Topicctl - an easier way to manage Kafka topics
Today, we're releasing Topicctl, a tool for easy, declarative management of Kafka topics. Here's why
By Benjamin Yolken
Today, we're releasing Topicctl, a tool for easy, declarative management of Kafka topics. Here's why
Today, we're releasing Topicctl, a tool for easy, declarative management of Kafka topics. Here's why.
Apache Kafka is a core component of Segment’s infrastructure. Every event that hits the Segment API goes through multiple Kafka topics as it’s processed in our core data pipeline (check out this article for more technical details). At peak times, our largest cluster handles over 3 million messages per second.

While Kafka is great at efficiently handling large request loads, configuring and managing clusters can be tedious. This is particularly true for topics, which are the core structures used to group and order messages in a Kafka cluster.
The standard interfaces around creating and updating topics aren’t super user-friendly and require a thorough understanding of Kafka’s internals. If you’re not careful, it’s fairly easy to make accidental changes that degrade performance or, in the worst case, cause data loss.
These issues aren’t a problem for Kafka experts dealing with a small number of fairly static topics. At Segment, however, we have hundreds of topics across our clusters, and they’re used by dozens of engineering teams. Moreover, the topics themselves are fairly dynamic. New ones are commonly added and existing ones are frequently adjusted to handle load changes, new product features, or production incidents.
Previously, most of this complexity was handled by our SRE team. Engineers who wanted to create a new topic or update an existing one would file a ticket in Jira. An SRE team member would then read through the ticket, manually look at the actual cluster state, figure out the set of commands to run to make the desired changes, and then run these in production.
From the requester’s perspective, the process was a black box. If there were any later problems, the SRE team would again have to get involved to debug the issues and update the cluster configuration. This system was tedious but generally worked.
However, we recently decided to change the layout of the partitions in our largest topics to reduce networking costs. Dealing with this rollout in addition to the usual stream of requests for topic-related changes, each of which would have to be handled manually, would be too much for our small SRE team to deal with.
