Compared to the more traditional “simple messaging” model or “publisher-subscriber” model, event-streaming is widely seen as the superior technology in event-driven architecture. It is regarded as more flexible and reliable as it not only decouples the producer from the consumer, but the data itself too. Consumers can “read” the persisted data whenever they need it rather than simply being sent the data at one fixed point in time. Here is a quick comparison between the two:
-
With the publisher-subscriber model, all subscribers to an event will receive it from the producer when the event gets created or “published”. Think of the data being pushed downstream. Data is not persisted and is “lost” once pushed to the consumer.
-
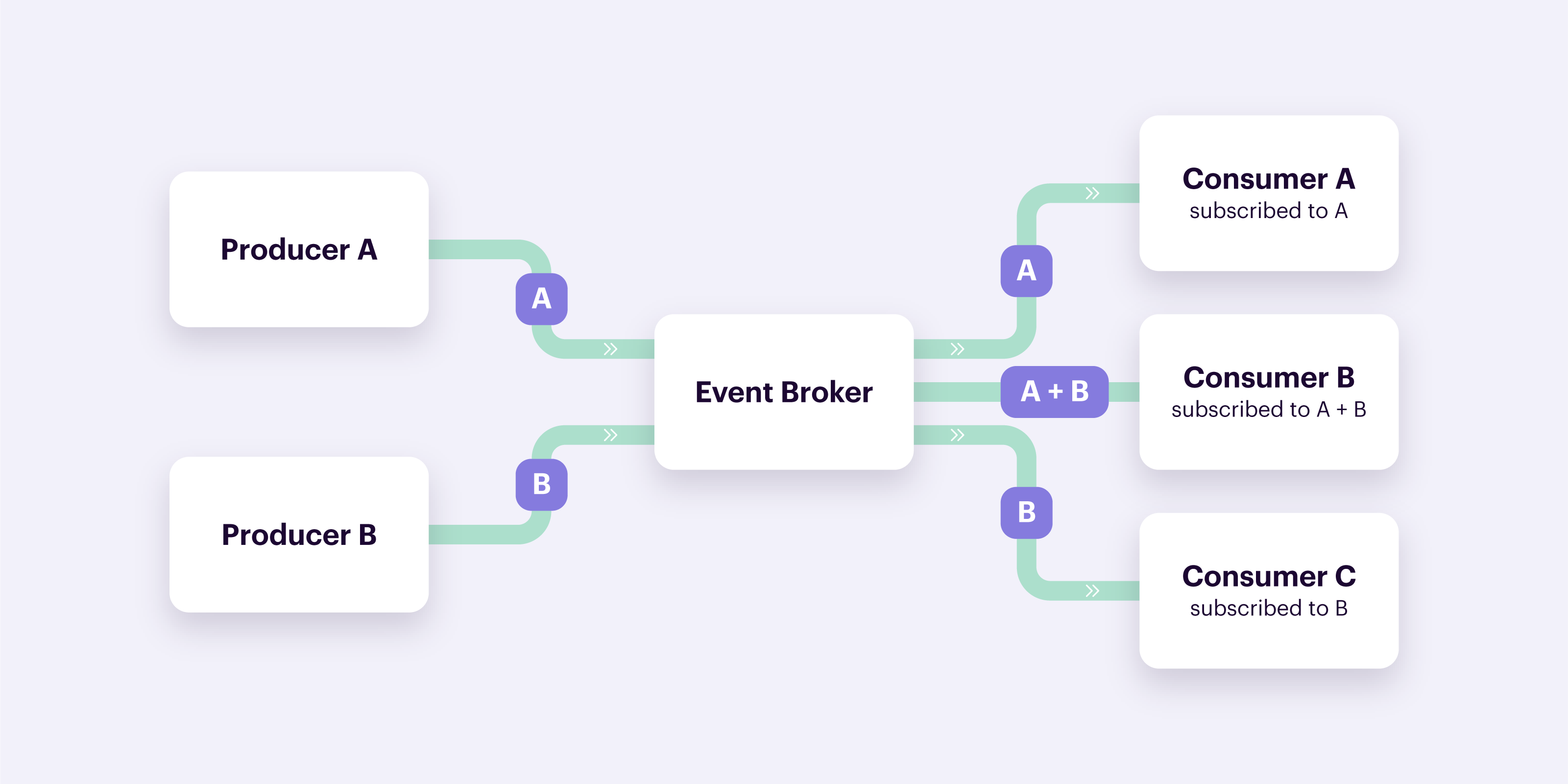
Event streaming allows events to be stored in a log (event stream). Producers write to the log, brokers organize the data, and consumers "read" from the log, on their own independent schedule and position. Think of data being pulled. This ensures that data is persisted and can be “replayed” if errors occur.
Within event streaming, one technology has firmly manifested itself as a component of choice for companies such as Zalando, Pinterest, Adidas, Airbnb, and Spotify to name just a few. This technology is called Apache Kafka.
Apache Kafka
Apache Kafka is the world’s most prominent event streaming platform. Since being created and open-sourced by LinkedIn in 2011, Kafka has been adopted by thousands of companies, including more than 80% of Fortune 100 businesses (according to Apache Kafka). It’s highly flexible and can be deployed on-premise as well as in cloud environments. Kafka is most commonly used to power event-driven architecture by providing event streaming pipelines that help companies capture, process, and deliver data at unprecedented speed, scale and cost.
Here at Segment, we use Kafka too. Our infrastructure uses multiple Kafka clusters, serving more than 8 million messages per second on average, allowing us to provide customers a service that simplifies collecting, processing, and delivering events to all tools that rely on first–party customer data. We’ve spent 10 years optimizing our infrastructure to send trillions of events per month exactly once to over 400 different out of the box destinations, guaranteeing high–quality data and creating 360 degree views of customers through identity resolution. All of this relies heavily on Kafka. - Julien Fabre, Principal Site Reliability Engineer
Customer data platforms
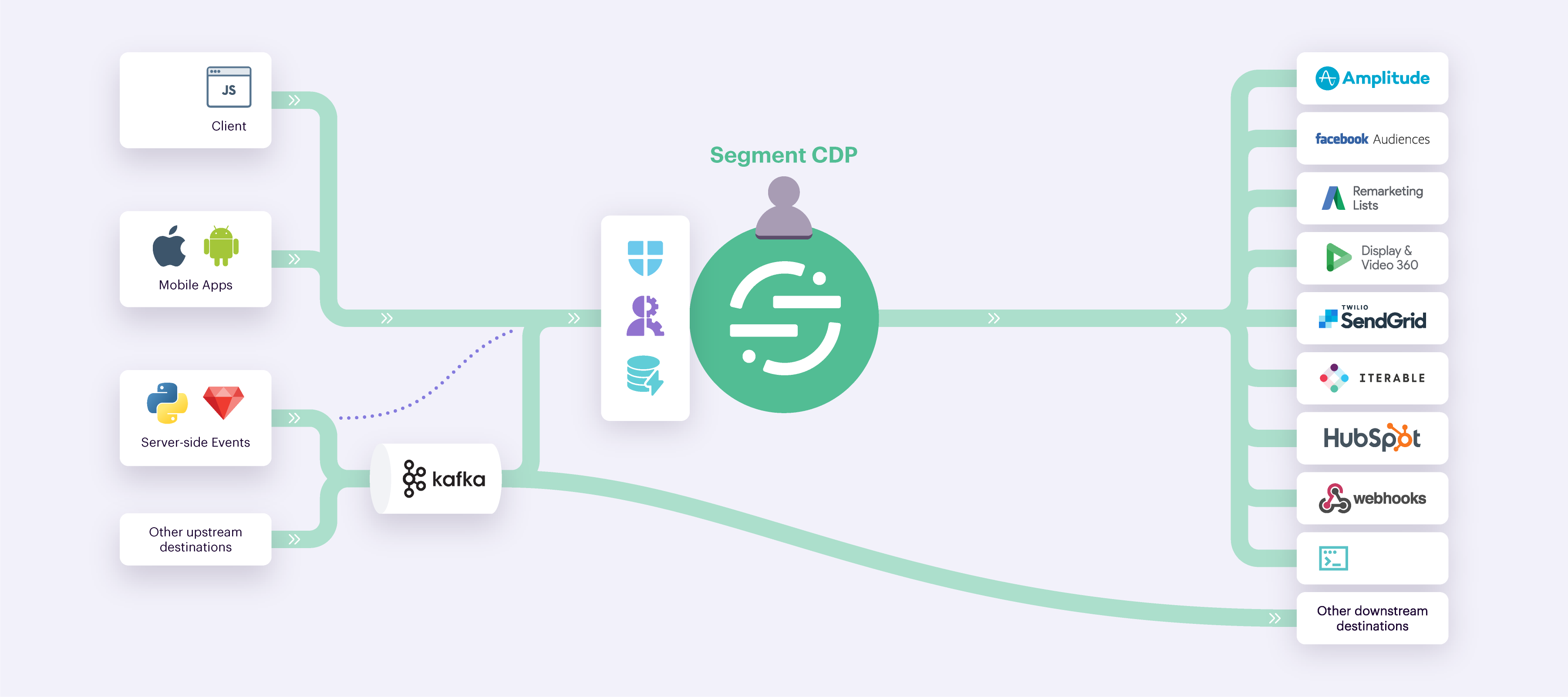
But a service like Kafka really comes into its own when paired with a customer data platform like Segment. A Customer Data Platform (CDP) provides organizations the ability to decouple data collection from data delivery. With one standardized tracking API, regardless of where the data comes from and what its intended destination is, events get tracked once and in the case of Segment delivered with a simplified UI to over 350 destinations. All of that without ever having to touch a tool’s code.
