Where is our “package manager for the cloud?”
By Calvin French-Owen
The barrier holding back most open source projects is surprisingly mundane. It’s not test coverage. It’s not performance. It’s not code quality.
No, adoption often comes down to a single question: “is the tool easy to install and use?”
Do I have to re-compile the project from source? Do I have to wait 15 minutes while I fetch hundreds of dependencies? Do I have to download a new package manager? Do I really need a picture of Guy Fieri?
Most open source authors recognize that configuration and setup is a barrier. And yet, we continue to underestimate how large of a barrier it is. The most successful projects make it as easy as possible to install and deploy a tool out of the box.
And some projects nail it; the massive adoption of Bootstrap, Redis, and Rails is largely due to their ‘out-of-the-box’ nature. And we have package managers like yarn , brew , and docker to thank for such an easy setup.
But hundreds of projects don’t have that “zero-to-60-in-5-seconds” approach.
That got me wondering: if package managers have revolutionized how easy it is to install and run software locally, why is it so much harder to get full applications into production? Why is installing a node module trivial, but running full services with a webserver, database, and job queue so difficult?
Where is our “package manager for the cloud?”
Before imagining what a cloud package manager might look like, it’s worth defining some terms. In particular, differentiating packaged infrastructure from managed infrastructure.

Packaging gives the user a consistent means of installing and then running software. Docker images, Debian packages, VMs, and dependency managers all come to mind here. The promise of the package manager is that you install it once, and then run all other code through it.
Managed infrastructure is different. While it is packaged in various ways–the core value proposition is that you don’t handle operations. Instead, hard drive, machine, and system failures are off-loaded to a cloud provider.
As a client, you agree to respect the limits set by whomever is maintaining the infrastructure. And in return, you get a set of guarantees related to uptime, SLOs, and fault-tolerance.
Managed infrastructure is appealing because it reduces the expertise needed to run complex software. It certainly wont excuse poor architecture decisions or bad query patterns. But it is incredible that with a single click, you can create a high-throughput database which automatically handles re-balancing, backups, and scaling.
By using managed infrastructure, you’ve effectively ‘leased’ the expertise of site reliability engineers from Google or Amazon, and am willing to pay a small margin on top of the hardware costs to outsource a large portion of that skillset.
What’s most interesting about cloud primitives like RDS or Cloud Spanner is that outsourcing this expertise puts maintenance in the hands of, well, experts. We’re not talking about your usual “cheap outsourced devshop that churns out PHP apps.” Instead, startups get to borrow from internal teams at Amazon and Google–arguably some of the most experienced engineers on the planet when it comes to running large, multi-tenant infrastructure.
That’s why, for the vast majority of use cases, managed infrastructure just makes sense. It’s not only cheaper, but ultimately more reliable as well.
Of course, leveraging ‘expert knowledge’ is only half the benefit. There’s also the ability to leverage complex (and proprietary) distributed systems like Dynamo or Bigtable. Building your own auto-scaling version of either system requires millions of dollars in R&D. But with the cloud, you can rent hourly access to them for pennies on the dollar.
It’s a trend that is continuing to grow in popularity, and it doesn’t seem to show any signs of slowing.
Unsurprisingly, both packaged and managed software have been undergoing a bit of a renaissance when it comes to new tech. And in particular, local development has been completely re-invented in the last 5 years with the advent of Docker and high-level package managers.
Ever since the rise of containers and Docker, packaging has come a long way.
It’s now relatively trivial to spin up an entire environment that runs only within containers.
Running individual containers is straightforward, simply grab the image you want and supply the right configuration:
But what if you have an entire application run across multiple containers that you would like to coordinate?
As a trivial example, suppose we want to run a Wordpress installation that connects to a database.
