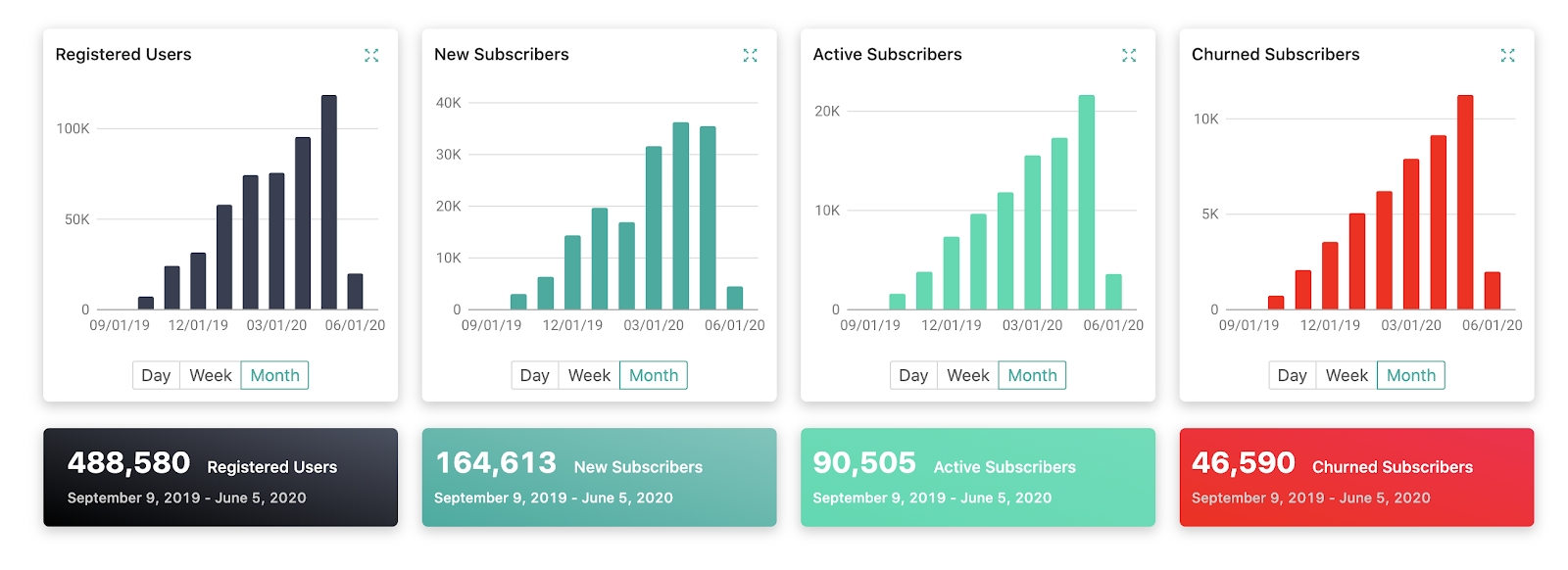
The richer insights increased dashboard engagement by 20% as it provided content creators with more valuable information about what drives new subscribers and retains subscribers, helping put more dollars into creators pockets for the content they produce at the end of the day.
Data Engineers can reduce time building and maintaining their data lake
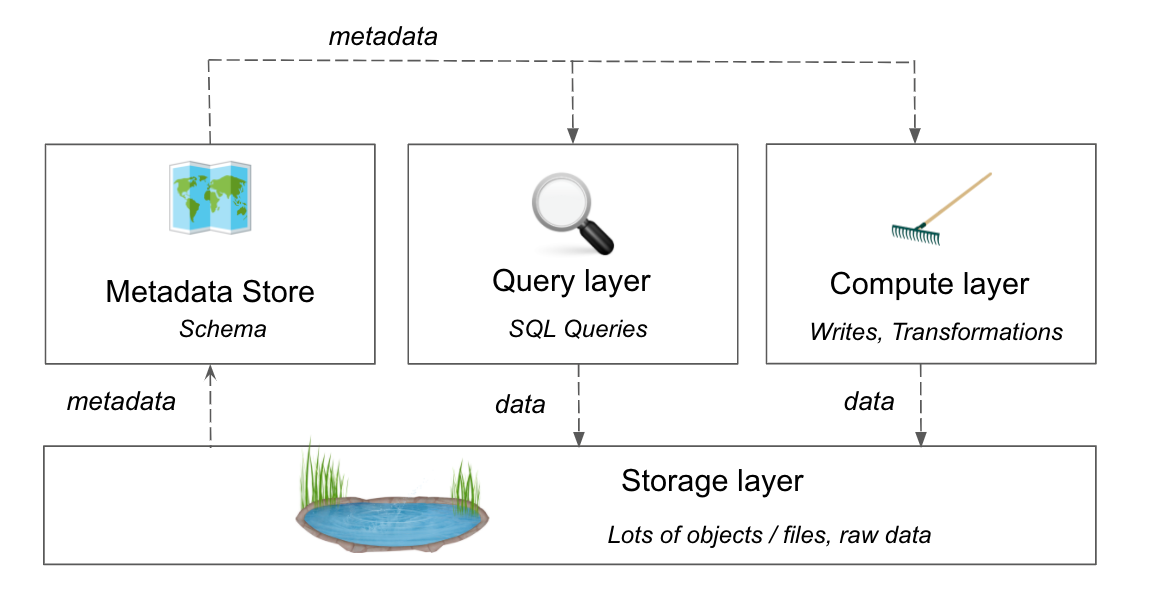
Data Engineers can leverage the Segment Data Lakes product to provide the an out-of-the-box foundation for their downstream consumers in Analytics and Data Science. Today when many businesses are forced to make large resource and time investments to design, build and maintain a custom data lake internally, Segment Data Lakes takes this work away from Engineering teams.