We needed a better way to both apply bigger changes ourselves, while at the same time making it easier for others outside our team to manage their topics.
We decided to develop tooling and associated workflows that would make it easier and safer to manage topics. Our desired end-state had the following properties:
All configuration lives in git.
Topics are defined in a declarative, human-friendly format.
Changes are applied via a guided, idempotent process.
Most changes are self-service, even for people who aren’t Kafka experts.
It’s easy to understand the current state of a cluster.
Many of these were shaped by our experiences making AWS changes with Terraform and Kubernetes changes with kubectl. We wanted an equivalent to these for Kafka!
We developed a tool, topicctl, that addresses the above requirements for Kafka topic management. We recently open-sourced topicctl, and we’re happy to have others use it and work with us to make it better.
The project README has full details on how to configure and run the tool, so we won’t repeat them here. We would, however, like to cover some highlights.
As with kubectl, resources are configured in YAML, and changes are made via an apply process. Each apply run compares the state of a topic in the cluster to the desired state in the config. If the two are the same, nothing happens. If there are any differences, topicctl shows them to the user for review, gets approval, and then applies them in the appropriate way:
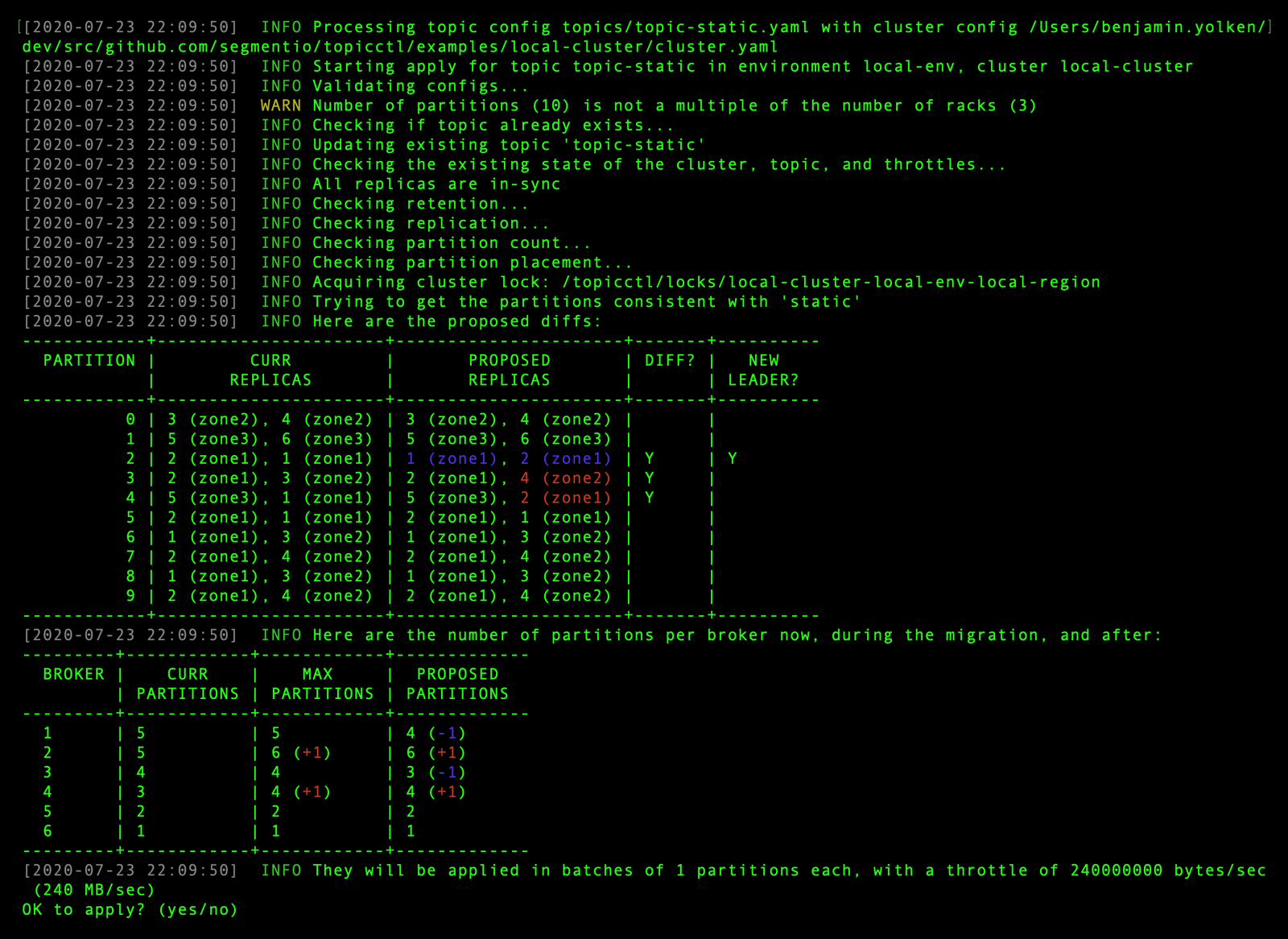
Currently, our topic configs include the following properties:
Topic name
Number of partitions
Replication factor
Retention time and other, config-level settings
Replica placement strategy
The last property is the most complex and was a big motivation for the project.
The tool supports static placements as well as strategies that balance leader racks and/or ensure all of the replicas for a partition are in the same rack. We’re actively using these strategies at Segment to improve performance and reduce our networking costs.
In addition to orchestrating topic changes, topicctl also makes it easier to understand the current state of topics, brokers, consumer groups, messages, and other entities in a cluster. Based on user feedback, and after evaluating gaps in existing Kafka tooling, we decided that a repl would be a useful interface to provide.
