How we sped up syncing millions of rows per minute to Redshift by 80%
Waiting hours for Redshift warehouses to sync? Here's how we reduced our sync times by 80%.
By Prateek Srivastava
Waiting hours for Redshift warehouses to sync? Here's how we reduced our sync times by 80%.
Two-thirds of Segment’s largest customers rely on Segment Warehouses to store their customer data.
As companies build more personalized customer experiences and become more data-driven, the need for easy and clean access to high-depth data sets spanning the full customer journey becomes critical. Segment Warehouses give customers deep insight into their business without requiring them to build and maintain data pipelines themselves.
Digital companies are seeing explosive growth as users spend more time online during the ongoing COVID-19 pandemic. In March and April, we synced an average of over 8 million rows every minute into our customer’s Redshift clusters.
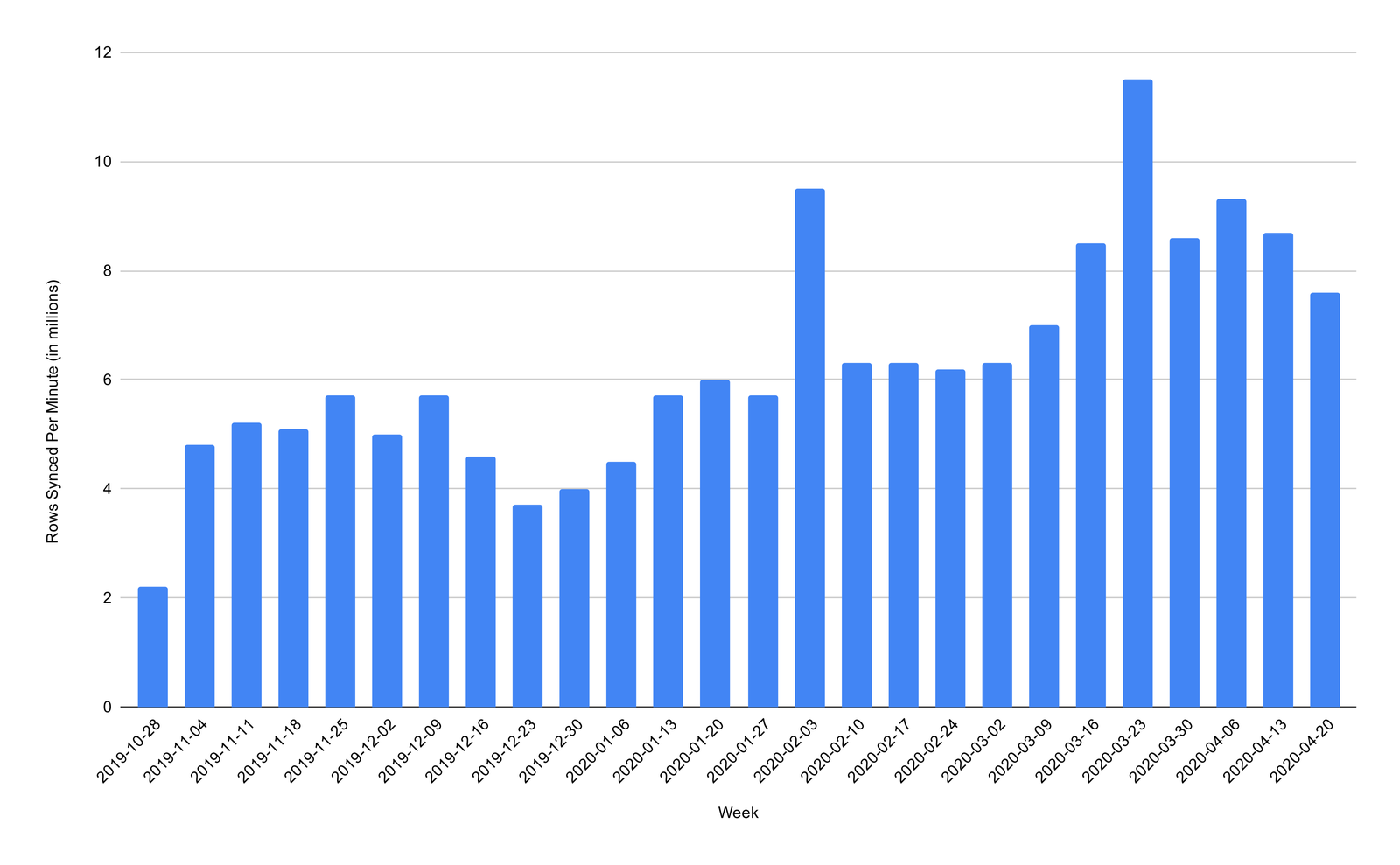
Rows synced to Redshift
However, while the volume of customer data has rapidly grown, the need for fresh and timely data remains constant. One Segment customer saw a 20x spike in user volume in just 3 days, causing their Redshift warehouse sync duration to balloon from an hour to over 24 hours.
With such long sync durations, the customer wasn’t able to use fresh data to drive critical business decisions during this explosive growth period.
As a result, we collaborated closely with the AWS Redshift team to improve our warehouse sync duration. These speed improvements ensure that Segment’s largest customers can rely on their Redshift warehouses to deliver fresh, accurate, and clean customer data to drive business decisions.
In this post we’ll outline some of the bottlenecks we identified in our sync process, and what we did to eliminate them.
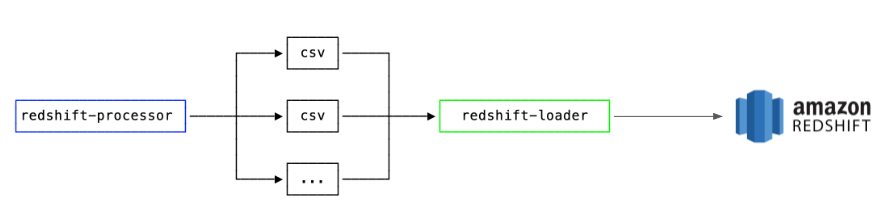
Redshift sync process
As a quick refresher, Segment’s core pipeline accepts a firehose of user events (e.g. page views) and buffers them to an internal S3 bucket. Then, the Warehouses pipeline processes and loads these events into customer data warehouses periodically.
There are two key components when we sync this data to a warehouse:
The processor converts raw Segment data into CSV files that can be loaded into the warehouse.
The loader copies this prepared data into Redshift and loads it into the relevant tables.
The loader loads data in the following steps:
Create a temporary staging table
Copy data into the staging table
Delete any duplicates
Insert records from the staging table to the target table
Drop the staging table
When we investigated the source of the slow syncs, we identified that the primary bottleneck was the Redshift loader. In this post, we’ll focus on three improvements that had a dramatic improvement on sync duration:
Disabling statistics
Minimizing transactions
Improving parallelism
The loader uses the Redshift COPY command to copy CSV files from our internal S3 bucket into a customer’s warehouse. By default, this runs statistical computations to optimize future queries on the table.
These statistics are usually important for long-lived tables with complex queries (those involving correlated subqueries or multiple joins), but because we’re staging data in temporary tables and running fairly simple queries, there’s no benefit to computing these statistics up-front.
We disabled this computation by setting the STATUPDATE flag to OFF, and now fewer queries spend time updating statistics. For our QA warehouse, we reduced the overall time spent on this step from multiple hours to under an hour every day.
