The Tag Manager has gained in popularity over the years, and for good reason. It’s a free tool that lets marketers manage and deploy pieces of code onto their websites. Tag managers are events-based and can track customer information across websites and mobile devices, helping marketers to better understand their customer’s behavior and provide a stronger experience.
But wait, doesn’t a Customer Data Platform (CDP) do the same thing?
Yes and no. Both tools have similar functionalities and share deeper insight into customer behavior. In fact, a lot of our customers use Twilio Segment’s CDP in conjunction with Tag Manager. In this blog, we will cover the history of website tracking, how the technologies work, similarities and differences between tag managers and CDPs, and their use cases.
Introducing the tracking pixel
It all started with the tracking pixel in the 1970s. These pixels were a 1x1 size (usually transparent) image that downloaded when an HTML page (web or email) rendered. When the web pages loaded, they allowed for communication with the origin server that logged personal information about the visitor and the actions they took.
As it transpired, tracking pixels uncovered very helpful information for marketers:
Operating system used (gave information on the use of mobile devices)
Type of website or email used (ex. on mobile or desktop)
Type of client used (ex. a browser or mail program)
Client’s screen resolution
Time the email was read or website was visited
Activities on the website during a session (when using multiple tracking pixels)
IP address (gave information on the Internet Service Provider and location)
The use of tracking pixels was beneficial for website operators, SEO specialists, and email marketers. The information generated from the pixel helped improve a company’s understanding of its customer to provide stronger online offers, more user-friendly marketing, and interface customizations to the most commonly used browser types and versions.
As the internet became more complex, we saw increased usage of JavaScript to keep up, which allowed a website to render in real time and better track customers. Pixels recorded when a page was loaded, however it was very limited in the information it could capture and send to the marketer.
Represented as a code snippet, JavaScript tags allowed marketers to record and track user actions (like products viewed or items added to cart) in more detail.
JavaScript tags had their own shortfalls, though. Their iterations lacked a version history (think GitHub) so technical teams had no easy way to collaborate or recover from mistakes (think Microsoft Word circa 1995) and no safety net to A/B test. Also, just a little minor issue 😉, all of this was done in the production environment leading to the inevitable garbage in = garbage out.
Marketers needed a solution that would track multiple events and also allow for experimentation. In 2016, the tag manager entered to improve the user experience.
The dawn of the tag manager
Tag managers are tools that allow marketers to control different scripts and pixels (also called “tags”) through a slick user interface with version control and without the need to access a website’s source code (aka self-serve for a technologist).
Unlike the graffiti of scripts and pixels from the bygone era, a tag manager’s version control allowed for roll-backs from bad implementation, collaboration between owners, and a history audit for posterity. Their self-serve features were a dream come true to marketers who wanted the power of new data collection methods quickly with some level of permissioning for a cohesive strategy.
These tag managers are usually initialized by a small code snippet inserted into the header, called the container tag. Once the container tag was loaded in the browser, users could control various vendor tags using the tag manager’s UI. Tags inside the tag manager could be fired based on action triggers that occurred on the website - actions like pages viewed, buttons clicked, or forms submitted.
To make the data collection and experience dynamic, tag managers also maintain a javascript object in the browser memory that references information from a site’s HTML, called a data layer. An example of the data layer for an ecommerce store is the ability to recall the product price, color, size information, and browser context. Additionally, every time a user or browser behavior occurs, the data layer will log them as events that can be used as action triggers. For example, trigger a Facebook conversion event when a user subscribes to a newsletter.
The best way to understand the power of a tag manager would be to explore a tag manager ecosystem. A reference point would be the world of Google, which provides Google Tag Manager (GTM). GTM’s tooling sent information to Google Analytics can help create basic dashboards, quickening GTM’s time to value. And we can’t forget Google Ads, which combined with GTM, helps marketers create remarketing campaigns that turn leads into conversions.
A tag manager organizes different scripts from various vendors and provides rule based triggering to fire the scripts at the right time. These integrations and tracking tools are starting to sound like the value proposition of a CDP, don’t they?
Is a CDP a tag manager?
In a way. A CDP is similar to a tag manager because they both allow you to collect data from website visitors.
However they are fundamentally different. CDPs not only allow users to instrument event tracking with the mechanisms to ensure consistent and clean data across every environment (beyond just the web, as seen in a tag manager), but also let’s you actually collect the data rather than daisy chain a smattering of third-party scripts affecting page speed. Overall, CDPs simplify your technology stack, deployment, and the management of different tools used resulting in less maintenance.
Ultimately, tag managers and CDPs require a different setup, but both have their advantages.
Tag managers were created originally to help solve the problem of handling an ever growing list of MarTech scripts. Marketers could employ advanced triggering logic without knowing code and effectively instrument multiple vendors without pulling in a software engineer. They are built for the web and have centralized management of data sources.
Built to save engineering resources time, marketing self-service tech in fact did, and continues to do, the opposite.
