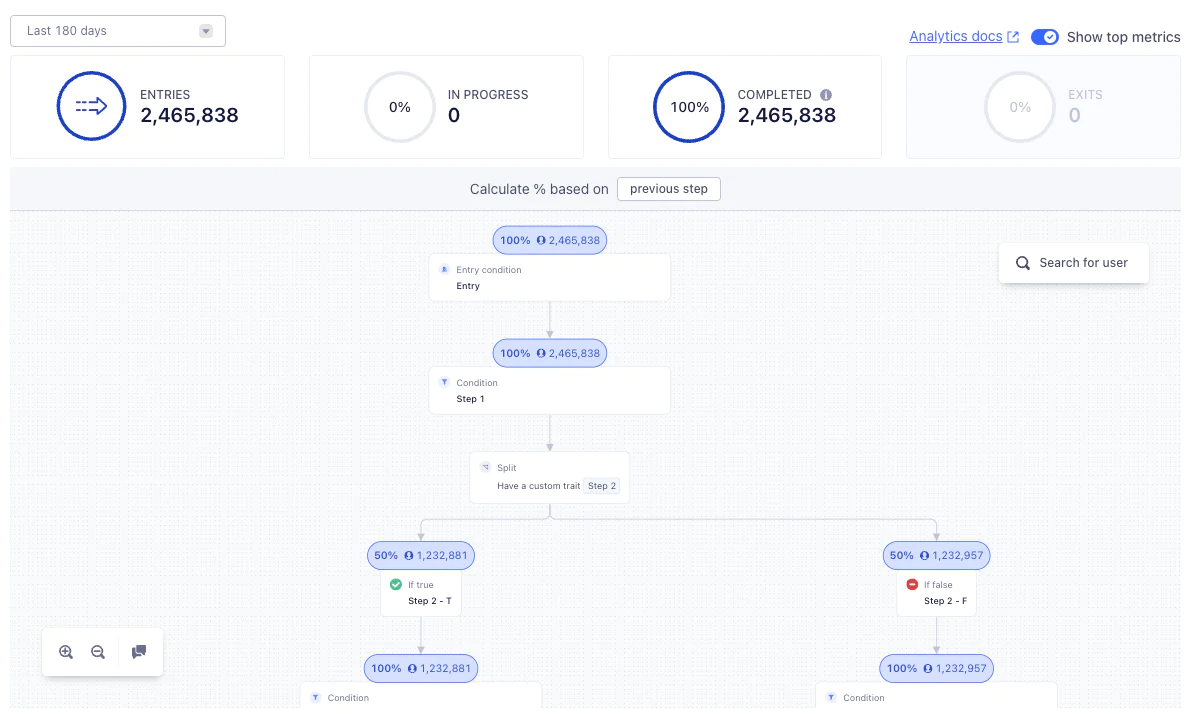
The semantic meaning of this query is to “Find me all unique users for a journey over the last 7 days by event (e.g. entered/completed/exited the journey)”.
Now how could you solve this without SQL? One way is to create a hash table and throw all the user ids in there. Once you’ve iterated through all the records, the key set is your unique set. Assuming this is what ClickHouse does under the hood might explain the large memory consumption on query since many of these large journeys could have 100 million or more unique users and billions of events.
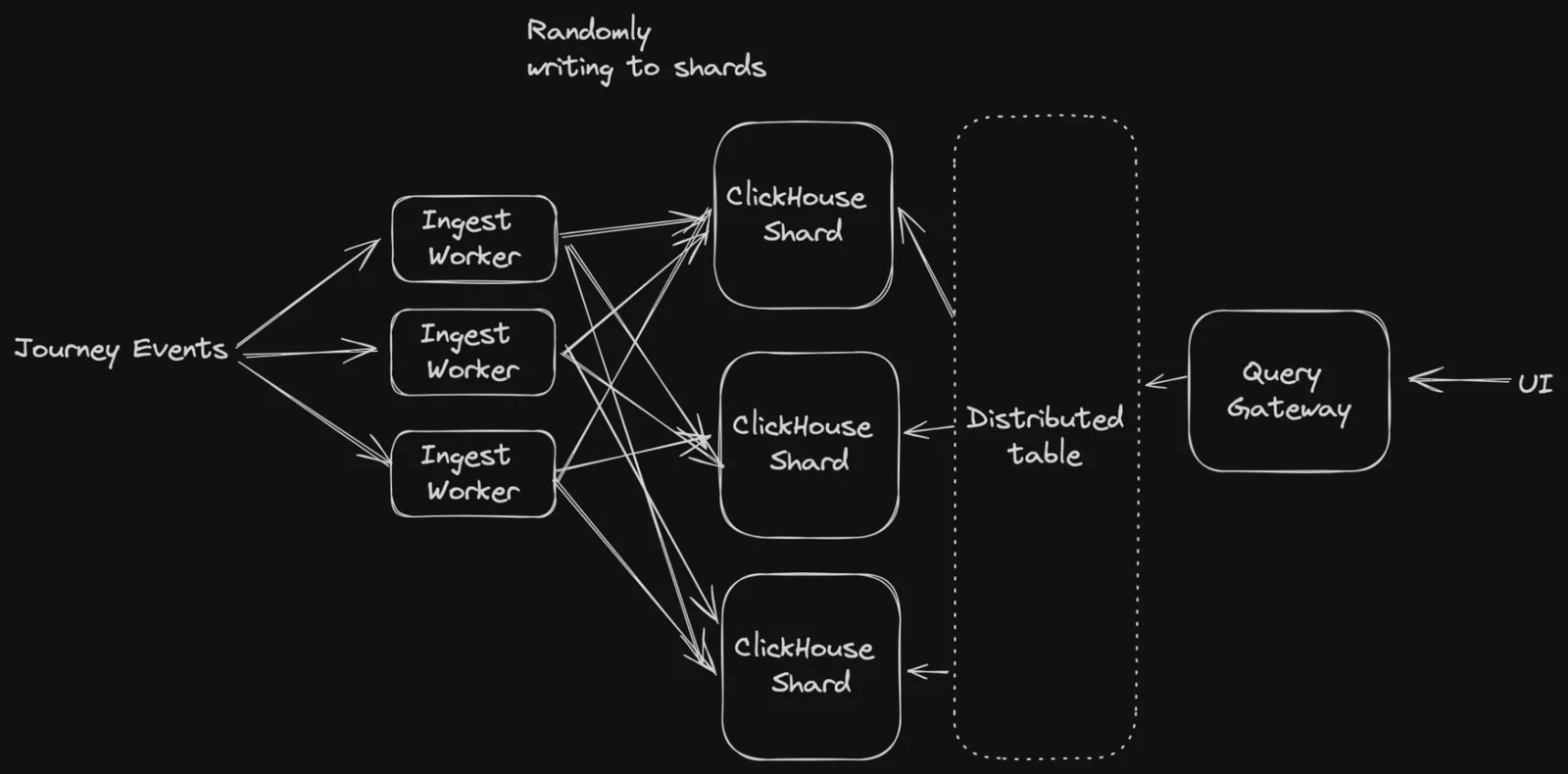
Due to the data being spread across multiple ClickHouse nodes, when you query for unique counts, you have to gather all the rows that are relevant back to the initiator node to perform the uniqueness.
What are potential ways to fix this?
Spill to disk? Even though we are using NVMe instance storage, this was a non-starter because of the perceived drastic performance impact.
Use an approximation algorithm (HyperLogLog, uniqCombined) or sample the data? This was not a viable approach based on the product requirements.
What we came up with:
We wanted to keep the requirement of providing exact unique values for our customers so that they’d have an accurate view of their campaigns. Without the skill set to effectively dive into the ClickHouse code and truly understand what was going on, we had to make a hypothesis of what ClickHouse was doing.
We hypothesized that because we were randomly distributing events across all nodes, the initiating query node would need to pull all Segment IDs to one node. From here, it would build a set to determine the unique keys. One simple way to solve this would be to constantly vertically scale the nodes in the cluster, though this would be cost-prohibitive and give us an effective upper bound of how many events we could process. Could we do something else to maintain a distributed workload and fully use multiple machines?
Semantic sharding:
Instead of randomly placing events on nodes, we could be a bit more clever and ensure that for a given user, they always end up on the same node.
