How We Built a Complete Analytics Pipeline From Scratch
By Calvin French-Owen, Chris Sperandio
It wasn’t long ago that building out an analytics pipeline took serious engineering chops. Buying racks and drives, scaling to thousands of requests a second, running ETL jobs, cleaning the data, etc. A team of data engineers could easily spend months on it.
But these days, it’s getting easier and cheaper. We’re seeing the UNIX-ification of hosted services: each one designed to do one thing and do it well. And they’re all composable.
It made us wonder: just how quickly could a single person build their own data analytics pipeline, with scalability in mind, without having to worry about maintaining it? An entirely managed data processing stream?
It sounded like analytics Zen. So we set out to find our inner joins peace armed with just a few tools: Terraform, Segment, DynamoDB and Lambda.
The net result is an entirely managed, scalable analytics pipeline that can pretty easily fit into Amazon’s free tier. The event handling code is just a few lines of javascript… and spinning it up is as easy as running make (check it out on Github).
An analytics pipeline is a series of tools for data collection, processing, and analysis that businesses use to better understand their customers and assess their business performance. Analytics pipelines collect data from different sources, classify it, and send it to the proper storage facility (like a data warehouse) where it’s made accessible to analytics tools.
As a toy example, our data pipeline takes events uploaded to S3 and increments a time-series count for each event in Dynamo. It’s the simplest rollup we could possibly do to answer questions like: “How many purchases did I get in the past hour?” or “Are my signups increasing month over month?”
Here’s the general dataflow:
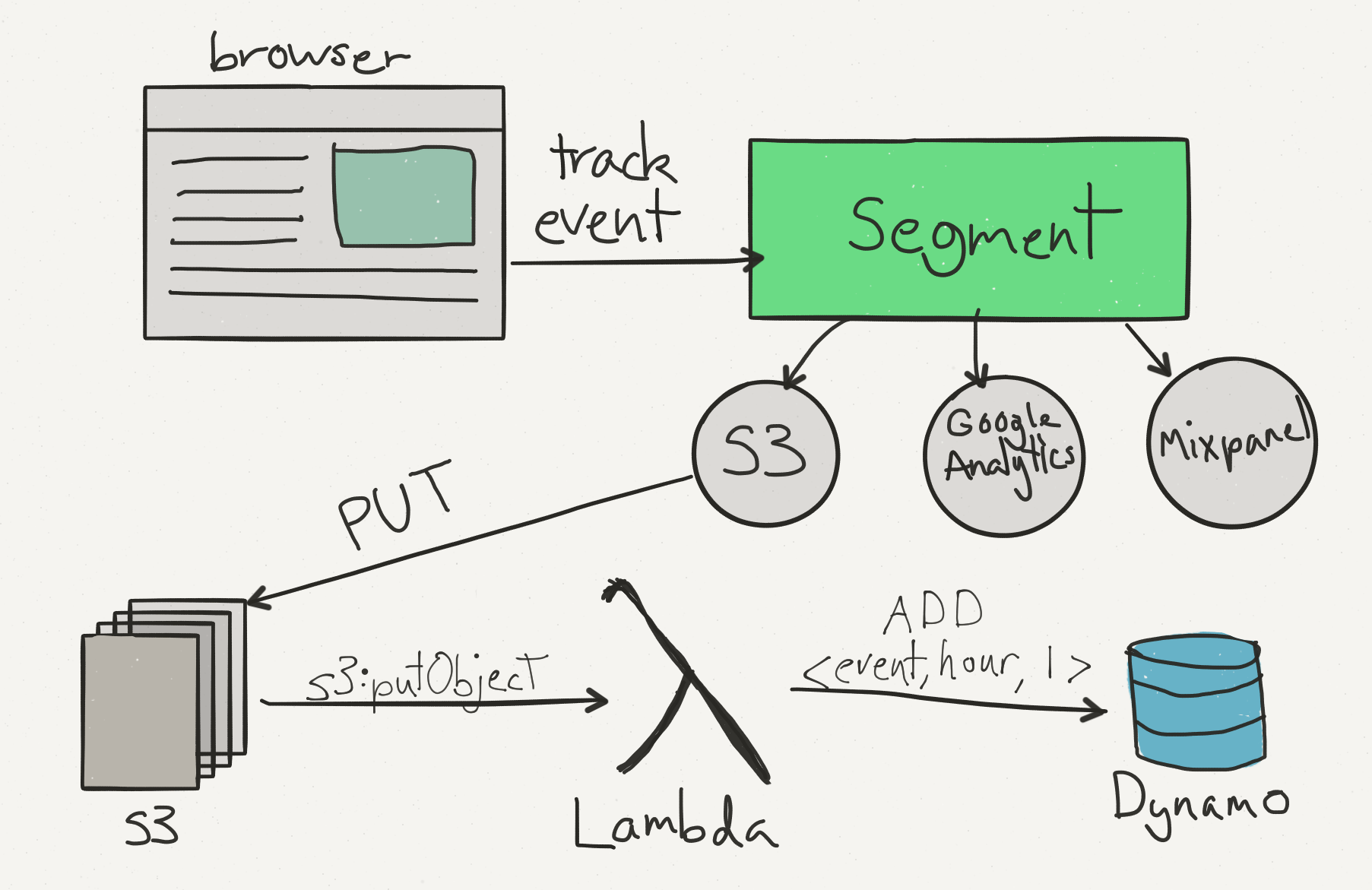
Event data enters your S3 bucket through Segment’s integration. The integration uploads all the analytics data sent to the Segment API on an hourly basis.
That’s where the composability of AWS comes in. S3 has a little-known feature called “Event Notifications”. We can configure the bucket to push a notification to a Lambda function on every file upload.
In theory, our Lambda function could do practically anything once it gets a file. In our example, we’ll extract the individual events, and then increment each <event, hour> pair in Dynamo.
Once our function is up and running, we’ll have a very rudimentary timeseries database to query event counts over time.
It only takes a few lines of javascript to parse the files and pull in the appropriate events:
From there, we’ll handle the incoming events, and update each item in Dynamo:
And finally, we can query for the events in our database using the CLI:
We could also build dashboards on it a la google analytics or geckoboard.
Even though we have our architecture and lambda function written, there’s still the task of having to describe and provision the pipeline on AWS.
Configuring these types of resources has been kind of a pain for us in the past. We’ve tried Cloudformation templates (verbose) and manually creating all the resources through the AWS UI (slooooow).
Neither of these options has been much fun for us, so we’ve started using Terraform as an alternative.
If you haven’t heard of Terraform, definitely give it a spin. It’s a badass tool designed to help provision and describe your infrastructure. It uses a much simpler configuration syntax than Cloudformation, and is far less error-prone than using the AWS Console UI.
As a taste, here’s what our lambda.tf file looks like to provision our Lambda function:
The Terraform plan for this project creates an S3 bucket, the Lambda function, the necessary IAM roles and policies, and the Dynamo database we’ll use for storing the data. It runs in under 10 seconds and immediately sets up our infrastructure so that everything is working properly.
If we ever want to make a change, a simple terraform apply, will cause the changes to update in our production environment. At Segment, we commit our configurations to source control so that they are easily audited and changelog’d.
We just walked through a basic example, but with Lambda there’s really no limit to what your functions might do. You could publish the events to Kinesis with additional Lambda handlers for further processing, or pull in extra fields from your database. The possibilities are pretty much endless thanks the APIs Amazon has created.
If you’d like to build your own pipeline, just clone or fork our example Github repo.
And that’s it! We’ll keep streaming. You keep dreaming.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.