One way to do this would be using Docker-compose. You can see that we lay out our two services, one for our DB:
And one for our Wordpress site:
If those are both defined in our docker-compose.yml file, we can then run both containers on any Docker infrastructure using:
Or we could use Kubernetes Pods, which would even get us encrypted secrets automatically injected into the container. We can even grab the full YAML provided in the examples to boot the resources we need.
Because every cloud provider, container startup, and grad student is writing their own scheduler these days, there’s really no limit to coordinating containers. And while each implementation comes with a certain set of trade-offs and quirks, they all do a pretty good job of orchestrating many different services together.
But here’s the weird thing: we’ve had good packaging for a long time and we’ve started to see really nice ways to coordinate infrastructure we manage–and yet, there’s still not a lot of good tools for configuring managed infrastructure.
In the not-so-distant past, there was a reasonable solution to quickly launching managed services: The Heroku Button.
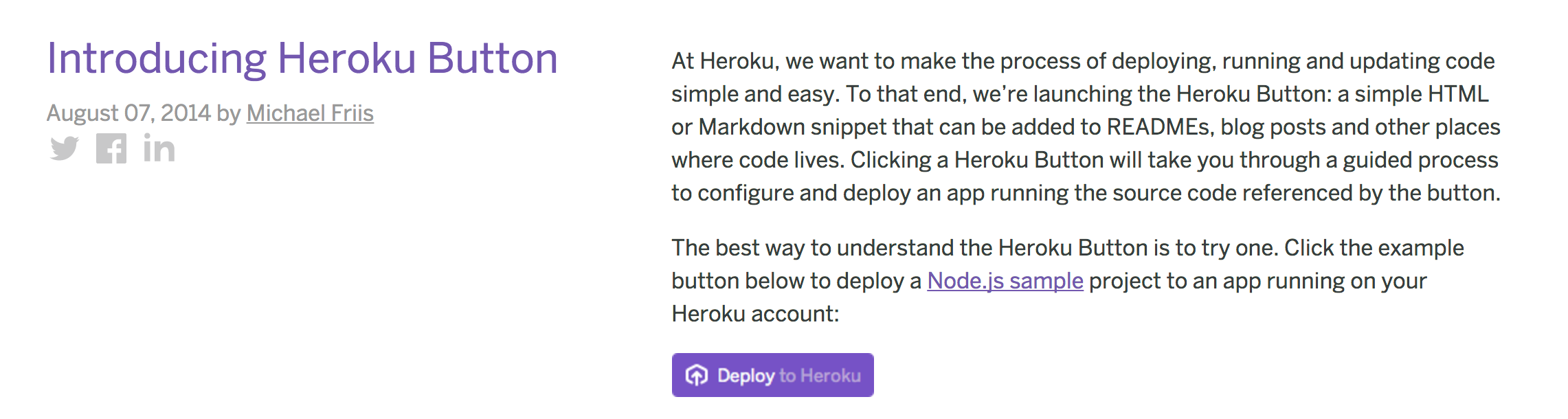
With one click, you could instantly get applications running within your Heroku account, along with whatever databases or queues you’d need. No obscure cron jobs, kernel tuning, or arcane init scripts required.
And that was great. IF you run your infrastructure on Heroku. But if you don’t, it’s a totally different story.
If you’re running on AWS or GCE, now you also have to setup the proper security and network permissions, pay for additional data transfer outside your AWS account, and make sure that Heroku is actually scaling properly. Oh, and it probably uses a totally separate monitoring and logging pipelines.
Unless you end up booting that infrastructure as a one-off or totally separate service, there’s still a lot of work to be done to mold an open source project to run successfully within your infrastructure. We’ve done this three or four times now for Segment–and it’s invariably annoying.
As more companies have transitioned off Heroku and onto the bigger clouds, the simplicity and speed of the Heroku button has really fallen by the wayside. And the need for cross-cloud managed infrastructure has appeared.
So let’s explore the offerings on the market. Each is attacking this problem from a slightly different angle, at different layers of the stack.
Before looking at the different stacks, I’d like to quickly introduce Discourse as a sort of prototypical app that can really benefit from managed infrastructure.