-
Not all of your customer data sources will be server-side and neither will be your destination systems. Segment’s data collection libraries standardize the data capture beyond Kafka to web and mobile, and can easily bundle and translate events to third parties from the client directly, when needed.
-
Event validation raises alerts for malformed or corrupted events, transformations allow for fixing of said events, and schema controls provide blocking capabilities. This means that the data quality of events processed by Kafka can be enforced before they ever make it downstream.
-
A customizable identify graph allows companies to automatically organize their events into user profiles, without having to rely on costly database joins or other forms of analysis to create a single view of the customer. Think of a user logging into your e-commerce storefront, but completing the order on mobile.
-
Rarely do we find that all customer intelligence can be self-contained in events themselves, so Segment provides trait computation capabilities. With trait computations, you can look across events and gain further customer intelligence attached to individual users or companies for B2B use-cases. Our customers are often interested in aggregations such as “Lifetime Value”, “Number of logins in the last 14 days” or “Most frequently viewed product category”.
-
In addition to calculating across events, a lot of customer intelligence sits in Data Warehouses. Segment’s SQL traits are a powerful way to directly query and enrich customer profiles with additional insights, computations, and data stores managed within the data warehouse.
-
Once events are layered with advanced intelligence, many organizations look to cluster or segment users into addressable audiences. Segment provides both the ability to execute this segmentation and the subsequent integration of the Segment into the wider tech stack. Said integration can be done on a per-audience basis or Journeys can be designed to orchestrate and iterate on entire end-to-end customer experiences across your entire tech stack with real-time engagement logic.
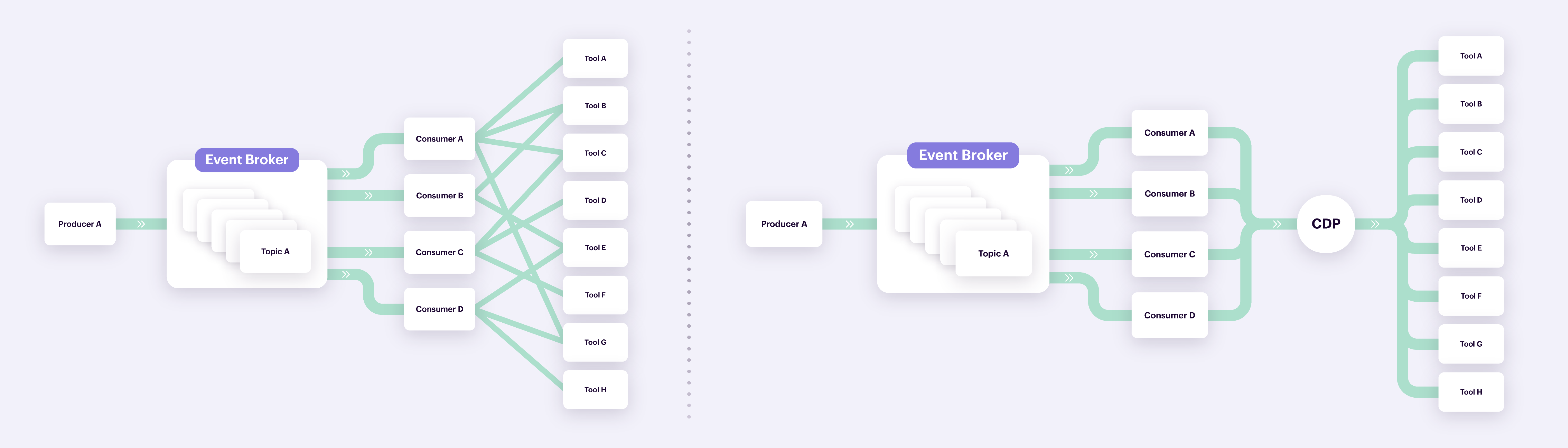
Now that we have established the concepts of Apache Kafka and what capabilities a CDP brings to the table, let’s take a look at how a CDP can help reduce the complexity of integrating your Apache Kafka stream with your wider tech stack.