Why would this matter? Imagine if we could guarantee that a user exists on one node at all times. In this case, we could assume that our unique sets wouldn’t have overlap. This gives the nice property of being able to calculate the unique number of users on each node and simply transfer the resulting unique counts from each node to the initiator node and sum those numbers up. This would drastically reduce the memory footprint of calculating uniques per node and the final aggregation would be trivial.
The question now is, how can we actually do this in ClickHouse? Luckily there is a distributed_group_by_no_merge setting that allowed us to do this with a slight tweak of the query. That is, instead of getting one aggregated count we also needed to do a final sum on the query to get the true result.
Implementing this made 100% of our queries usable against any journey at any time range. Previously sluggish 50-second queries now fly at sub-second speeds, unlocking the ability to instantly analyze any journey data near real-time.
Hashing of Filter and Group By Keys:
Another major factor of performance turned out to be how we were filtering and grouping by our UUID keys. All of our UUIDs were 32 character UUID strings. Under the hood, string comparison is of course O(n), so when doing a group by or a filter with a string with billions or trillions of rows, each of those comparisons was O(n) and while the strings would usually start differing rapidly, sometimes the similarities would last several characters into the string. So what was the solution? We started using CityHash64 to turn the strings into integers. Integer comparison is O(1). This reduced the query time by 80%.
What about collisions? With a 64 bit hash, there were 9,223,372,036,854,775,807 possible values. So even with a billion unique values, the odds of collisions were roughly 9 billion to 1. For our use case, we tested with our hashed unique values vs our UUID string values and had the exact same number of unique values, verifying we had no collisions.
Post Optimization Results: