Scaling up reporting on high-cardinality metrics
By Maxime Santerre
Counting things is hard. And it gets even harder when you have millions of independent items. At Segment we see this every single day, counting everything from number of events, to unique users and other high-cardinality metrics.
Calculating total counts proves to be easier since we can distribute that task over many machines, then sum up those counts to get the total sum. Unfortunately, we can’t do this for calculating cardinality since the sum of the number of unique items in multiple sets, isn’t equal to the number of unique items in the union of those sets.
Let’s go through the really basic way of calculating cardinality:
This works great for small amounts of data, but when you start getting large sets, it becomes very hard to keep all of this in memory. For example, Segment’s biggest workspaces will get over 5,600,000,000 unique anonymous_id in a month.
Let’s look at an example of a payload:
Quick maths:
Oof.
Another big issue, is that you need to know which time range you want to calculate cardinality over. The number of unique items from February 14 to February 20 can be drastically different than February 15 to February 21. We would essentially need to keep the sets at the lowest granularity of time we need, then merge them to get the unique counts. Great if you need to be precise and you have a ton of time, not great if you want to do quick ad hoc queries for analytics.
Thankfully, we’re not the first ones to have this issue. In 2007, Philippe Flajolet came up with an algorithm called HyperLogLog, which could approximate the cardinality of a set using only a small, constant amount of memory. HyperLogLog also allows you to increase this amount of memory to increase accuracy by using more memory, or to decrease memory at the cost of accuracy if you have memory limitations.
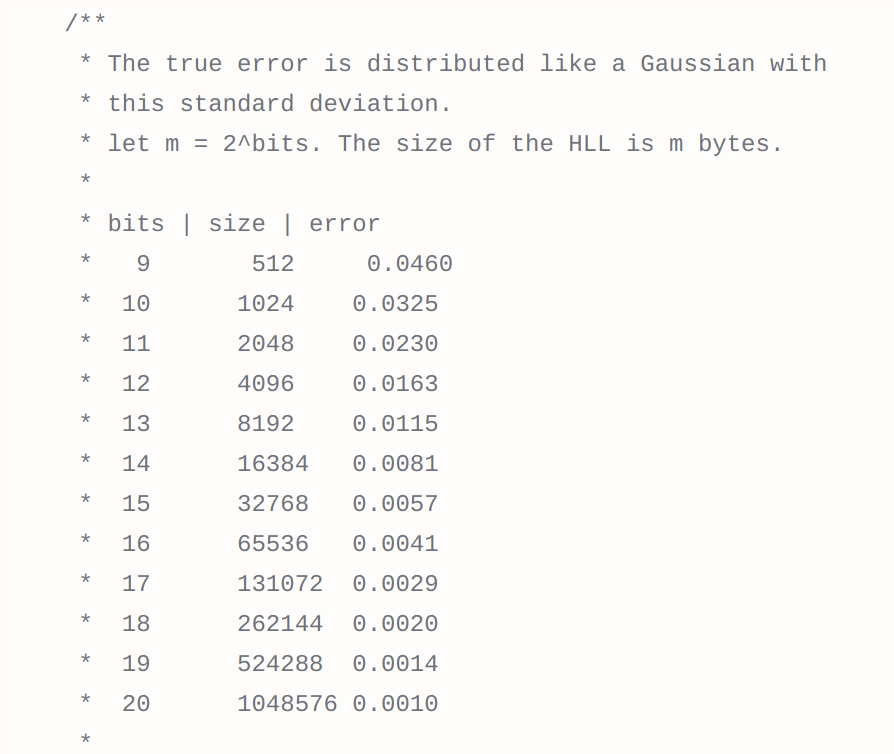
16kb for 0.81% error rate? Not too bad. Certainly cuts down on that 134.4GB we had to deal with earlier.
We initially decided to use Redis to solve this problem. The first attempt was a very simple process where we would take every message out of a queue and put it directly into Redis and then services would call PFMERGE and PFCOUNT to get the cardinality counts we needed.
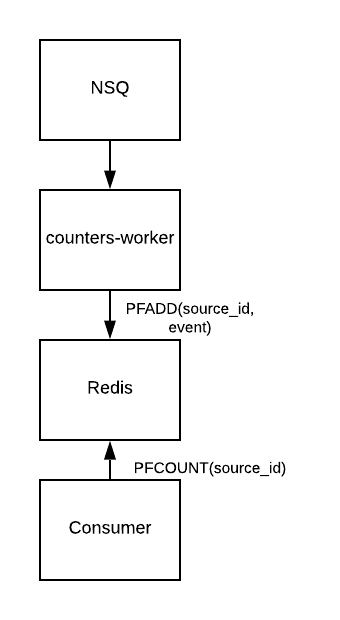
This worked very well for our basic needs then, but it was hard for our analytics team to do any custom reporting. The second issue is that this architecture doesn’t scale very well. When initially got to that point, our quick fix was this:
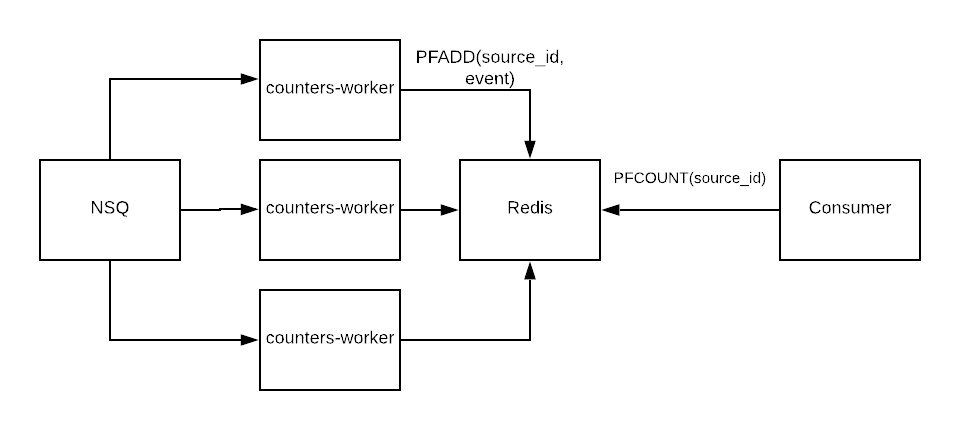
Not ideal, but you would be surprised how much we got out of this. This scaled upwards of 300,000 messages/s due to Redis HLL operations being amazingly fast.
Ever so often, our message rate would exceed this and our queue depth would grow, but our system would keep chugging along once the message rate went back down. At this point we had the biggest Redis machine available on AWS, so we couldn’t throw more money at it.
The maximum queue depth is steadily increasing every week and soon we will always be behind. Any kind of reporting that depends on this pipeline will become hours late, and soon maybe even days late, which is unacceptable. We really need to find a solution quickly
We already used Spark for our billing calculations, so we thought we could use what was there to feed into another kind of reporting.
The problem with the billing count is that they’re static. We only calculate for the workspace’s billing period. It’s a very expensive operation that takes every message for a workspace and calculates a cardinality over the user_id and anonymous_id for that exact slice. For some bigger customers, that’s several terabytes of data, so we need big machines, and it takes a while.
We previously used HLLs to solve this problem, so we’d love to use it again.
The problem is: How do we use HLLs outside of Redis?
Our requirements are:
We need a way to calculate cardinality across several metrics.
We need to be able to store this in a store with quick reads.
We can’t pre-calculate cardinality, we need to be able to run ad-hoc queries across any range.
It needs to scale almost infinitely. We don’t want to fix this problem again in a year when our message rate doubles.
It needs very little engineering resources.
(Optional) Doesn’t require urgent attention if it breaks.
We want something reliable and easy to query, so we think of PostgreSQL and MySQL. At that moment, we find they are equally fine, but we choose MySQL because we already have one to store reporting data and the clock is ticking .
We use Scala for our Spark jobs, so we settle on Algebird to compute HLLs. It’s an amazing library and using it with Spark is trivial, so this step was very smooth.
The map-reduce job goes like this:
On every message, create a HLL out of every item you want cardinality metrics on and return that as the result of your key/map.
On the reduce step, add all of the HLLs resulting from the map.
Convert the resulting HLLs to the bytes representation and write them to MySQL.
Now we have all the HLLs as bytes into MySQL, we need a way to use them from our Go service. A bit of Googling around led me to this one. There were no ways of directly injecting the registers, but I was able to add it pretty easily and created a PR which will hopefully get merged one day.
The next step is to get the registers and precision bits from Algebird, which was very simple. Next, we just take those bytes and make GoHLL objects that we can use!
