How we saved $100k a month with Kafka networking optimization
Network transfer costs are one of the biggest costs of running on the cloud. Here's how we optimized ours to save $100k month.
By Benjamin Yolken, Julien Fabre
Network transfer costs are one of the biggest costs of running on the cloud. Here's how we optimized ours to save $100k month.
At Segment, we process tens of billions of events per day. While this is positive from a business perspective, it also means our cloud providers' bills need constant monitoring and management. Being an infrastructure-heavy, SaaS business, it's very easy for costs to spiral out of control, so we have to be very careful about the effects of cloud costs on our gross margins.
Over the last few months, increased online activity has meant a massive increase in traffic. The knock-on effect is that we started noticing that our network transfer costs (i.e., what cloud providers charge for data going into and out of instances) were increasing at a significantly higher rate than the traffic load itself.
If this trend continued, it could significantly harm the financials of our business.
After digging in more, we realized a significant portion of the increase was associated with our Kafka clusters, which we use for passing events through our core pipeline. We decided to tackle the challenge of significantly reducing the cost of our Kafka platform while respecting our availability SLO and SLIs.
This post will explain why Kafka networking can be so expensive in cloud environments and what we did to fix it.
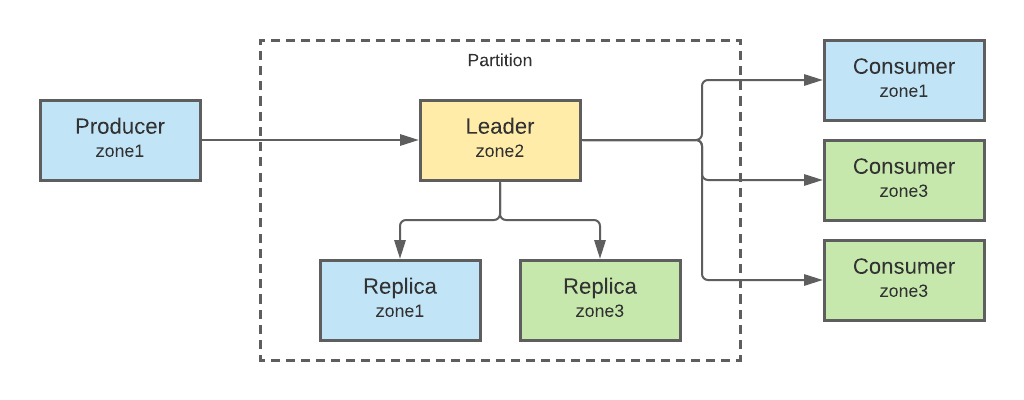
Before going into the details of what we changed, let's discuss the networking "fan-out" that occurs when a message (roughly equivalent to a single event in Segment's backend) is added to a partition in a Kafka topic.
First, the message is sent from the producer to the partition leader that the message is written into. This leader replicates that message to the followers in the partition (at Segment, we use a replication factor of 3 in most of our topics, which means there are 2 followers). Finally, the message passes from the leader to each consumer reading from the partition.
Assuming 3 replicas and 3 consumers, this means each message is transferred over the network 6 times.
The problem is that if the transfer crosses availability zone (AZ) boundaries in a cloud environment, it's not free.
Here's a possible worst-case scenario, where the leader is in a different zone than all the other nodes:
In the case of AWS, where most of our Kafka infrastructure runs, data transfer costs can be complicated to figure out (see this guide for a good summary).
In our Kafka clusters, the cross-AZ traffic flows between EC2 instances in the same VPC without involving other AWS services, so the list price is $0.02/GB.
This doesn't look like a lot of money. But when you're transferring multiple TBs per day, it adds up. It also increases faster than the raw number of messages, so it's only a matter of time before your accounting team starts noticing.
After crunching the numbers and evaluating the tradeoffs of different strategies, we started several parallel efforts to cut down on our cross-zone Kafka network traffic.
