Endeavor has dozens of users that interact with Segment, many of whom operate within different business units. This includes marketers, product managers, data engineers and scientists, analysts, and members of our IT team.
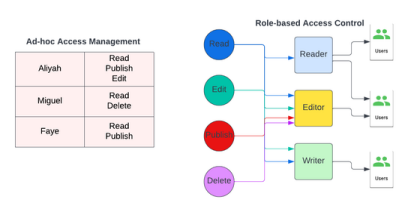
As these users have discrete roles in our broader organization and often their own distinct business units, relying on role-based access control principles to govern their access makes a lot of sense.
RBAC-as-Code
While it is possible to implement Role-Based Access Control in Segment using just its web interface, combining it within an "infrastructure as-code" (IaC) framework makes it even more useful.
Infrastructure-as-code is exactly as it sounds: managing and provisioning applications through code and configuration files. Our engineering team is a big fan of IaC and uses it wherever feasible, especially in the realm of access control.
Thankfully, Segment exposes the Segment Public APIwhich enables us to write code which directly interacts with Segment's identity-access management settings.
So, why did we decide to use infrastructure-as-code to manage RBAC?
-
"Nuclear Sub Principle": By committing all of our access management documents as configuration files to a git repository, we use peer review and require a minimum number of approvers to provision access. This removes the need of a human administrator interacting with a web interface and instead allows 2+ developers with sufficient access to review a pull request, and with peer oversight.
-
Auditability: A shared repository where all our configuration files are version controlled allows our team to understand exactly which users had what level of access at any particular point in time, as well as the ability to know who granted that access.
-
Scalability: IaC makes expansion even more streamlined by removing admin-user bottlenecks and introducing a common, singular interface for multiple platforms' access management settings.
-
Repeatability: We're able to easily reproduce our permission structures across Segment workspaces i.e. production and development, and make a full recovery of our access management configuration in case of catastrophic failure.
Implementation
Before describing our method to implement RBAC-as-Code, let's further define a few of the object types that we'll be working with:
-
Users:
-
Individuals that can be assigned to a user group
-
Never assigned permissions directly, rather they inherit permissions from their group
-
Can belong to multiple user groups
-
Identified by their email address
-
Roles: A basic grouping of permissions. For example:
-
Minimal Workspace Access/Access to view the workspace.
-
Cannot view any sub-resources or make changes to the workspace.
-
Source Read-only/Read-only access to assigned Source(s), Source settings, enabled Destinations, Schema, live data in the Debugger, and connected Tracking Plans.
-
You can find a comprehensive list of roles available in Segment here.
-
User Groups:
-
These hold users and one or more roles that users belonging to the user group are eligible to assume
-
User groups are a useful abstraction above the level of a role that allows us to overlay our business-specific role definitions over Segment’s built-in roles
-
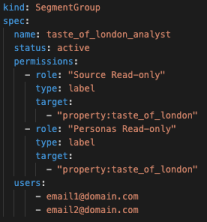
Able to define access based on our organization’s specific roles. At Endeavor, we may use groups like Data Scientist, Taste of London Marketer, and IT Administrator to categorize various levels of access.
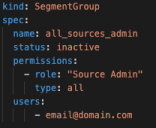
Using infrastructure-as-code as principles, all configurations for manipulating user, role, and user group objects are defined in YAMLfiles. Of course, JSON or any other data serialization language can be used in its place but we prefer YAML due to its readability.
We have two kinds of YAML files: users and groups. These files are processed using a wrapper that we’ve built around the Segment Public API.
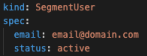
On and offboarding users YAML files
User YAML files accept two inputs: an email address and status.