Discourse is an open source platform for community discussion that you can run within your own infrastructure.
Users wanting to run Discourse require three separate processes:
a Ruby on Rails server running Discourse on a single machine
a Postgres server
a Redis server
If this is an internal tool under relatively light load, that’s probably it. But if Discourse is running with a large number of clients, we’ll also need:
a load balancer
auto-scaling rules for the web service
And oh yeah, we’ll probably want some way of backing up that Postgres instance so we don’t drop everything accidentally, as well as a nice way to scale up the number of clients and the size of the database.
Now it’s starting to sound like we either require a full-fledged ops person to spin up this infrastructure, or a nice way of outsourcing it to managed products.
So how can we quickly provision it?
There are a few major players who all seem well-positioned to tackle this problem: Terraform, Kubernetes, and a handful of cloud startups. Each has a different strategic position, so I’d like to explore how each tool can provide cross-cloud managed infrastructure.
The product with the most cross-cloud adoption to date is Hashicorp’s Terraform.
First, a 30-second intro of Terraform: Terraform is a CLI tool for managing cloud resources. You can use it to provision, and then change the configuration of load balancers, auto-scaling groups, instances, and more.
Terraform uses a static DSL to create resources. It then tracks these resources in a “state file” and creates “diffs” between your desired state and the current state of your infrastructure.
Creating instances is simple. As a quick example, the configuration for a bastion resource might look like this:
It has a type (aws_instance) and an identifier (bastion), as well as a bunch of attributes that are passed in as configuration. Whenever we plan and apply, any changes will be modified using the appropriate AWS API to update our resource.
What’s more interesting is that groups of resources can be created together using modules. Modules are re-usable pieces of configuration that will automatically create and manage all the resources within it.
Modules effectively serve as a higher-level API to collections of managed infrastructure. Just what we needed!
As an example for Discourse, we could imagine that the repo itself could package a Terraform folder:
And then anyone interested in booting up Discourse within their own infrastructure could simply reference the module and pass in their own VPC ID.
Internally this module would then create the internal resources that it needs:
Under the hood, it would give us:
auto-scaling instances with an AMI running discourse
a managed RDS instance running postgres with hourly backups
a managed elasticache instance running redis
And voila! We have our production infrastructure, ready to go! By referencing the module, and passing in our required infrastructure–Terraform will automatically boot all the pieces that we need.
The best part here is that modules can support multiple providers just by using different Terraform.

Need the GCE version instead? If the author has built an adapter for it, just reference a new path:
Still want our good ol’ Heroku button? No problem, Terraform supports that too (with managed addons):
Under the hood, this might look something like this:
It solves both the problems of running a service within your own infrastructure and relying on managed infrastructure for any team, regardless of whether they use Heroku or not.
Where Terraform is primarily used to provision the ‘base infrastructure’ and machine images, Kubernetes lives at a different part of the stack. It’s a scheduler and service orchestrator–designed to coordinate services both locally and in the cloud.
As a user, you first describe services within Kubernetes, and then install a Kublet (the Kubernetes agent) on each host. Kubernetes will then determine how to optimally utilize the cluster such that multiple containers are run and exposed on each machine.
In short, Kubernetes a scheduler that runs applications and handles service discovery, load balancing, and configuration–all across a cluster of machines.
Ordinarily I wouldn’t even put Terraform and Kubernetes in the same category–since Kubernetes is focused on orchestrating infrastructure that you are responsible for running yourself. It’s not really about booting up managed infrastructure at all.
However, Kubernetes does support one important cloud primitive: managed load balancers. When booting your service, you can specify as part of the pod that it should manage a load balancer to send traffic to:
This load balancer will use the managed load balancers within any of the big clouds: AWS, GCE, Azure, and Openstack to name a few.
By combining primitives like the LoadBalancer with simple package management using Helm charts, Kubernetes is starting to become the common ‘substrate’ that any application can build upon.