This can significantly cut down on time spent on data ingestion, optimizing data warehouse configurations and queries, managing schema inference and evolution, or connecting to a data catalog so that the data is discoverable by downstream tools.
As a result, many Data Engineering teams are turning to Segment to help provide a baseline data lake architecture rather than needing to design, build and maintain it themselves.
From a Data Engineering perspective, Segment Data Lakes enabled us to move a roadmap item forward by a full quarter. Anders Cassidy, Director of Data Engineering
Optimize data storage and compute costs
By relying on a cheap data store such as Amazon S3 instead of a data warehouse to store all customer data, companies are able to significantly reduce their data storage cost. As Rokfin migrated from a data warehouse to Segment Data Lakes, Rokfin was able to reduce their data storage cost by 60%.
This new cost savings is opening up doors for companies - they’re able to leverage this storage cost reduction as another way to cut down spend across the business, or re-purpose this cost to invest more deeply in compute resources to run more EMR jobs and downstream queries to gain more value from putting their data to use.
Data Engineers can future-proof architecture to build the fundamentals for machine learning investments
Data Engineering teams are now able to feel confident that their data architecture is future-proofed to not only meet today’s business needs, but also support growingly complex changes.
The fundamental pre-requisite for machine learning, segmentation, and analysis is complete, accurate and accessible data. Historically, data architecture constraints forced companies to prioritize keeping only subsets of the data to reduce storage costs or optimize compute performance.
With Segment Data Lakes, all historical, current and future customer behavioral data can be easily stored without consequence to cost or resource contention. Additionally, Data teams who have already unloaded historical Segment data can re-build a complete, high-depth behavioral dataset in S3 using Segment replay.
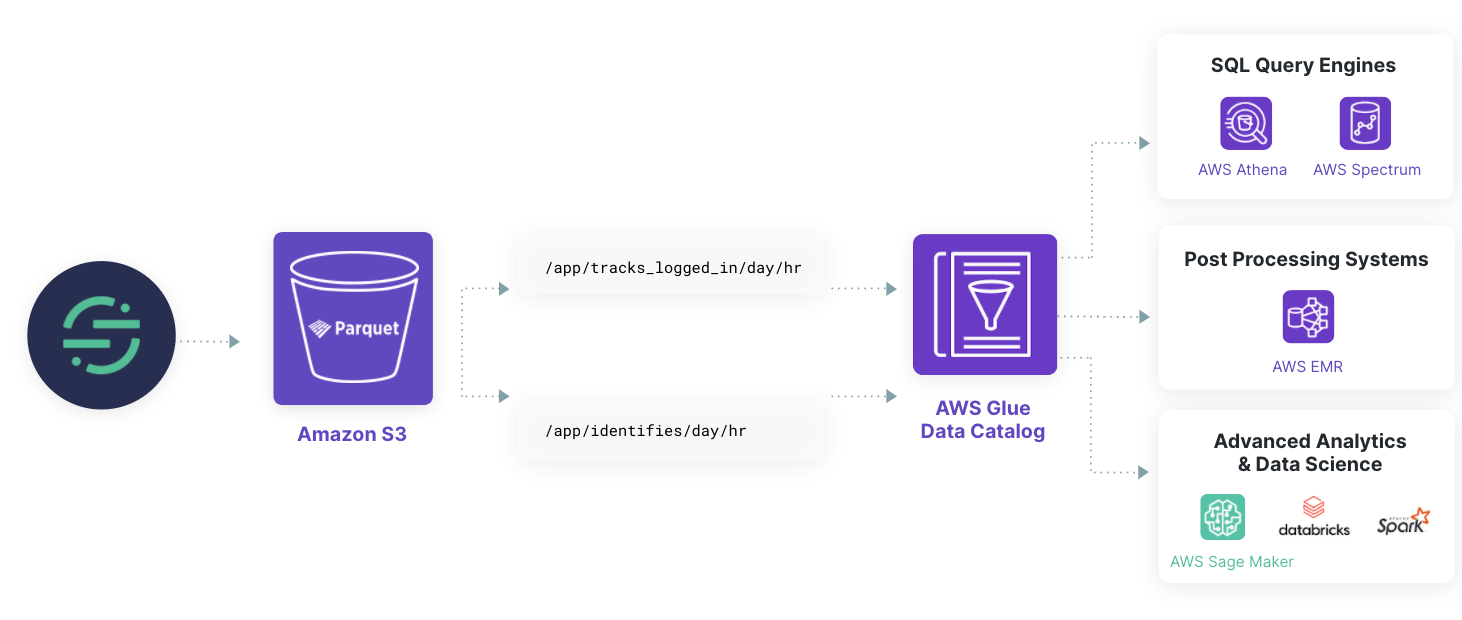
With the foundational data set in place, data consumers now have the flexibility to plug in just about any compute layer they need, from Databricks, to Athena and EMR, to even a warehouse with external tables.
Segment Data Lakes provides the fundamentals to innovating businesses, regardless of where they are on the machine learning maturity journey. Whether businesses are focused on advanced segmentation today, or machine learning tomorrow, both require the same building blocks.
Segment Data Lakes is available to all Segment Business tier customers as part of the current plan. Get started today by checking out our technical documentation and set up guide.
If you’re not a Segment customer or not on the Business plan, contact us to us to learn more or sign up for our upcoming webinar.