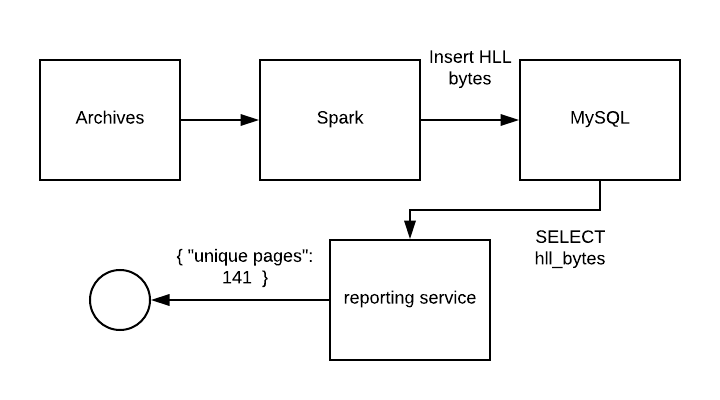
Sweet! Now we can calculate cardinality of almost anything very easily. If it breaks, we fix the bug and turn it back on without any data loss. The worse that can happen is data delays. We can start using this for any use case: Unique events, unique traits, unique mobile device ids, unique anything.
It doesn’t take long for us to realize there’s 2 small problems with this:
Querying this is done through RPC calls on internal services, so it’s not easy for the analytics team to access.
At 16kb per HLL, queries ranging over several days on several metrics creates a big response from MySQL.
The latter being quite important. If we’re doing analysis on all our workspaces multiple times a day, we need something that iterates quickly. Let’s say someone wants to figure out the cardinality of 10 metrics, over 5 sources and 180 days.
We’re pulling down 140 MB of data, creating 9,000 HLLs, merging them, and calculating cardinality on each metric. This takes approximately 3–5s to run. Not a huge lot, but if we want to do this for hundreds of thousands of workspaces, it takes way too long.
So we have a solution, but it’s not ideal.
I sat down at a coffee shop one weekend and started looking around for better solutions. Ideally, we’d want to do this on the database level so we don’t have to do all of this data transfer.
MySQL has UDFs (user defined functions) that we could use for this, but we use MySQL on AWS, and from my research, there doesn’t seem to be a way to use UDFs on Aurora, or RDS.
PostgreSQL on the other hand, has an extension called postgresql-hll, which is available on PostgresSQL RDS.
The storage format is quite different unfortunately, but it’s not as much of a problem since they have a library called java-hll that I can use in my Spark job instead of Algebird. No need to play with the headers this time.
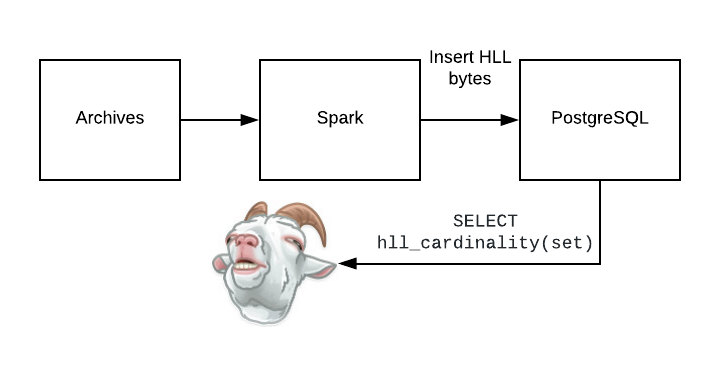
Now we’re only pulling down 64 bit integers for each metric, we can query cardinality metrics with SQL directly, and this pipeline can scale almost infinitely. The best part? If it breaks for some reason at 4am, I don’t need to wake up and take care of it. We’re not losing any data because we’re using our S3 data archives and it can be retried at any time without any queues filling up disk.
So now that we have all of this processing from now going forward, we need to back fill everything back to the beginning of the year. I could take the lazy way and just run the Spark jobs on every day from January 1st 2018 to now, but that’s quite expensive.
I said earlier we didn’t need to play with the headers, but we have an opportunity to save a bit of money (and have some fun) here by taking the HLLs saved in MySQL and transforming them into the postgresql-hll format and migrating them to our new PostgreSQL database.
You can take a look at the whole storage specification here. We’ll just be looking at the dense storage format for now.
Let’s look at an example of HLL bytes in hexadecimal: 146e0000000…
The first byte: 14 is defined as the version byte. The top half is the version and the bottom is the type. Version is easy, there’s only one, which is 1. The bottom half is 4, which represents a FULL HLL, or what we’ve been describing as dense.
The next 2 bytes represents the log2m parameter and the registerWidth parameter. log2m is the same as precision bits that we’ve seen above. The top 3 bits represents registerWidth - 1 and the bottom 5 represents log2m. Unfortunately, we can’t do this directly from the hex, so let’s expand it out to bits:
The rest are the HLL registers bytes.
Now that we have this header, we can easily reconstruct our MySQL HLLs by taking their registers and prefixing those with our 146e header. The only thing we need to do is take all of our existing serialized HLLs in MySQL and dump them in this new format in PostgreSQL. Money saved, and definitely much fun had.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.