The CLI command to install our discourse app might look like this:
As a developer who wants to support Helm, all we’d have to do is add the corresponding Helm charts:
And we’d allow anyone running Kubernetes to immediately run Discourse within their infrastructure.
What makes this approach interesting is the fact that Kubernetes has been gaining so much traction at the application level. It feels like it would be relatively doable to build a Kubernetes service type of Database or ObjectStore that maps to RDS or S3. It could be the trojan horse that slowly beings to spread Kubernetes pods as the ‘unit’ of managed hosting.
That said, there’s an immense amount of work involved to gain the sort of provider coverage that Terraform has. Even with the tight application integration that Kubernetes can provide, moving to support the managed infrastructure of just the major clouds would still be a major undertaking.
As some last food for thought–it seems like there’s a big opportunity here for a startup that manages to smooth over the wrinkles and inconsistencies between various cloud providers.
Imagine if you really could run your infrastructure dynamically on whichever cloud was cheapest. Or whichever provided the lowest latency.
It effectively turns the decision of which cloud to use from an annual procurement to a real-time auction.
There are a handful of startups doing interesting things when it comes to making managed infrastructure more user-friendly:

Convox: Convox provides a CLI and layer for working over AWS. It’s an open source tool that imagines where the fundamental abstraction is ‘applications’ just like Heroku. But unlike Heroku, Convox is built entirely atop an AWS pipeline, leveraging ECS for scheduling, Cloudwatch for logs, and Lambda to coordinate scheduled jobs. Because apps and logs are the core abstraction, Convox isn’t tied to the underlying infrastructure, though it certainly leverages AWS utilities heavily.
Skyliner: Like Convox, Skyliner launched more recently as a nice UI and deploy pipeline that layers over AWS. Their whole pitch is that they will give you a ‘best practice’ AWS setup that’s extremely easy to interface with. While they don’t yet support other clouds, being the ‘owner’ of the customer opens them up to start moving and building higher level primitives that can work across clouds. They ‘own’ the customer in the sense that the user really only interfaces with Skyliner, not AWS.
Zeit: Zeit’s Now takes the most radical approach (and the most similar to ‘serverless’) of these three providers. Zeit provides the user the ability to upload a node module that it will run and host using only a single API command. Zeit abstracts almost all managed infrastructure away from the user, so they aren’t really sure what cloud they are running upon, or what resources are being consumed under the hood. It’s less about managing cloud infrastructure, and more about solving the problem of running code with applications as the focus.
We’ve still yet to see these approaches gain more widespread adoption. But it’s still early days for most of them.
Now, amongst all the rosy ideas of a universal package manager for the cloud, I intentionally skipped past the elephant in the room. Creating ‘one package manager for any cloud’ is incredibly difficult because cloud providers are incentivized to lock-in customers to their platform.
And overcoming that incentive is tough. It’s a good part of the reason why each cloud provider maintains idiosyncratic APIs, workflows, and specialized tooling. It certainly makes the job of a ‘blanket’ API that papers over these inconsistencies difficult at best.
This barrier is particularly acute with pieces of technology that are “hard” to develop. I’m talking about the R&D-heavy efforts behind proprietary platforms like DynamoDB, Cloud Spanner, BigQuery and Redshift.
But that said, there’s a second-order cycle at play with these sorts of expensive pieces of proprietary software. In many cases, we see databases and streaming systems mature along the following milestones:
the software is developed internally at a larger tech company (Google, FB, etc)
the software architecture is published as an academic paper
an open-sourced reference implementation is released
commercial and cloud support follow the tool’s user adoption
You can see it this cycle again and again with the likes of Hadoop, Cassandra, HBase, Kafka, and Kubernetes. All these tools were borne out of companies initially, and then gained widspread adoption over time, either as Apache projects or sponsored directly by the company that conceived them.
As a textbook example, take Hadoop.
