Github-Based Kubernetes Config Management: Our Guide
Today, we're releasing kubeapply, a lightweight tool for git-based management of Kubernetes configs. Here's why.
By Benjamin Yolken
Today, we're releasing kubeapply, a lightweight tool for git-based management of Kubernetes configs. Here's why.
Today, we're releasing kubeapply, a lightweight tool for git-based management of Kubernetes configs. Here's why.
Several pieces of Segment’s core data pipeline, including Centrifuge, our message delivery system, run on Kubernetes.
Unfortunately (or fortunately for those who like choices!), Kubernetes leaves many operational details as “exercises for the user” to figure out. Among these are change management at scale i.e. the procedures and tools for safely configuring and updating services and other workloads in complex, performance-sensitive production environments.
Over the course of expanding our Kubernetes usage internally, we’ve done a lot of trial-and-error around the different ways to handle change management.
In this post, we’d like to share a workflow and associated tool, kubeapply, we’ve adopted internally to make updating services in production easier, safer, and more flexible than our previous approaches.
Resources in a Kubernetes cluster are configured through the Kubernetes API.
Although it’s possible to manage resources via the API directly, users typically interact with the cluster through higher-level tools and libraries because of the complexity involved.
Here are some common methods to generate configs and push updates via the API.
The simplest way to manage resources is to create static, YAML representations of them. Then, to update the configuration of these resources in the cluster, you can just run kubectl apply -f [path to files] locally.
The kubectl client fetches the current configuration from the cluster, figures out what, if anything, needs to be changed, and then makes lower-level API calls (create, patch, delete, etc.) to align the actual and desired configurations for each resource.
Static YAML is fine for simple, stand-alone configs. Still, it requires repetitive copying-and-pasting when creating similar variants of the same base configs (e.g., one each for development, staging, and production).
It’s also not the greatest way to share configs with others- my version of, say, a Kafka cluster, will assume a particular number of brokers and resources per broker.
If I hand off my configs to you and you want to update these parameters, you need to trawl through the YAML and manually replace the associated values, a tedious and potentially error-prone process.
Several tools have been released to address these issues.
A popular one is Helm, which, among other functionality, uses YAML templating to make config sharing and customization easier. Another solution in this space is kustomize.
Unlike Helm, kustomize uses overlays and patches, without any templating, to generate configs. Note that Helm and kustomize have many differences aside from their philosophies on templating, and that using them is not mutually exclusive.
By design, lightweight frameworks like Helm and kustomize deliberately limit the scope of possible operations during the generation process. For example they don’t make it easy to hit arbitrary HTTP endpoints or shell out to external tools.
To get more flexibility, you can move to a framework that exposes more programming-language-level functionality.
The examples here range from Terraform, which uses a fairly basic config language, up to something like Pulumi, which embraces the full “infrastructure as code” mantra by supporting multiple, high-level programming languages.
In the middle are frameworks like kssonet (now deprecated) or skycfg, which use deliberately limited programming languages (jsonnet and Starlark, respectively, for the previous examples) to make the generation process flexible, but at the same time hermetic and reproducible.
These code-based frameworks offer more flexibility than static YAML or YAML templates, but at the cost of a steeper learning curve, more complex tooling, and potentially harder debugging. Sometimes, moreover, the extra flexibility might be unwanted, particularly in an organization that’s trying to impose standard ways of doing things or limit potential security holes in build and deploy workflows.
Another approach, commonly used inside large organizations, is to write custom tooling that generates and applies Kubernetes configs from organization-specific, higher-level specs.
This makes sense if you’re in a company with dozens of variants of the same base thing (e.g., a stateless service) and/or an existing, non-Kubernetes deploy system that already has its own config format.
Among publicly disclosed examples, Stripe takes this approach to configure its internal cron jobs (more details here).
Our engineering team have also seen it used at some of our previous companies. It can work well, particularly if you want to impose universal standards across an organization, but has the drawback of being less flexible than other approaches.
At Segment, we primarily use a combination of static YAML and lightweight config expansion. Segment-specific services deployed in a single place use static configs or simple YAML templates to update things like image tags.