Going from point-to-point with Apache Kafka to a centralized approach with a CDP
Let’s circle back to the example from earlier where a customer places an order on an e-commerce website.
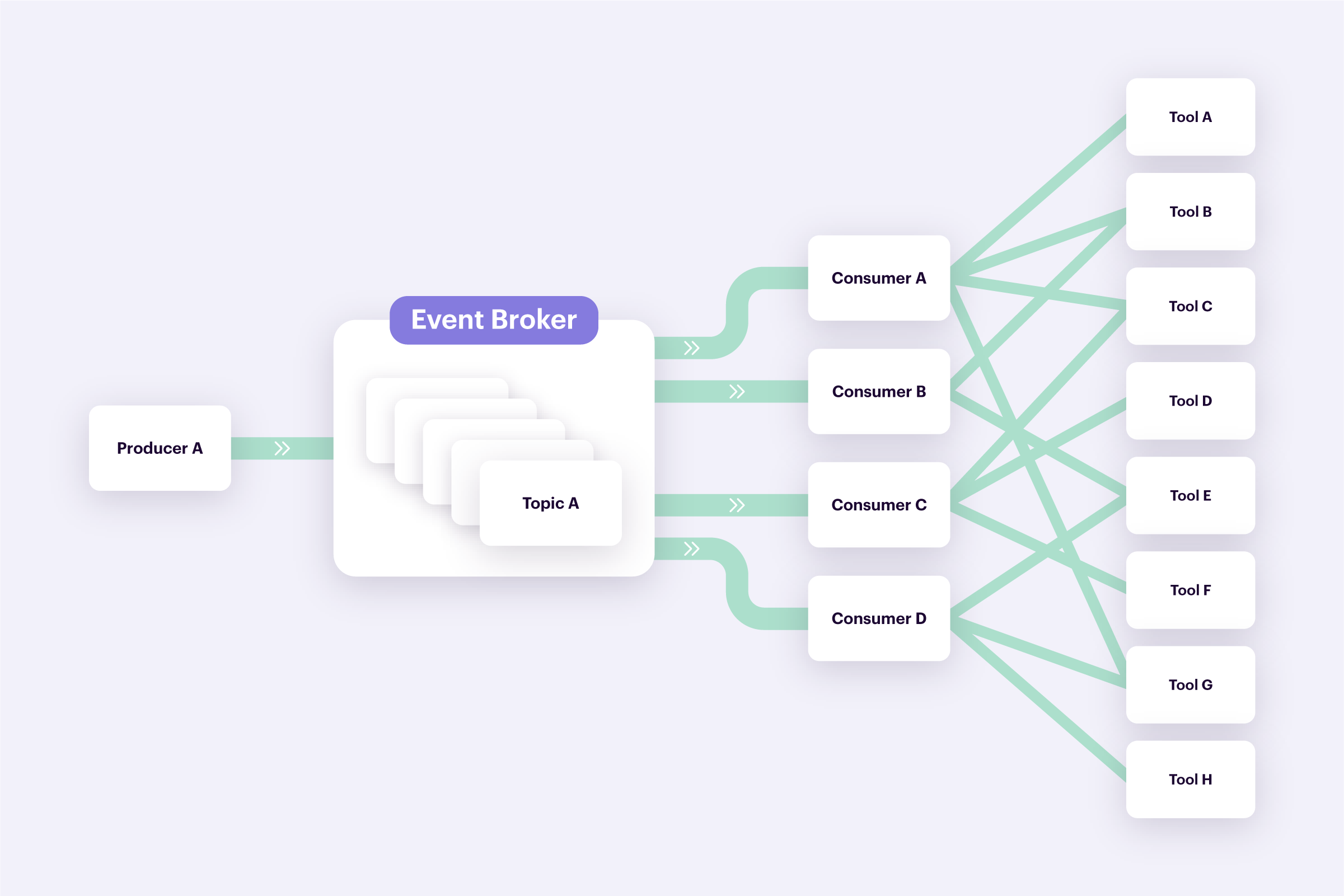
The "order completed" event gets produced into one of our topics. Let’s say that we have four consumers reading from this topic and processing the event. Through the use of a CDP, we no longer have to develop consumers that translate the original event into the many connected tooling specs. We can leverage the CDPs single tracking API instead. Once collected by the CDP, the data is simply sent downstream to destinations that can be set up through a point-and-click UI rather than through code. You would effectively be going from left to right: