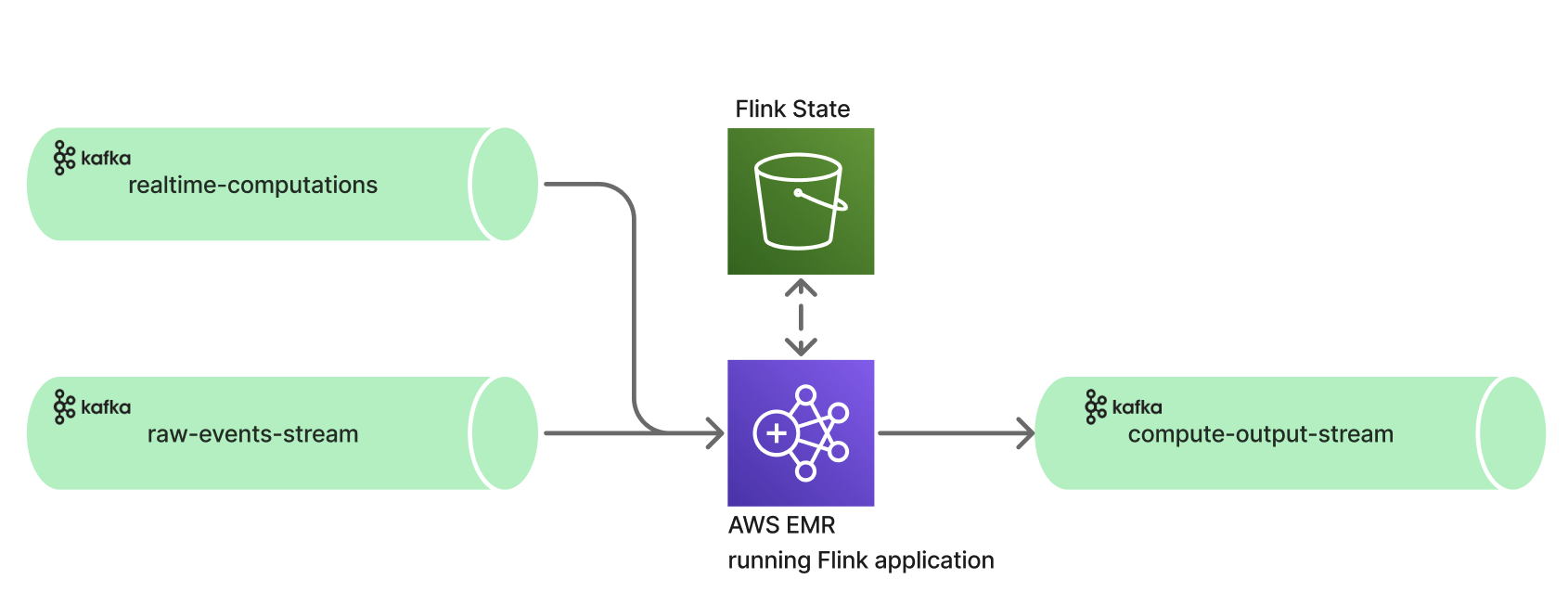
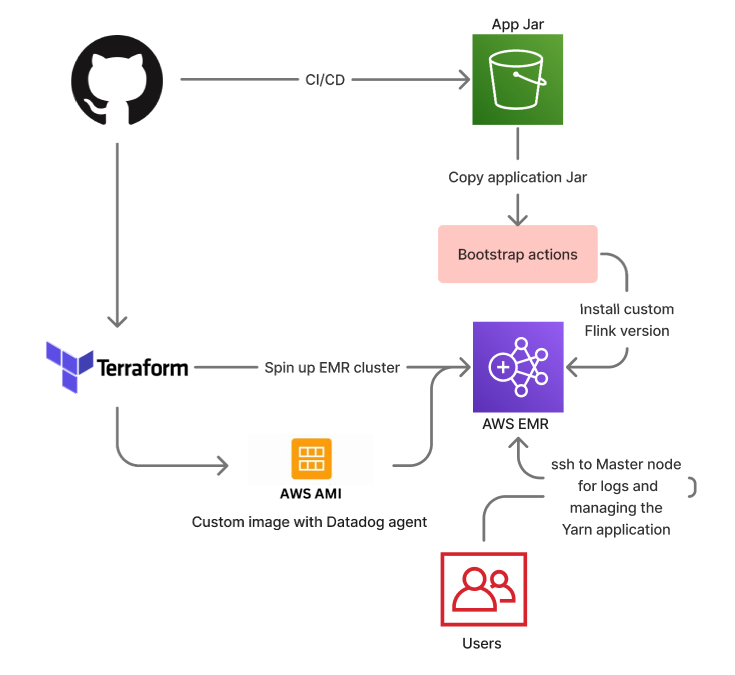
Pain points with the setup
-
Platform:
-
The Flink version is tied to the underlying AWS EMR version. There is no native support for custom Flink versions - In this setup, the EMR bootstrap script installs a custom Flink version on EMR nodes
-
There is no automatic recovery of the application if one of the nodes in EMR fails due to an underlying hardware issue
-
EMR only supports limited EC2 instance family types
-
We had to build a custom AMI to support installation of Datadog agents for metric collection
-
Deployment process:
-
Updating Flink application lifecycle (stopping/restarting) required users to SSH into EMR EC2 node and running YARN commands
-
Updating Application jar required manually killing the Yarn session, copying new JAR via scp or s3 cp and running the script with updated JAR
-
Troubleshooting failures
-
Application logs are not stored beyond the lifecycle of the cluster
-
Troubleshooting required SSH into EMR EC2 nodes
-
Accessing Flink UI requires SSH tunneling
-
Cost
-
AWS EMR imposes additional cost on top of standard EC2 pricing.