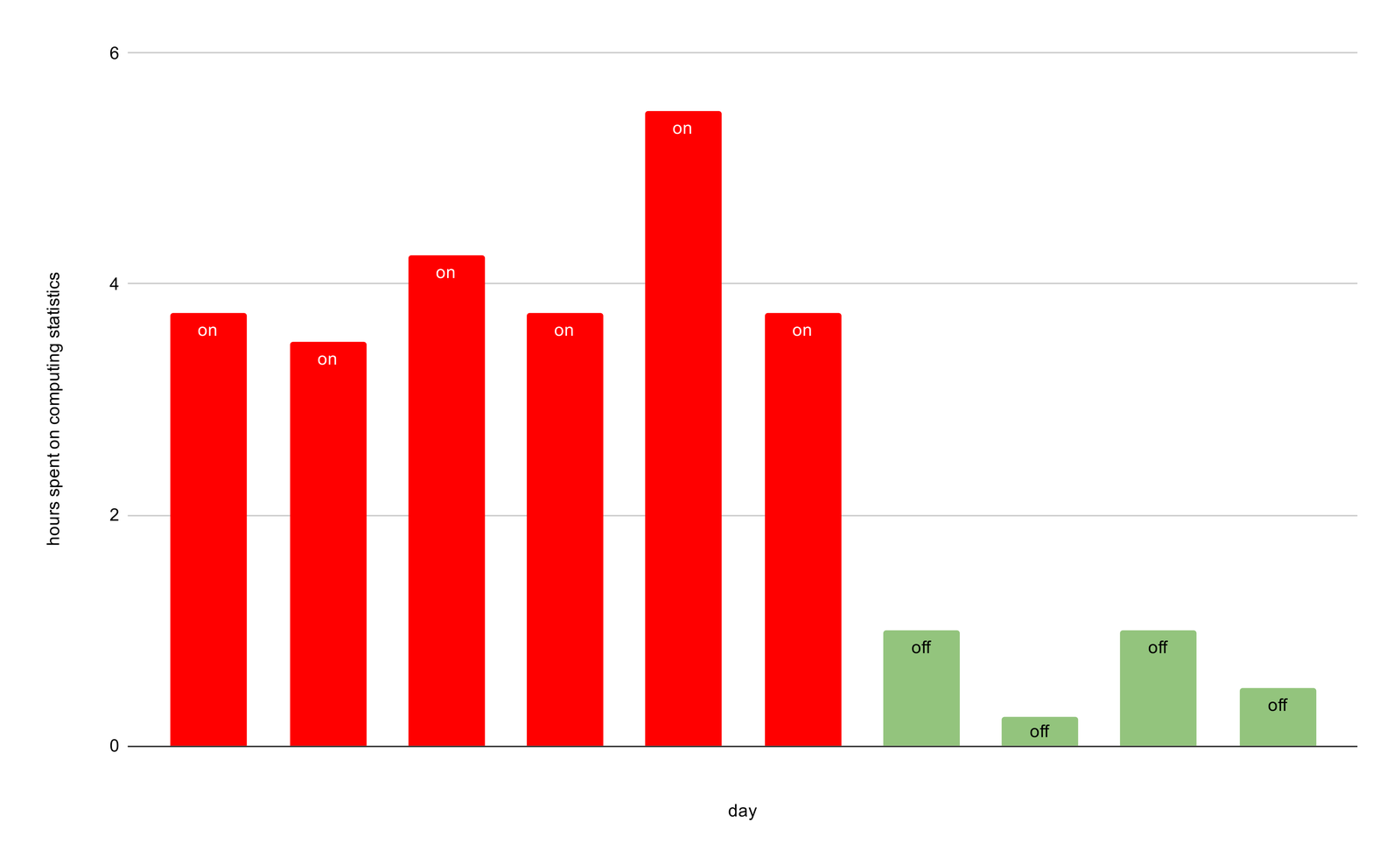
Eliminated time spent on computing statistics
For each file generated by the processor, the loader runs five SQL queries. By default, each query is run in its own transaction.
Transaction 1: CREATE a temporary staging table
Transaction 2: COPY data into staging table
Transaction 3: DELETE duplicates in target table
Transaction 4: INSERT records into target table
Transaction 5: DROP staging table
These queries are executed in Redshift using workload management queues. However, on larger loads, we were generating so many transactions that it was overwhelming these queues.
To reduce this, we began batching our queries into fewer transactions. Now we wrap our commands in two transactions, which reduces the pressure on the queues by 60%.
Transaction 1
CREATE a temporary staging table
COPY data into staging table
Transaction 2
DELETE duplicates in target table
INSERT records to target table
DROP staging table
On our test workload, we were able to observe a 15% reduction in this phase of the sync.
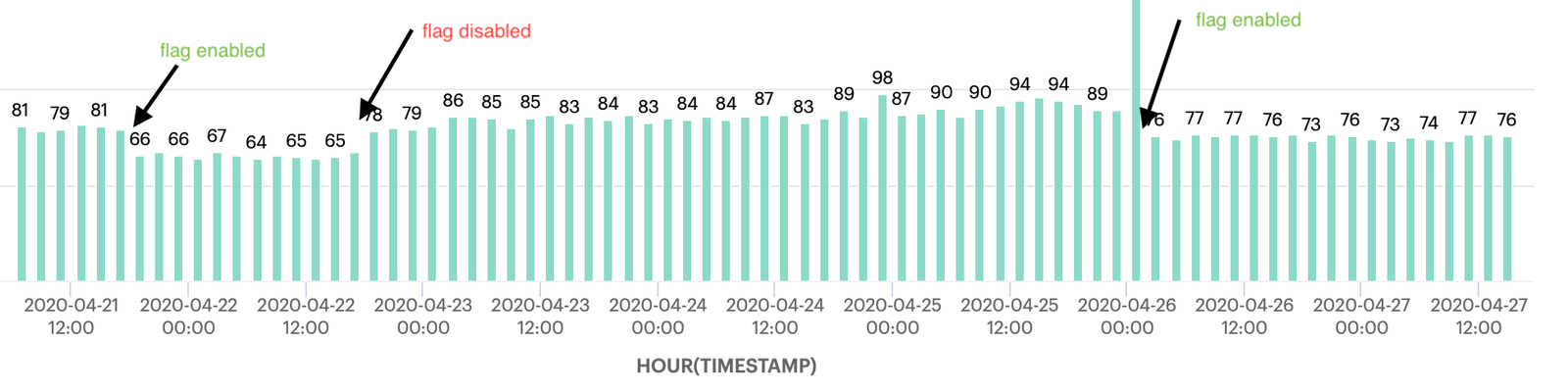
~15% improvement in loader duration
Minimizing the number of transactions is especially beneficial for sources with a large number of tables but a low volume of events. For these sources, we saw sync duration improve by up to 35%.
Redshift clusters contain multiple compute nodes, and each compute node is divided into slices that process a portion of the workload assigned to that node. When we copy files to Redshift, the work is distributed between slices, and each slice downloads a subset of the files that we are copying.
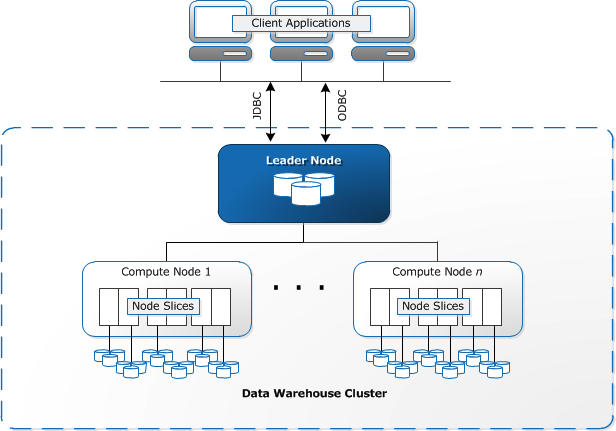
Redshift Architecture. Image source.
Previously, our syncs would generate files up to a maximum of 10MB in size. This allowed us to distribute files between clusters in the node.
However, Redshift can load files as large as 1GB, and our small files were adding excessive processing overhead in Redshift. Additionally, by using a static limit, we weren’t always evenly distributing the load between the nodes in the cluster which can be of varying sizes.
To improve the parallelization, we updated our warehouses pipeline to query the number of slices in the Redshift cluster, and use this number to generate a smaller number of larger files that could be evenly distributed across the cluster.
On our test workload, we were able to reduce the number of files by 10x and increase their size by 2x, which improved the sync duration by 15%.
