A Guide to Universal User ID Mapping
By Erin Franz
We welcome Erin Franz, data analyst at Looker, to the Segment blog! This is the first post in her three part series sharing practical advice for common analytics conundrums: accurately identifying users, creating sessions for user activity, and event path analysis.
Let’s dive into the first topic — how to work with user IDs.
The user is at the center of every event in web analytics. An ID for that user is assigned to each event, but this identifier is only as accurate as the context and timing of the event.
For example, what happens if a user visits our website on their laptop, and then visits again on their mobile phone? A login or authentication process brings us closer to a single identifier for this user — but what about events pre-login? What if a user changes their email or username?
Raw events are often isolated or separated by their assigned user ID, preventing true user identification when these events are analyzed on their own.
Raw event counts are unaffected by user ID discrepancies. The number of logins, pageviews, cart adds, etc. will be the same no matter how the user is identified. But, these event counts mean a lot more if coupled with an accurate count of users who are active on your application, and the ability to trace these users over time to measure conversion funnels.
The majority of advanced analytics, from user behavior to retention, relies on user identification that accurately tracks users through all of their visits.
If we aren’t careful about stitching these user identifiers together, active user counts can get inflated by double-counting the pre- and post-login IDs — and only partial visit behavior can be examined because a single user’s activity gets split into two separate “users.” For example, without joining pre- and post-login behavior through a universal ID, it’s impossible to identify which campaigns or site features are most likely to lead a customer to pay after signing up.
Luckily, we can make our analyses accurate by using Looker and the data provided by the Tracks and Aliases tables in Segment Warehouses. What’s recorded in Tracks and Aliases will vary on the Segment implementation, but we’ll make some general assumptions for this example.
Track events, which record customer interactions, such as “Signed Up” and “Completed Purchase,” automatically collect the current anonymous ID (created pre-login) and user ID (created upon login) when available for each event. Aliasrecords when a user ID changes by marking a previous ID (before change) and a current user ID (after change).
We can simplify a typical user event-tracking scenario using the below diagram, where A represents pre-login anonymous IDs and U represents authenticated user IDs. Current state is on the left, and our goal is to transform this data to look like the diagram on the right.
The left of the diagram represents one user with three visits to the application, resulting in events reflected by five IDs. Consider this scenario: On the first visit in this sequence, the user with Anonymous ID A1 logs in as username U1. Events associated with that user have either or both A1 and U1 assigned to them. Simple.
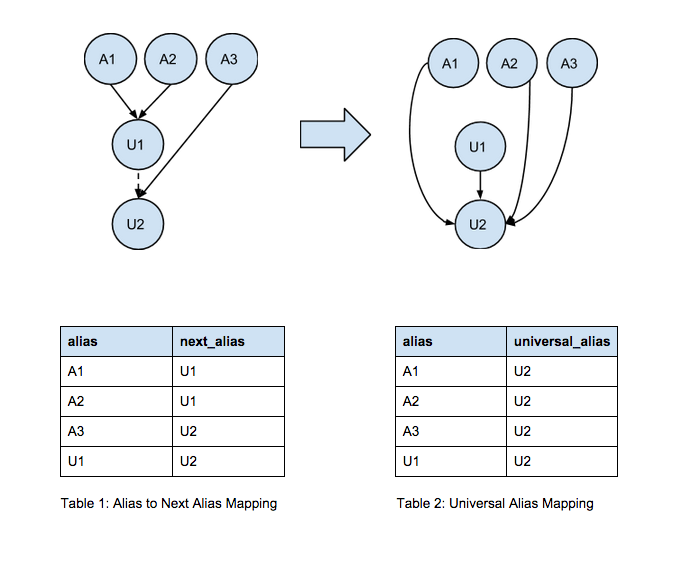
But on the second visit, the user’s Anonymous ID is assigned as A2 and the user logs in as U1, but then changes their username to U2, resulting in events with three distinct identifiers: A2, U1, and U2. Lastly, the user returns with Anonymous ID A3 and logs in simply with the new username U2.
The ultimate goal here is to provide an accurate mapping from any one of the five identifiers to one single user ID, as demonstrated in the diagram to the right and below it in Table 2, the Universal Alias Mapping table.
You can accomplish this in a few steps in Looker. First, we need to create the Alias to Next Alias mapping table, as shown in Table 1. This will consist of all the possible combinations of Anonymous ID and User ID from your Tracks tables, to map pre-login to login IDs. Additionally, we’ll need to include all the possible combinations of Previous ID and User ID from the Alias table, to map User IDs to changed User IDs. The union of both result sets will yield Table 1.
Once we have this result set, we need to map all values in the Alias column to a Universal Alias, which will be the most current user ID. In this case it is U2. This can be achieved by joining the table onto itself many times where the prior table’s next_alias equals the joined table’s alias attribute.
In some SQL dialects the number of joins can be made dynamic via a Recursive CTE, but in Redshift this function is not available — so we’ll just accomplish the same thing by joining a finite number of times (more times than a user ID could ever be re-aliased).
The above logic left joins the original table to itself up to five times on next_alias = alias. This creates a row for each original alias mapped through, at most, five user ID changes. (More or fewer joins can be used, depending on the context of the Segment implementation.)
The most recent value for the alias is chosen by coalescing backwards through the last available value to the first, resulting in the universal ID for that alias. This value is then optionally anonymized to a numeric value using a hashing algorithm. The end result is a mapping table as modeled in Table 2.
In Looker, this mapping table can be updated automatically at any frequency and stored in a materialized table. We can then reference it throughout our Segment Warehouses LookML model. The view file abstracts the result set from the underlying query, creating the mapping table. As a result, the end user is only exposed to the result set and doesn’t have to worry about any underlying complexity, while the data analyst can easily modify the logic if necessary.
In this case, we’ll join the Universal Alias Mapping view to the Tracks view in our model file. The Tracks view creates a similar abstraction for the Tracks table in Segment.
This LookML syntax ensures that whatever ID column is populated in the Trackstable (user ID or anonymous ID) is properly aliased to the latest alias. Since we have joined in the Universal Alias Mapping table, we can use it to compute more accurate user metrics as defined in the Tracks view file below (mapped_user_idand count_distinct_userssupplementing the original fields tracks.anonymous_idand tracks.user_id).
Since our mapping table will not contain a mapping for a track where user identifier is the universal ID, the mapping for those values will be null. So ultimately, the user identifier will be a coalesce of universal_alias_mapping.universal_user_id, tracks.user_id, tracks.anonymous_id, as defined in the mapped_user_id dimension. We can then define our count of active users as a count distinct of the derived mapped_user_id value.
Every Segment implementation is unique, and Looker’s LookML layer allows you to customize any aspect of your model. With this flexibility, you can catch edge cases and gain tremendous freedom in defining metrics specific to your application. Your data is transformed into a simple set of definitions that can power the analytics of your entire department or organization.
I hope you’ve enjoyed learning how to track events to a single user. My next two posts are going to get even more exciting, as we build off this foundational element of a universal ID to create custom session definitions and measure visit behavior. Subscribe to the Segment blog to be sure to catch them!
Want to get started with Looker & Segment? Let us know.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.