To amplify the pain points, we had multiple Flink/EMR clusters in our production operating on different sets of computations. Users had to repeat the process for each cluster with the lack of automation. On top of that, we were spending approximately $250,000 a year on EMR surcharge alone.
After some initial research, we found out that Flink Kubernetes Operator route of deploying Flink applications on Kubernetes solves most of the pain points with the current setup of running Flink on EMR without re-architecting or migrating to a different solution altogether. It was also an easy pick as Segment has an amazing set of tooling for deployments, observability built around Kubernetes, and we could take advantage of these solutions right out of the box.
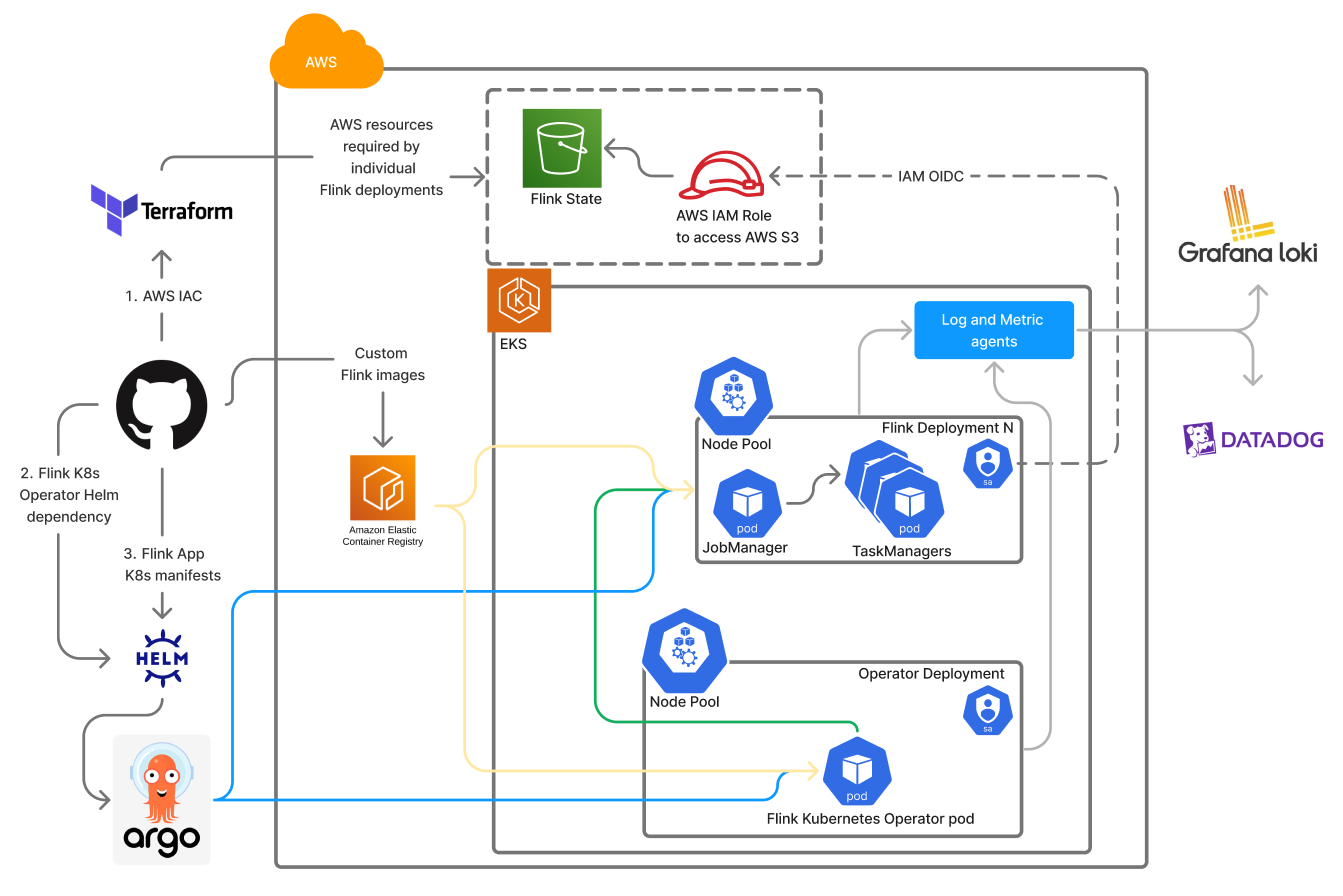
This is a high level break-down of our new setup.
-
Terraform is used for Infrastructure setup on AWS. This includes EKS cluster, EC2 node pools in EKS, AWS S3 buckets for Flink state, AWS IAM roles for access to S3, and other resources.
-
ArgoCD and Helm for Flink Kubernetes operator and Flink applications deployment on EKS. Helm templates with most of the basic configuration are available for users to customize their deployments.
-
Integrate Flink TaskManager, JobManager, and Operator pods with our observability stack to ship logs and metrics to Grafana Loki and DataDog respectively.
Each Flink application was launched with its dedicated EKS node pool, namespace, and service account for better isolation. We could accommodate multiple applications within a single EKS cluster with one Flink Kubernetes operator managing all the applications.
With a highly available and more reliable setup, there was very minimal operational setup to maintain the Flink applications. Developers were able to customize and deploy new Flink applications within minutes in a more seamless fashion. The reduced infrastructure cost was also a huge win with the elimination of the AWS EMR surcharge.