To capture and analyze data requires strategy across multiple teams and responsibilities. With marketers working on their own, silos between marketing and engineering are often created and exaggerated. Marketing collects the data that they want, but doesn't always provide priority context. This most often results in a ballooning number of scripts from tools that affect site performance and reliability - especially as websites depend more and more on javascript.
But, what about the CDP?
The CDP model requires more input upfront, but ensures that all responsible stakeholders are involved in the data collection process. Engineers are required in the initial setup as they understand and can shed light on how the CDP plays into your team’s tech stack, however, once implemented, it’s as simple as a toggle switch to play nicely with your vendor of choice
Engineering can flag if anything is wrong in the CDP’s implementation or make suggestions and provide context on what information would be valuable to collect for the entire business. Another benefit? Engineering teams become more invested in the success of analytics as they can see their work pay off through quantitative feedback.
Ultimately, the success of both tag managers and CDPs require marketing and engineering to work collaboratively. It’s up to your company to allocate resources and determine your preferred way to operate. Companies that invest in both a tag management system and a CDP are really able to accelerate their marketing efforts.
Segment + Tag Manager implementation
For those who don’t want to pick between a tag manager and a CDP, you’re in luck.
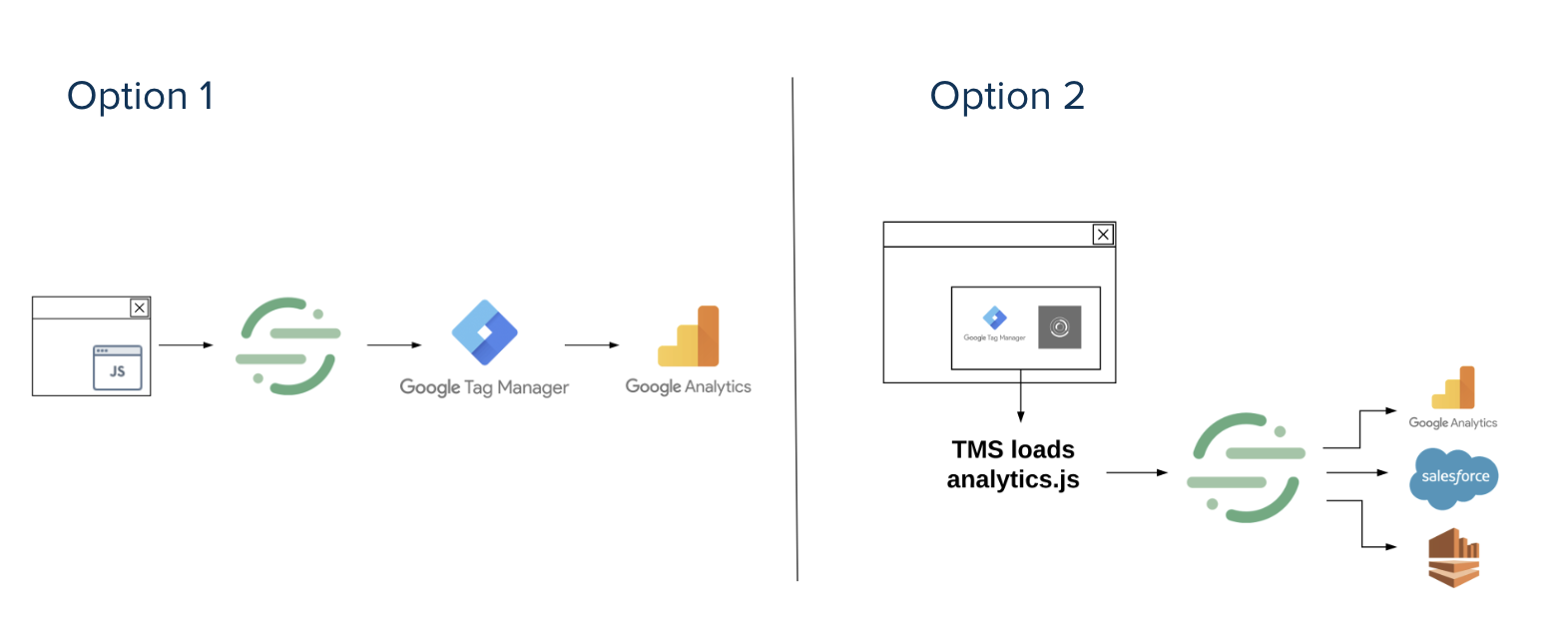
There are two recommended ways to implement Segment with a tag manager in your data stack. The first is to implement Segment in the header and Segment would load the tag manager, leaving the tag manager to perform as usual by loading other scripts. The advantage of this setup is that companies won’t have to reinstrument everything they have in tag manager in Segment. This setup is ideal for companies that have legacy architecture that need to be taken in consideration of timelines.
The other implementation is to have the tag manager trigger Segment, then have Segment push it downstream. The disadvantage, however, is that we can’t guarantee anything before the tag manager that might be causing problems in Segment down the line, but this setup is very possible and plays nice with all technologies involved.