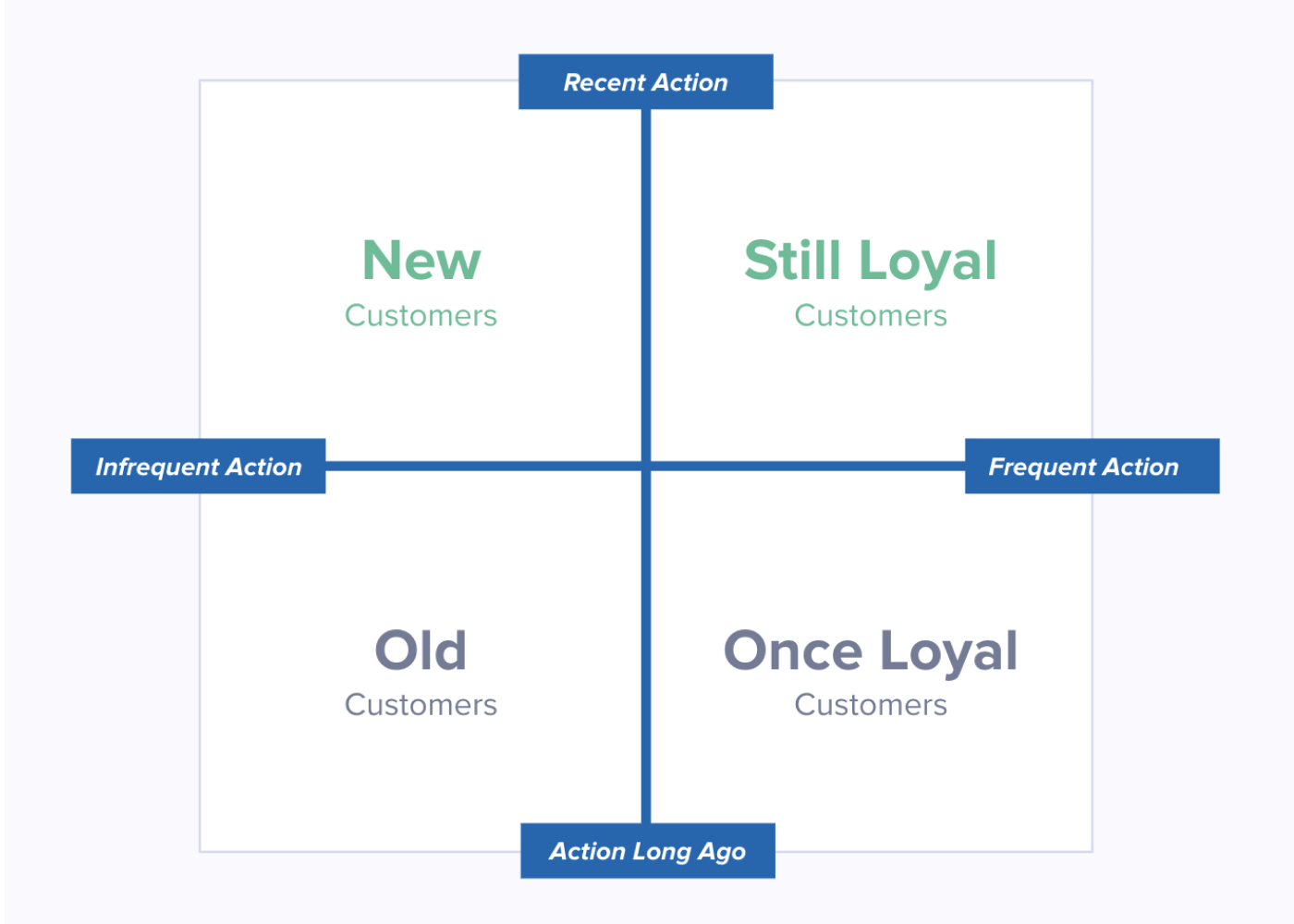
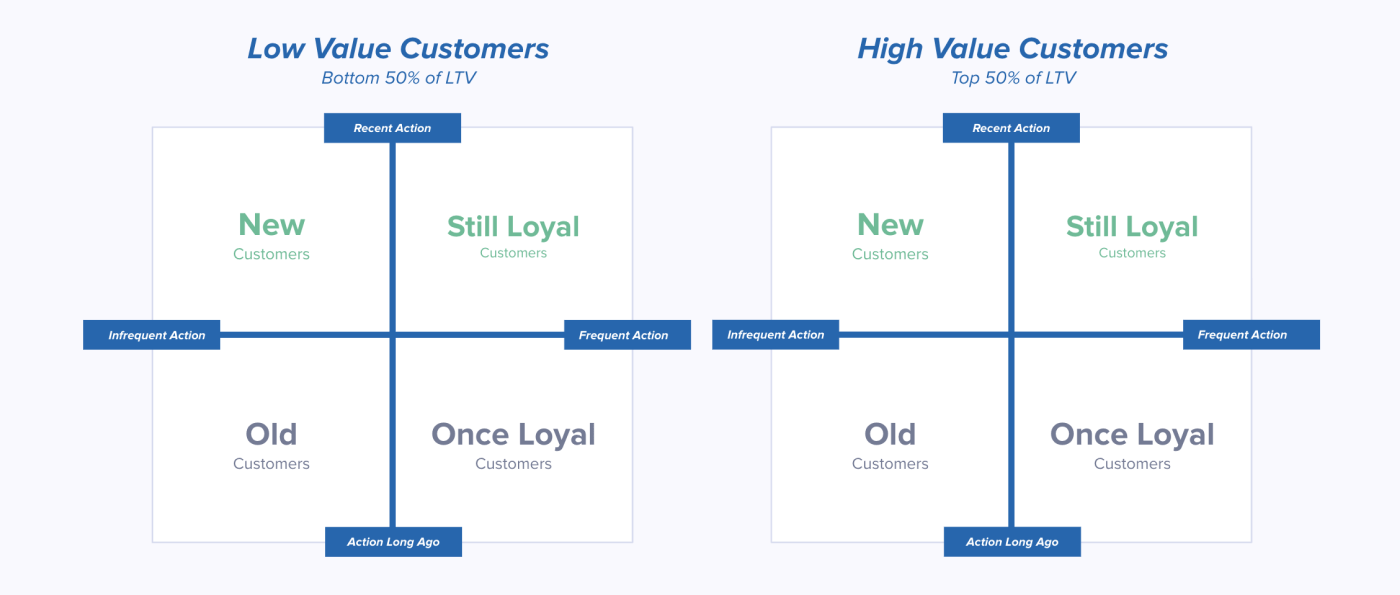
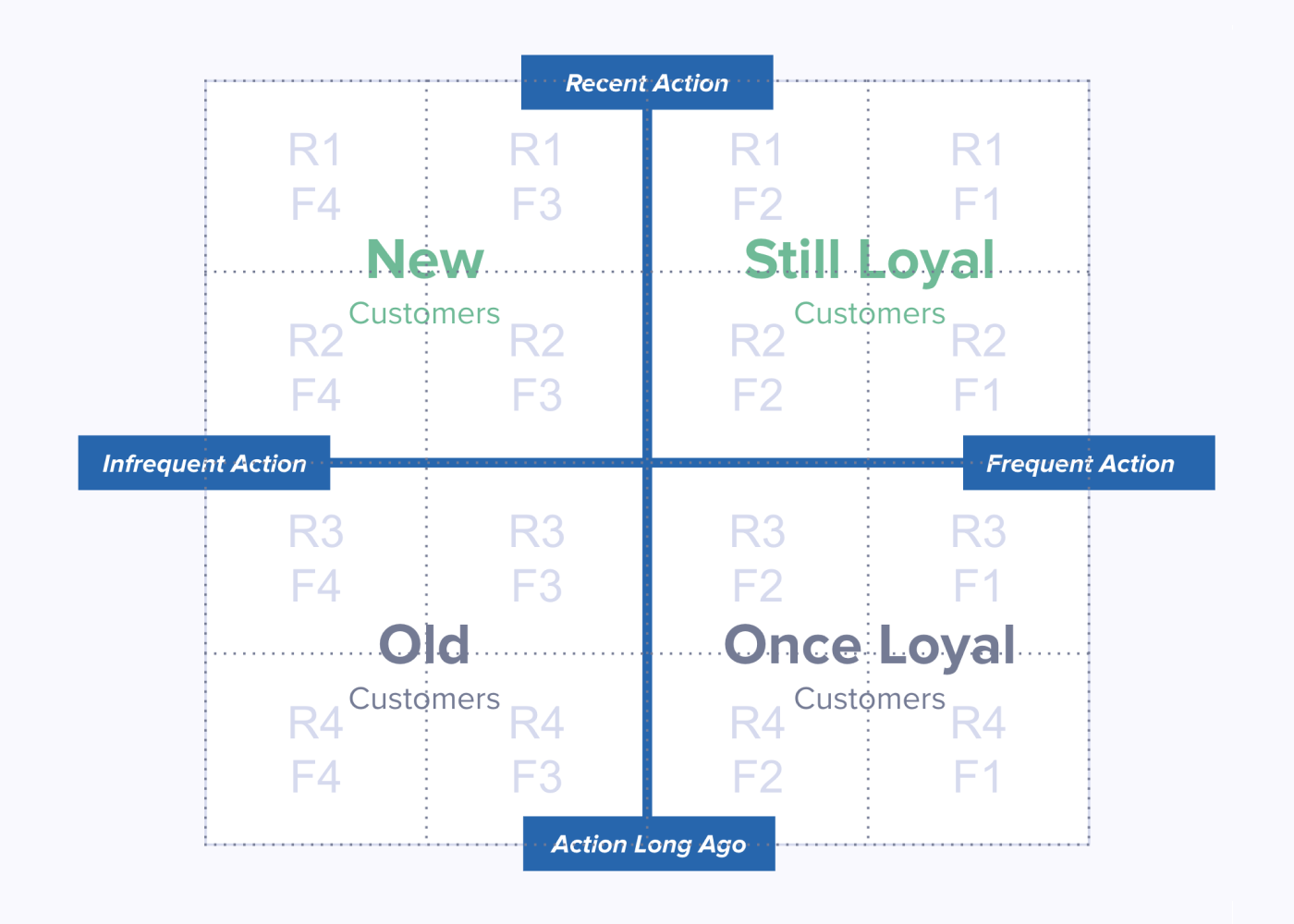
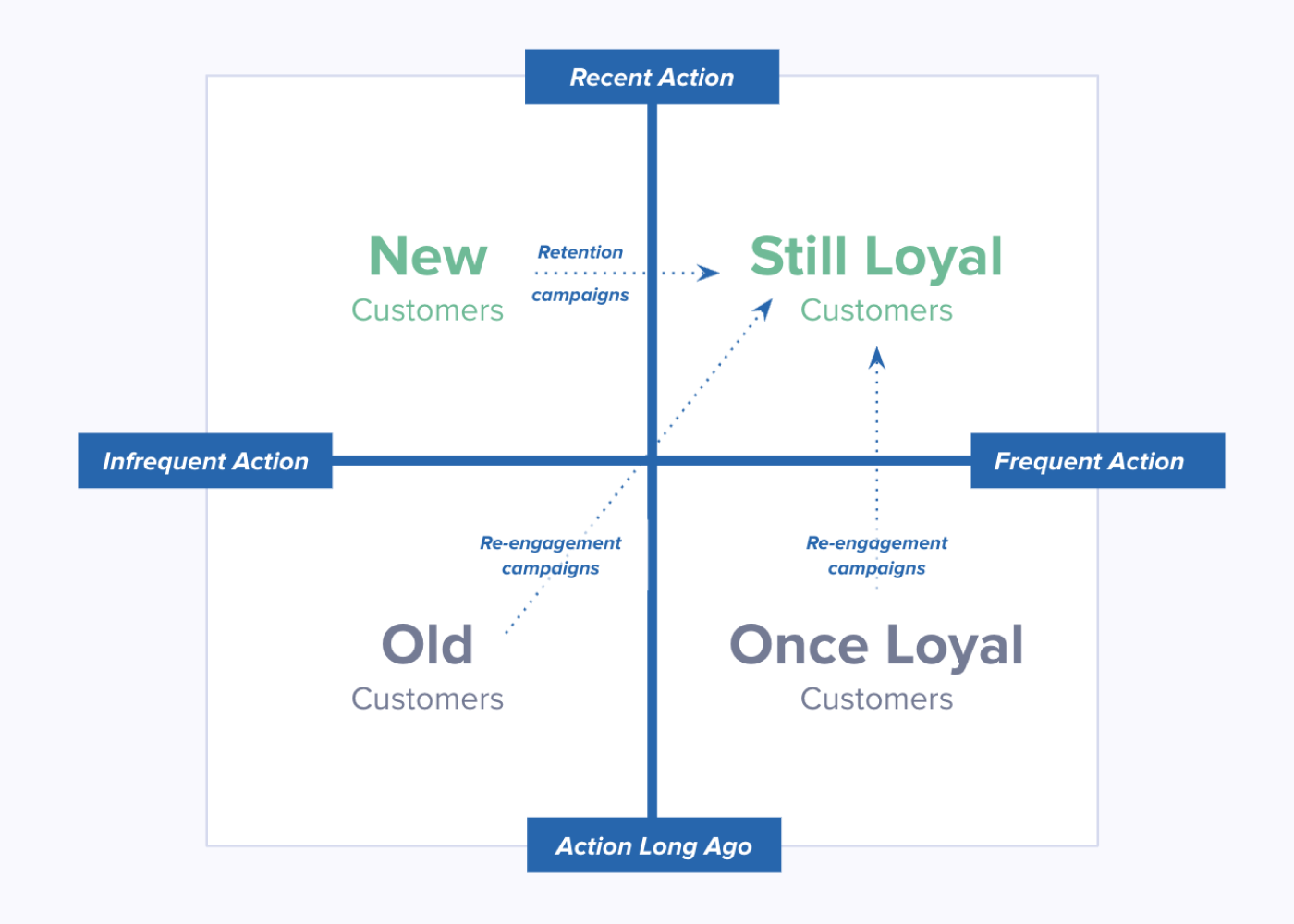
Building an RFM Model
The pitfall that many people face when they try to apply RFM is a classic - they do it themselves instead of letting the data do it for them. For example, they’ll define ranges for each metric manually, usually starting from a hypothetical “best” customer. Maybe they talk to Sales, and find out that high-spend customers usually hit a particular LTV. Or they review last quarters’ data and find out that high-frequency customers made X number of purchases.
A model that results from this kind of process is dangerous. It feels very data-driven, but in fact it’s built on a foundation of guesswork. A salesperson’s idea of a great customer often doesn’t perfectly align with the company’s longer-term view. Similarly, if the data-pull from last quarter included Black Friday, the resulting picture of “good” or “bad” customers’ purchasing habits would be quite distorted.
Setting the accuracy problems aside, the other major downside to this approach is simply time. Surveying salespeople, and working with your data department (if you’re lucky enough to even have one) can constitute the bulk of the time required to build the model.
As you might have guessed, there’s a better way. So let’s put our CDP to work!