Before this project, the replicas for almost all of our topic partitions were spread across three availability zones. This was to ensure the best service reliability and to protect ourselves against a full zone outage.
However, as discussed earlier, this meant that each produced message was copied to all three zones, leading to a large amount of costly cross-zone data transfer.
After thinking about our pipeline's failure modes, we realized the data in many of our topics could be recreated from upstream checkpoints if required. We could remove the cross-zone replication from many of our topics without affecting our pipeline's overall reliability.
Given this insight, we first set up a robust set of "ingest" topics at the front of our pipeline. These had cross-zone replication and also long retention windows (up to 48 hours).
We then went through each of the downstream topics and used topicctl to convert it to use in-rack replica placement. This topology still uses the same number of replicas (three in the Segment case), but these are in brokers in the same zone, which minimizes the amount of cross-AZ traffic.
The data migrations took up to 6 hours for our largest topics (there was a lot of data to transfer!), but we didn't notice any significant performance problems in our clusters while they were ongoing, which was great.
After this was done, we eliminated 2 cross-zone transfers per message per topic.
Most of our Kafka consumers are written in golang and use a common reader library built on top of kafka-go.
In parallel with the replica migrations, our team went through all of the consumers in our primary data pipeline and switched them to a new reader library that uses kafka-go's RackAffinityGroupBalancer feature. The latter matches consumers and partitions so that as many pairs as possible are in the same zone.
After this was done, we eliminated another 1-5 cross-zone transfers per message per topic (varying based on the number of consumer groups reading from the topic).
Producing messages in-zone is a bigger operational challenge than consuming in-zone.
Although it's possible to match producers to partition leaders by zone, it's easy (particularly as leaders shift around) for the load per broker or per partition to become imbalanced. If the producers themselves become zone-imbalanced (due to a deploy, for instance), this can also lead to an imbalance in the cluster without careful coordination.
The exception to this is in our pipeline's deduplication portion, discussed in a previous blog post. This is where we use semantic partitioning with a static, 1:1 mapping between producers and partitions. Here, because the cardinality and zones of the producers don't change, we could safely shift around the zones of each partition to reduce the amount of cross-zone produce traffic. We used the static-in-rack strategy in topicctl to achieve this.
We are planning to revisit this approach and add producer optimizations to more components of our pipeline. The kafka-go roadmap includes plans for a zone-affinity producer, so after that is implemented, we could use that in our code.
With the version 2.1.0 release, Kafka introduced support for a new compression codec, zstd. We did some testing on a shadow version of our production traffic and found that zstd was 40% more space-efficient than snappy, our previous default, without significantly reducing pipeline performance (i.e., due to potentially higher compression and decompression overhead).
Unfortunately, most of our topics are in clusters running older Kafka versions. However, we could switch to zstd for the "ingest" topics at the head of our pipeline since these were hosted in a new cluster. We were keeping cross-zone replication for these topics, so by using zstd we were able to reduce the networking costs associated with these topics significantly.
In the future, we hope to migrate more topics to zstd as we upgrade our clusters to newer Kafka versions.