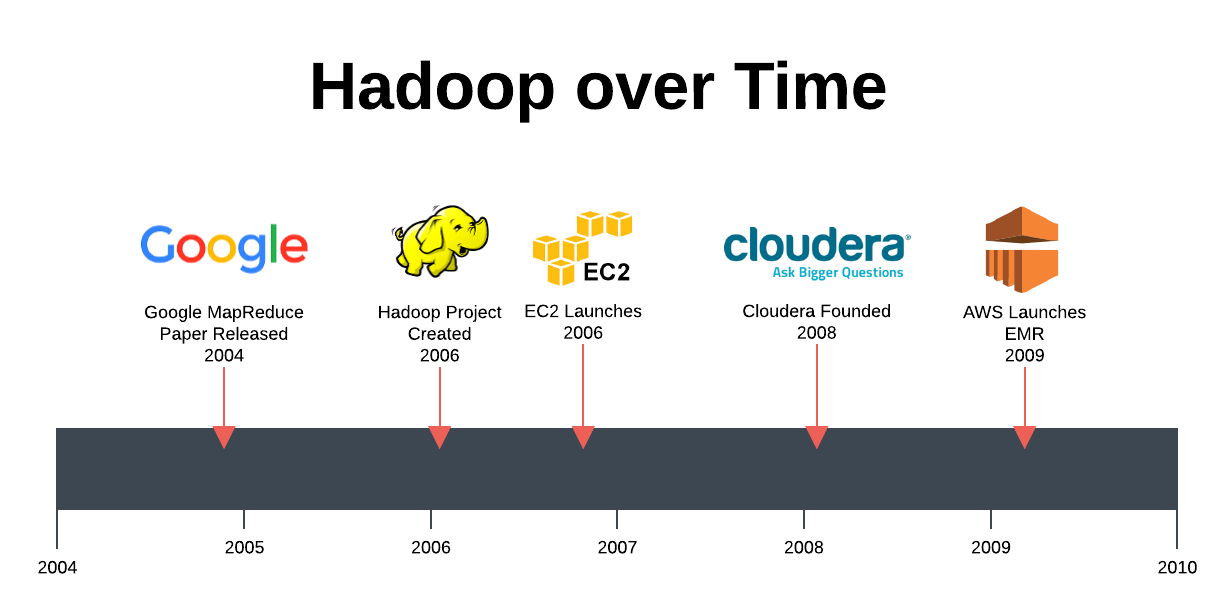
Hadoop’s journey from open source project to managed infrastructure hits the following milestones [2]:
2004 - Google release its MapReduce paper
2006 - Hadoop project is founded as an open source version of MapReduce
2008 - Cloudera is founded to commercially support Hadoop as it gains momentum
And Hadoop isn’t the only example: we’ve started to see the emergence of hosted Kafka on Heroku and Spark on AWS.
It’s software in this cycle that does stand a fighting chance to become cross-cloud infrastructure. Databases like Redis, MySQL, and Postgres are so ubiquitous that they have effectively become table stakes that cloud providers must to offer as managed products.
We’ll continue to see these sorts of products emerge as new technology gains widespread adoption. It would come as no surprise if we started seeing hosted Kubernetes deployments emerging outside of just GCE.
Now, there’s certainly still a lot of ground to be made up when it comes to booting up infrastructure “anywhere” and running applications at a higher level of abstraction than instances and networks. But in a world where it’s so easy to boot similar types of infrastructure in different clouds–there’s a huge opportunity to pave over all those differences and create a unified abstraction layer across all of them.
Instead of treating infrastructure at the machine or even container level–I’m expecting that we’ll start seeing infrastructure where “applications” are the core unit of abstraction. And I’m excited to see how that world plays out.
[1]: Kafka is a great example of this. Simple architecture combined with extremely high throughput. The Kubernetes architecture is another one that allows people to build on it quickly. But these seem to be the exception rather than the rule.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.