We used the c-bata/go-prompt library and other components to create an easy, visually appealing way to explore inside a Kafka cluster:
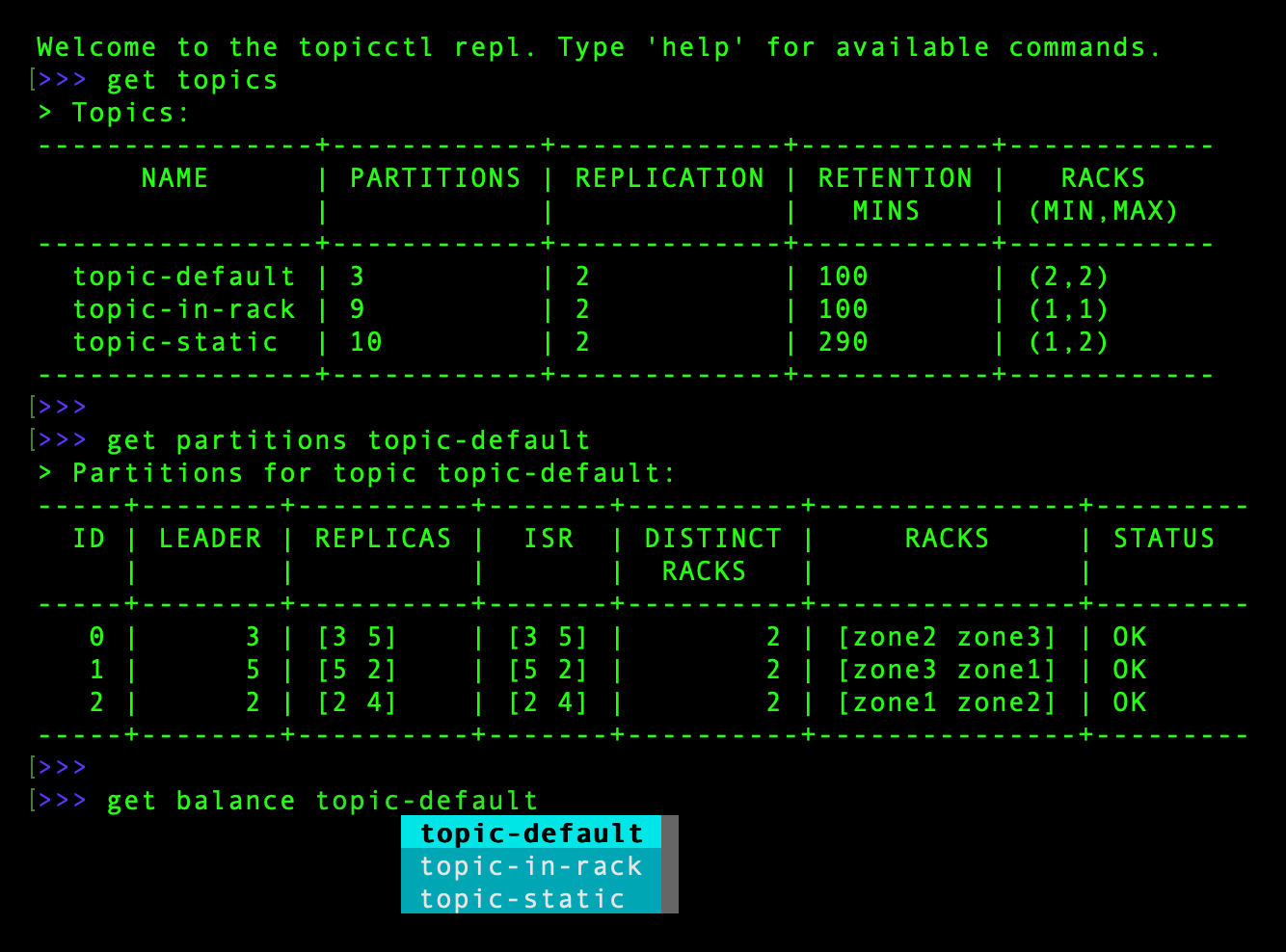
In addition to the repl, topicctl exposes a more traditional “get” interface for displaying information about cluster resources, as well as a “tail” command that provides some basic message tailing functionality.
topicctl is implemented in pure Go. Most interaction with the cluster is through ZooKeeper since this is the often the easiest (or sometimes only) choice and is fully compatible with older Kafka versions. Some features, like topic tailing and lag evaluation use higher-level broker APIs.
In addition to the go-prompt library mentioned above, the tool makes heavy use of samuel/go-zookeeper (for interaction with ZooKeeper) and the segment/kafka-go library (for interaction with brokers).
At Segment, we’ve placed the topicctl configuration for all of our topics in a single git repo. When engineers want to create new topics or update existing ones, they open up a pull request in this repo, get the change approved and merged, and then run topicctl apply via Docker on a bastion host in the target account. Unlike the old method, most changes are self-service, and it’s significantly harder to make mistakes that will cause production incidents.
Bigger changes still require involvement from the SRE team, but this is less frequent than before. In addition, the team can use topicctl itself for many of these operations, which is more efficient than the old tooling.
Through better tooling and workflows, we were able to reduce the burden on our SRE team and provide a better user experience around the management of Kafka topics. Feel free to check out topicctl and let us know if you have any feedback!

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.