With the efforts above, we gradually transitioned the topologies of some key topics from something like this:
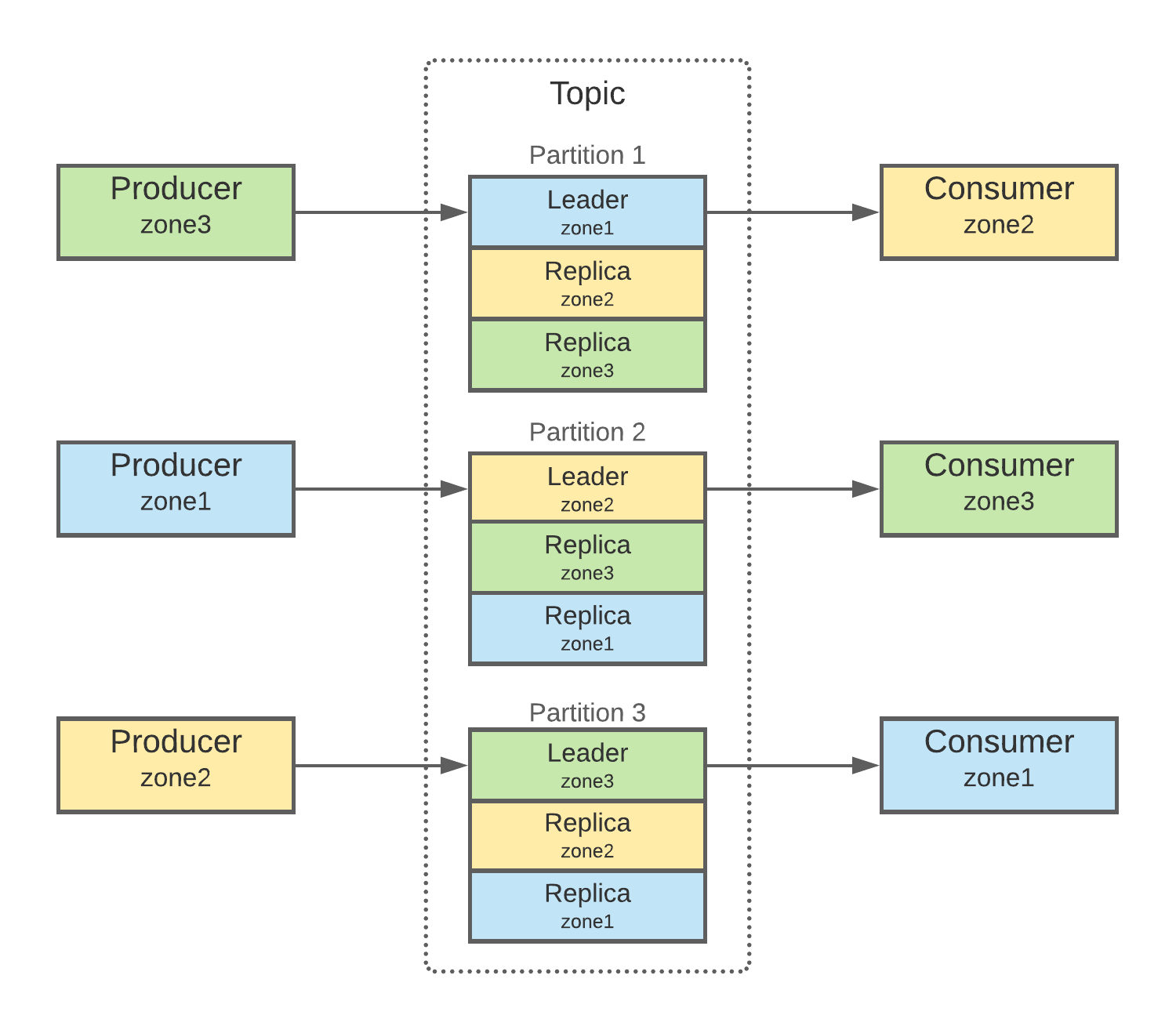
Into layouts looking more like:
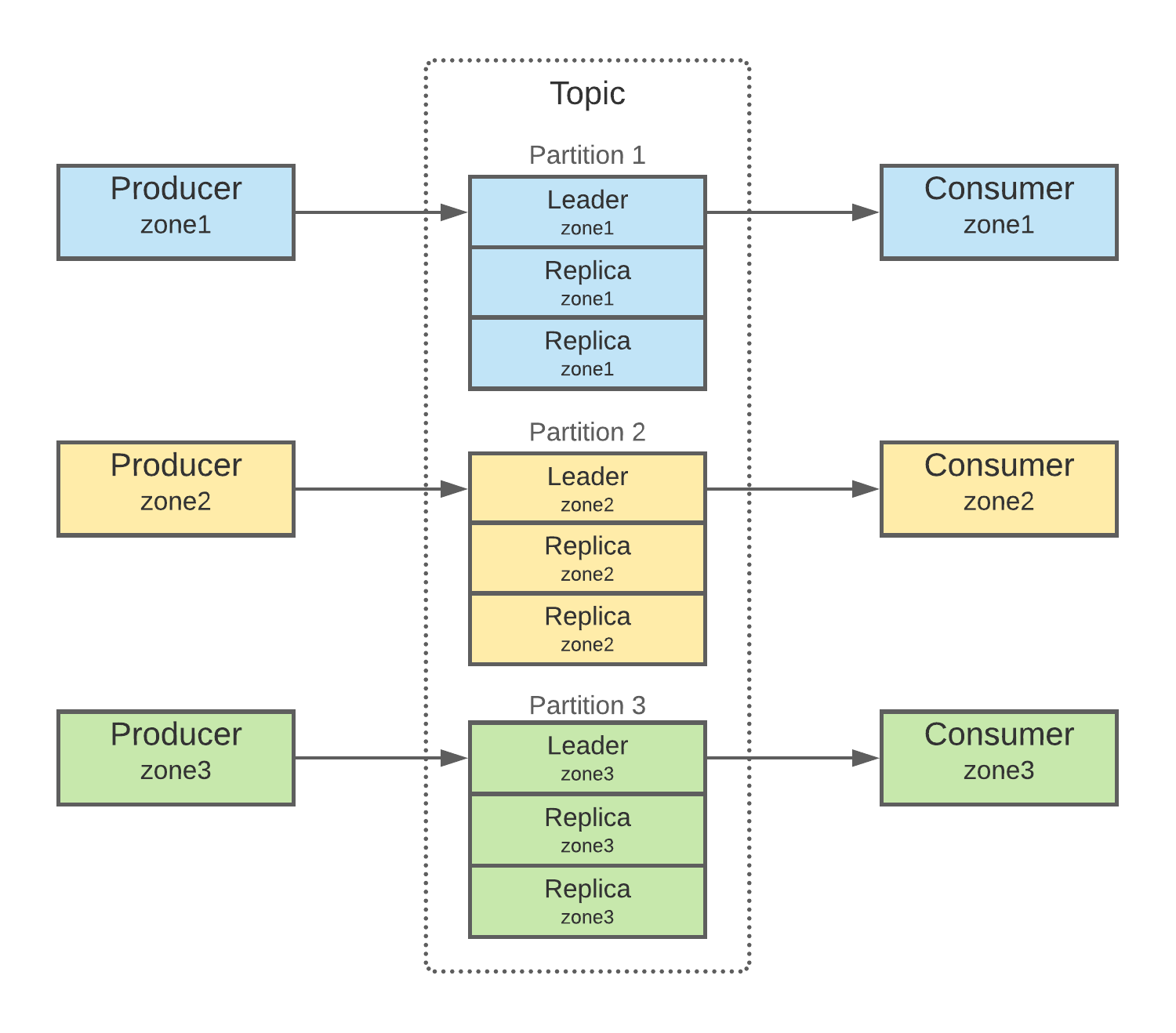
As we made progress, we began seeing our daily EC2 data transfer costs go down. By the time we finished the work on all of our large topics, we had reduced our costs by more than $100k / month, or $1.2M / year. Given the amount of work required (approximately 2 engineers for 2 months), the effort was extremely cost-effective!
In addition to saving Segment a lot of money, this project also led to new tooling (including topicctl), new runbooks for our Kafka clusters, and a general cleanup of our topics and clusters.
If you operate in a cloud environment, take another look at your bill's transfer costs and calculate what percentage is due to cross-zone Kafka networking. If it's a non-trivial amount, you may be able to save a lot of money by trying some of the strategies described above.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.