so it can validate your expected events (those identified in the plan) with the live events that enter the pipeline. The CDP will flag non-conforming events as violations. Once you receive alerts, you can manually review and approve, remove, or change the data in question.
You can also schedule manual audits of some pipeline components. For example, conduct a yearly assessment of your tracking plan to see whether it still meets your business goals and data use cases, and update it if necessary.
Once you’re sure that your data is clean, complete, and compliant, you can migrate it to the destination, such as a data warehouse, where it can be accessed by different business applications and analytics tools.
Different destinations may have different data formatting requirements—but if you did steps 3 (transformation) and 4 (validation) right, this stage should flow smoothly.
All data pipelines are not created equal. Some leak or allow impurities to pass through. On the other hand, well-designed pipelines promote the accuracy and reliability of data.
Designing a pipeline that meets your requirements and standards for data integrity is difficult. The good news is you don’t have to build everything from scratch. You can use developer tools and customizable building blocks like CDPs, which let you standardize data collection and validation to ensure only clean data flows through.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.
A stream of live real-time eCommerce data sent to an analytics tool to inform a dynamic pricing strategy.
The two types of data pipelines are batch processing pipeline and stream processing pipeline.
Data warehouses, data lakes, and Customer Data Platforms (CDPs) are key tools in a data pipeline.