Building an RFM Model with Data
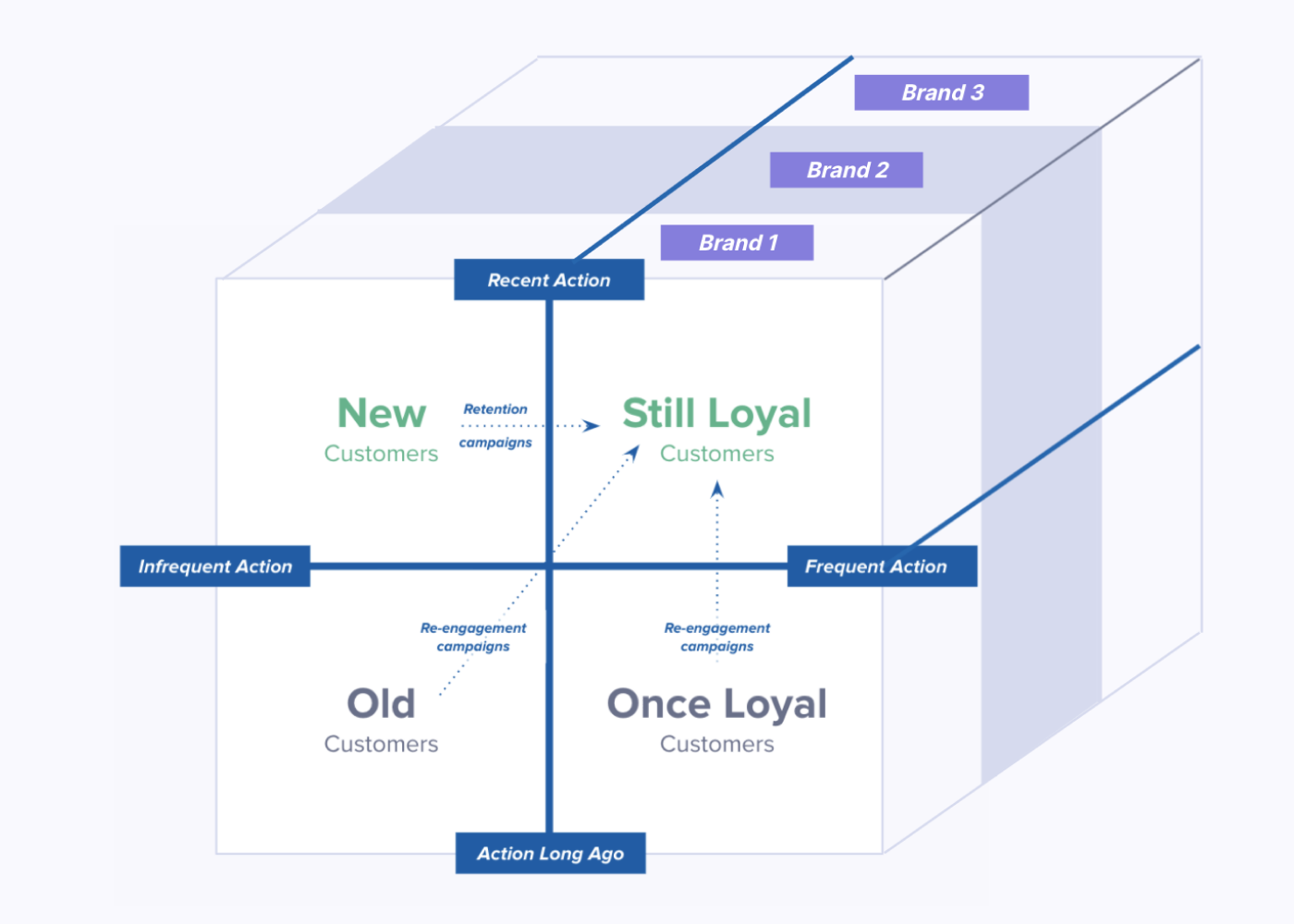
Our intuition is usually that we build a model, then populate it with data, and see what it spits out. However, with the right tools, an RFM model can build itself. Rather than manually defining exact boundaries for our ranges, we can let our data (AKA, the behavior of our customers in the market) establish them organically.
Segment’s Personas product has a feature called SQL Traits, which allows you to query your data warehouse, and define audiences with the results. SQL, in turn, has functions that evenly divide returned results into quartiles, quintiles, deciles, n-tiles. You get an even split, every time, and because that split is based on the live data from your warehouse, it’s always applicable. You build the model once, and it evolves right along with your product, customer base, and market.
Here’s an example query. You can paste this right into Segment, but hold your horses - we’re going to build on this, and we’ve got a unified query at the end. (Note: this query is written around “oc” (Order Completed) events, with a “revenue” property, but you can adjust based on your company’s naming conventions.)