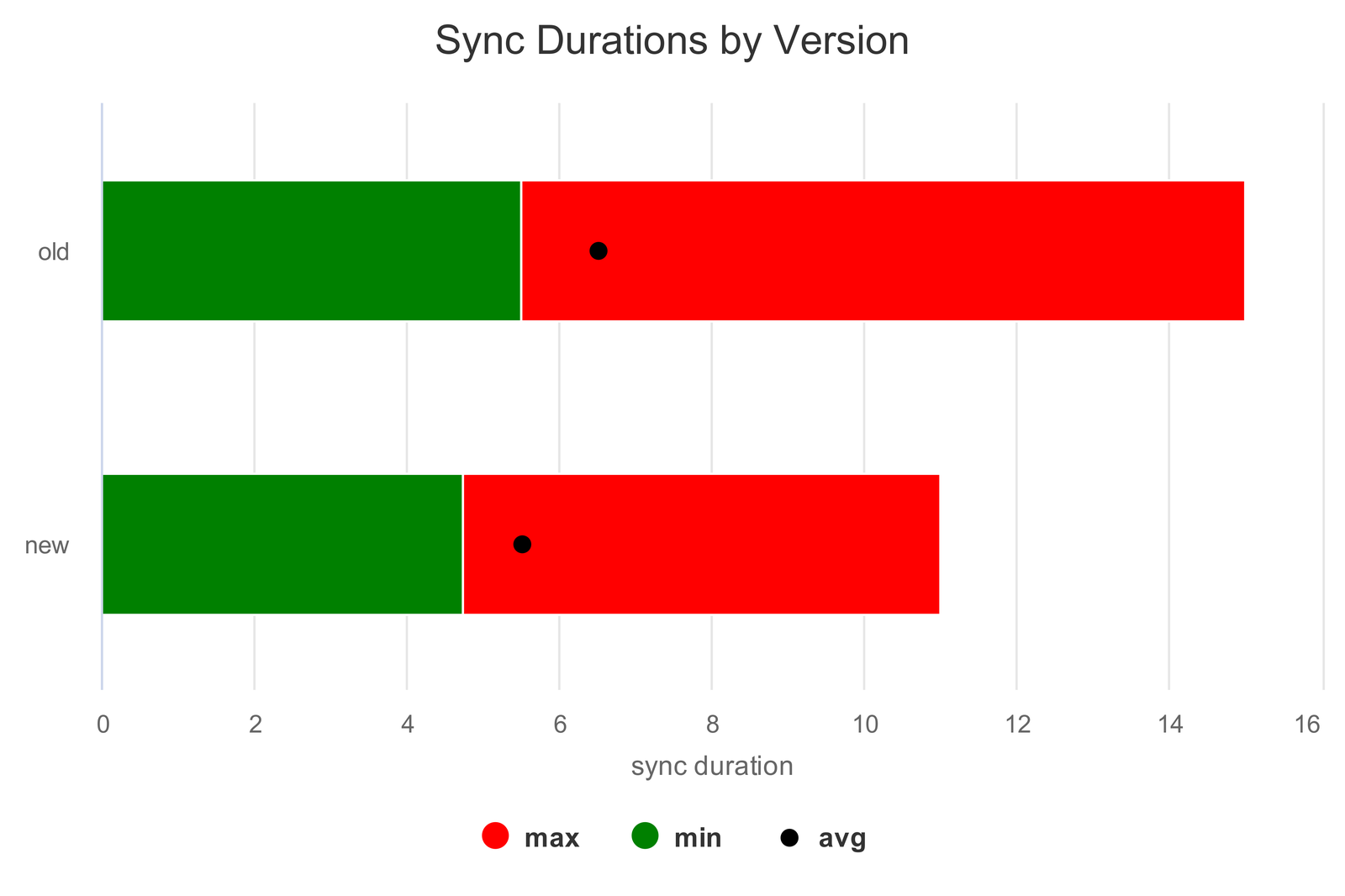
By disabling statistics, minimizing transactions, and improving parallelism, most Segment customers saw sync durations decrease between 5% and 83%, with customers loading more than a million rows per event seeing even bigger improvements.
We reduced the sync duration for a customer from over 6 hours to an hour, despite their usage increasing by 10x in the same period.