On the other hand, Helm is used for configuring infrastructure that runs in all of our clusters. Most of these are third-party open-source tools, including alb-ingress-controller and prometheus, which are already distributed as Helm charts.
Looking forward, we’ve started to explore code-based frameworks like Terraform and skycfg, although these aren’t rolled out extensively yet. Finally, we don’t use any “purpose-built” config expansion for Kubernetes, although our internal tool for deploying services to ECS does do this, and it’s a pattern we may explore in the future.
As we started using Kubernetes, we initially wrapped tools like kubectl and helm in Makefile targets and small scripts. To expand out configs and deploy a change via kubectl, one would run something like make deploy in the repo or, in some cases, add this as a step in the CI pipeline for the associated repo.
This worked for individual projects, but had several issues when trying to standardize and expand Kubernetes usage at the company:
Makefiles and custom scripts are extremely flexible but hard to standardize as an interface. Different projects would use slightly different implementations, along with slightly different repository layouts, which made it confusing when switching between them.
The link between code in the repository and the configuration of the cluster was not always clear. Because many apply operations were done on the command-line, the repository configuration could easily get out-of-sync.
A related point was that the full impact of a change on the cluster was hard to know until you actually deployed. This made changes potentially dangerous.
When thinking about improvements, we were inspired by our flow for AWS changes, which uses a combination of Terraform (for configuring, planning, and applying changes) and Atlantis (for integrating the process with Github).
The flows and tooling here aren’t perfect, but they’re generally effective at making changes consistent and safe, and for keeping our checked-in configs consistent with the configuration of our infrastructure.
Could we do something similar for our Kubernetes changes, on top of our existing tooling and configs?
The solution was a new process with the following steps:
Expand: Given some set of input configs and a target cluster, run an expansion/generation process to create Kubernetes YAML configs.
Validate: Verify that the expanded configs are valid Kubernetes resource definitions.
Diff: Compute the difference between the local configs and the current state of the associated resources in the cluster and show this to code authors and reviewers before code is committed.
Apply: Update the state of the cluster to match the local configs and merge all of the changes (both inputs and expanded configs) into master in the associated repo.
While it’s possible to implement the above with simple scripts and Makefile targets, we decided to create a tool that would standardize the user experience and handle the low-level details of wrapping things like helm and kubectl behind-the-scenes.
We also wanted to support an optional Atlantis-inspired, Github-based flow that would make the diff and apply steps easier and enforce rules like request approval and green CI builds.
The result is kubeapply, which we’ve recently released as open-source. The full details are in the project README, but a few highlights to note are as follows:
Multiple input formats: kubeapply wraps multiple expansion/generation systems, including YAML templates, Helm, and skycfg. It also supports static YAML inputs.
Standardized cluster configs: Each cluster instance has a YAML config that contains parameters to be used in downstream steps, e.g., to set image tags, replicas, and other things that might vary by environment or over time.
Runnable on the command-line or in Github: The command-line offers the most flexibility, and is the ideal place to run the initial expansion since the outputs are checked-in. Downstream steps are easiest in Github (see the example below), but the setup can be tricky in some cases, and it’s nice to have a backup flow in case of emergencies.
It’s worth noting that kubeapply is still a work-in-progress and is currently optimized around Segment’s use cases and infrastructure (e.g., AWS Lambda for hosting webhooks), which might not work for everyone.
Even if it’s not directly applicable for your Kubernetes environments, we hope that it at least provides some inspiration for ways to manage your workload configurations.
The following screenshots show the Github flow for a small Kubernetes config change, in this case, changing the CPU limit for a single container in a single cluster.
Some terminology notes that may help with understanding the screenshots:
kingmaker: A small service we run internally to rebalance the leaders of Kafka partitions
stage: The name for our staging environment and associated AWS account
us-west-2: The AWS region that the cluster runs in
centrifuge-destinations: The cluster type that kingmaker runs in (along with Centrifuge)
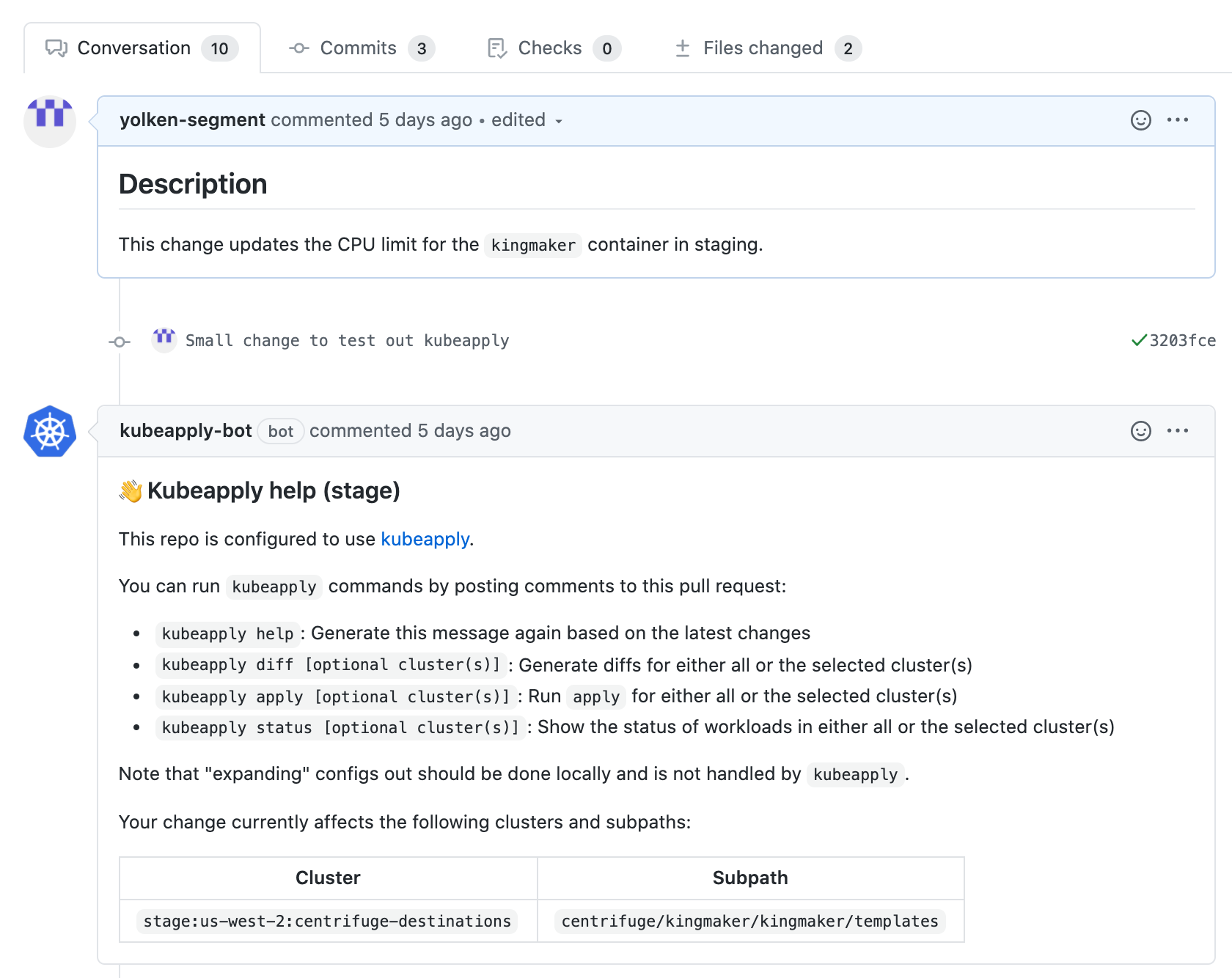
On the initial pull request creation, kubeapply detects the clusters and subpaths that are affected by the change, and posts a summary comment along with some tips for running the tool.
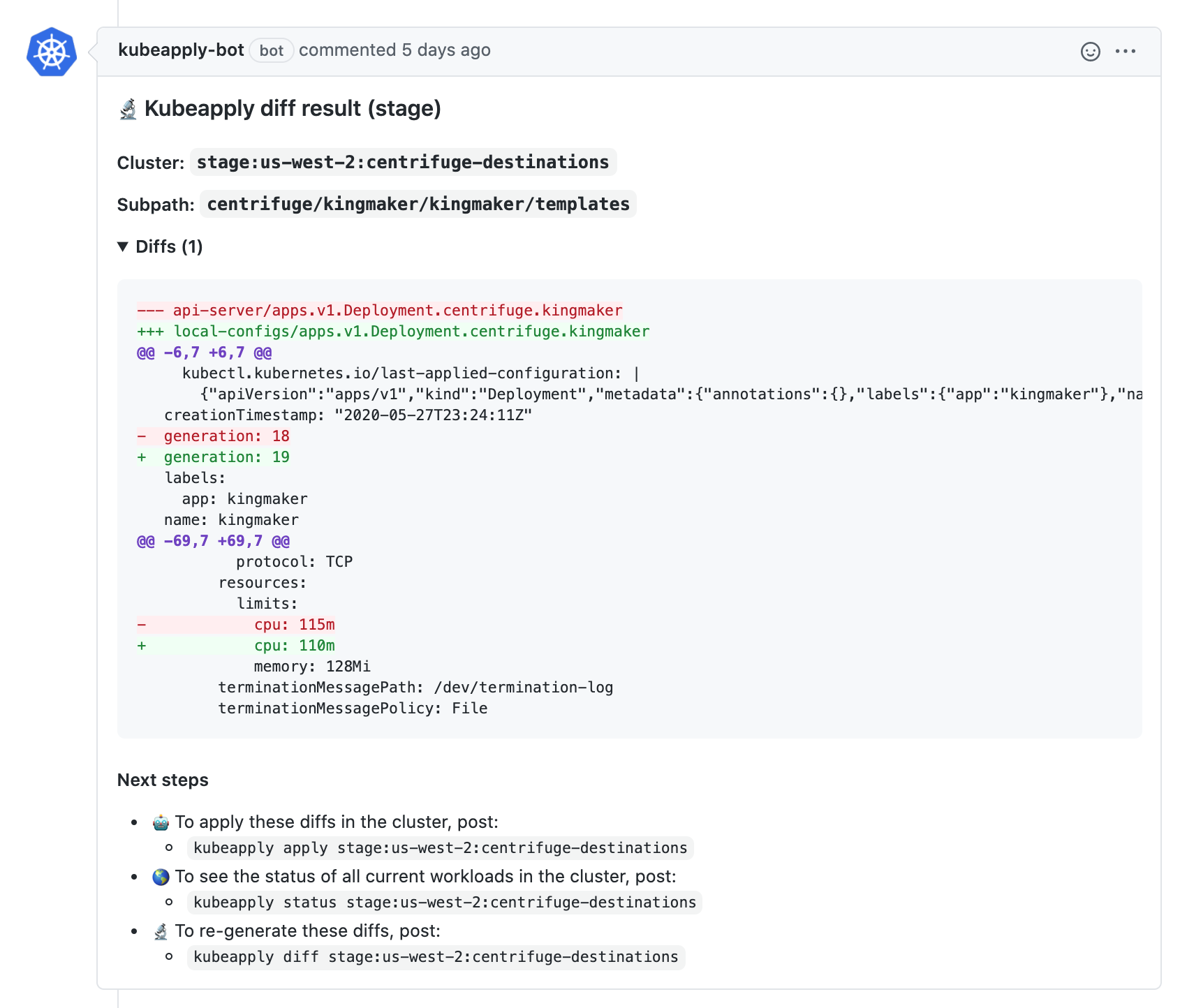
kubeapply automatically runs a diff and pastes the results as a Github comment. Diffs are run on subsequent pushes automatically and can also be triggered manually via Github comments.
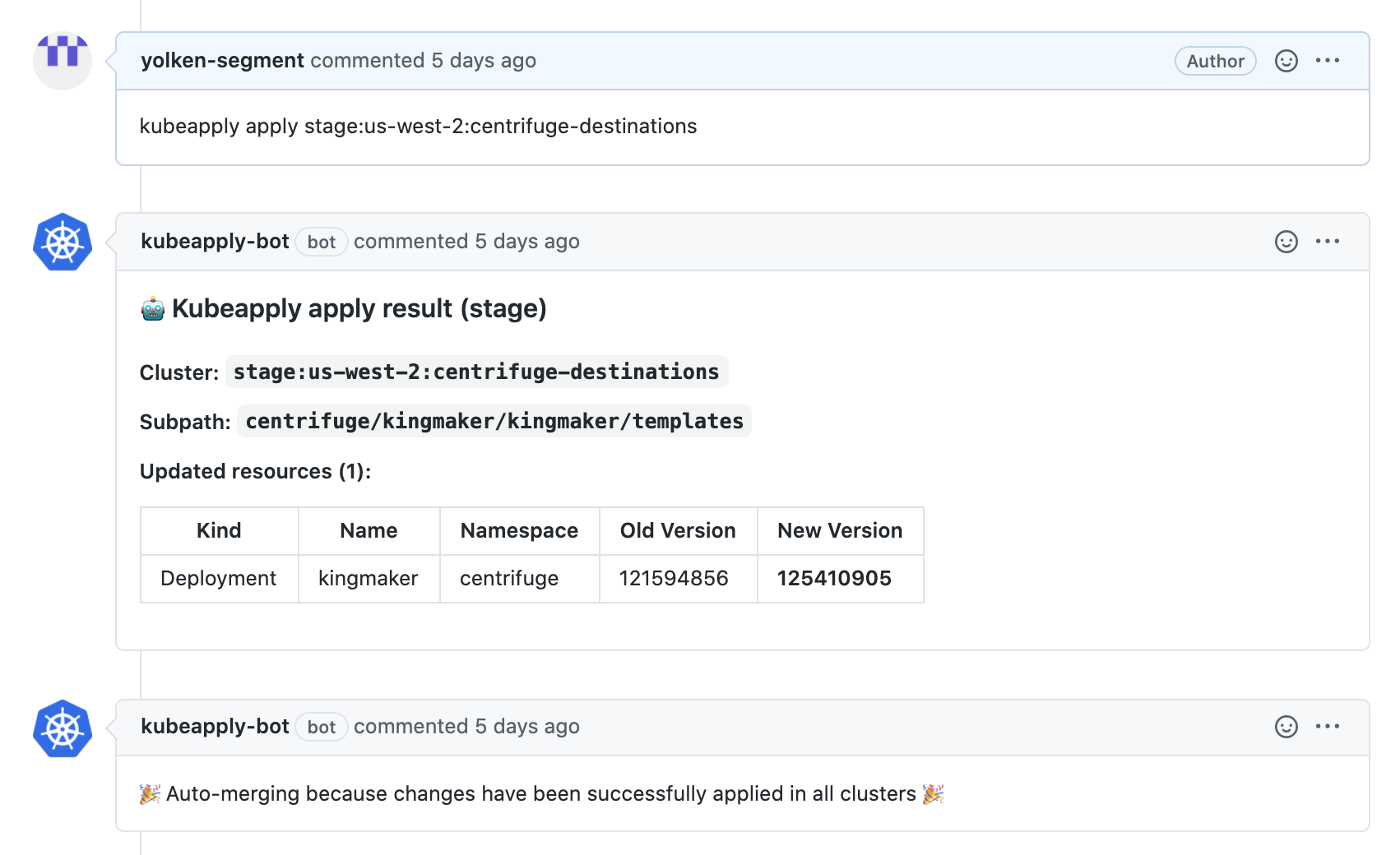
Once the change is approved and CI is green, the changes can be applied by posting a kubeapply apply comment in the pull request. If all Kubernetes changes are successfully applied, the git change is automatically merged into master and the pull request is closed.
As part of the kubeapply rollout, we moved all of our Kubernetes configurations into a single repo. Each cluster type lives in a separate directory, with the subdirectories organized according to the standards described in the kubeapply documentation. There are typically two configs per cluster type, one for staging and one for production, although more might be added in the future.
On each change, our CI system runs kubeapply expand followed by kubeapply validate to verify that the expansion results match the contents of the change and are valid Kubernetes configs. The diff and apply steps are then run in Github via the process described above.
We’ve found that the new process and tooling has significantly improved the developer experience around making Kubernetes changes in production.
In addition, it has increased our confidence in using Kubernetes as an orchestration system for our critical workloads. Please check out the kubeapply repo and feel free to adapt the tool for your team’s use cases.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.