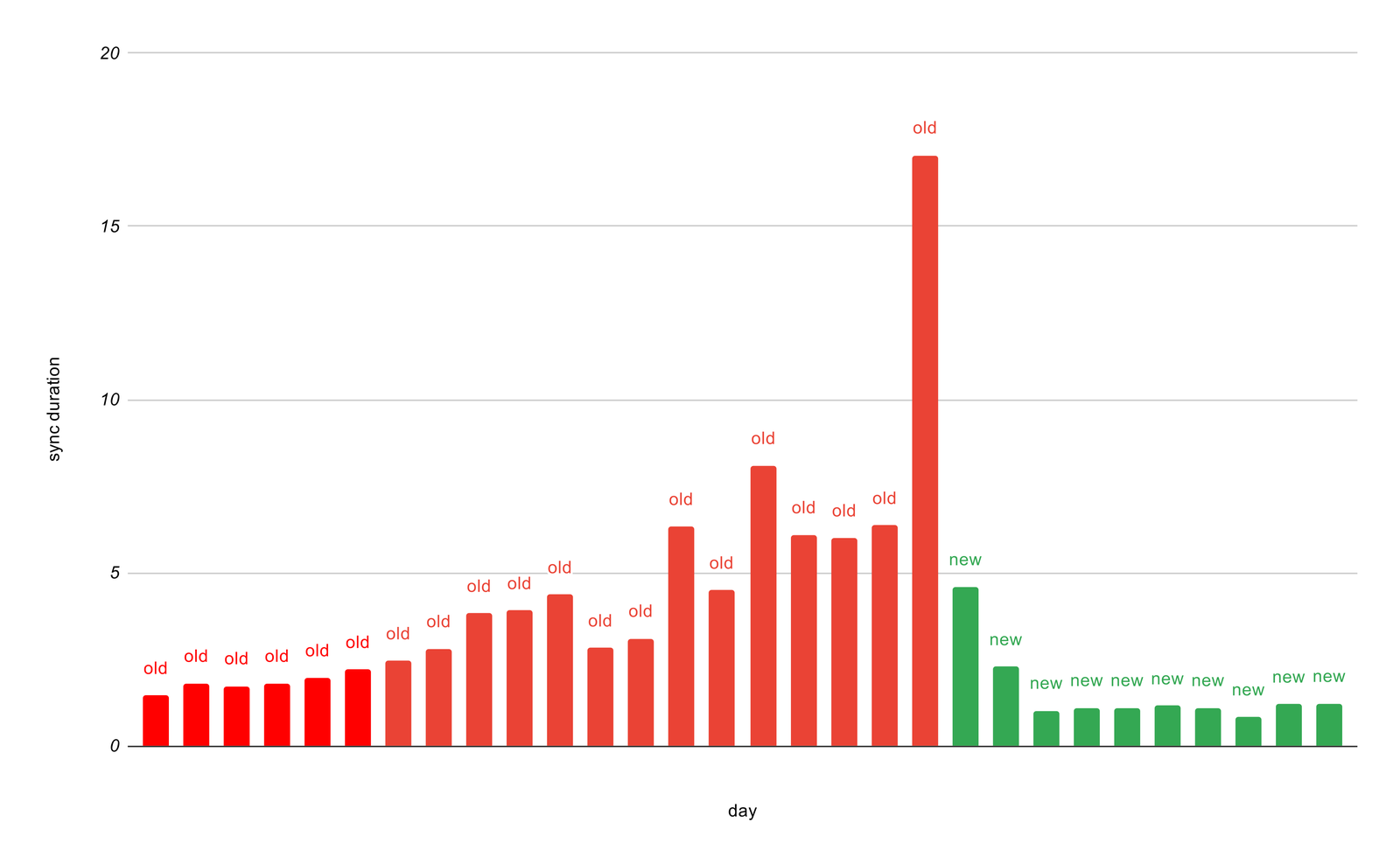
We’re excited to see the impact of these results, and our research also identified future areas of improvements for our sync process:
Customizable deduplication: We de-dupe over the entire history of the table. While this improves data accuracy, it comes at the cost of slower syncs. Allowing customers to tweak this window to their needs would help them strike the right balance between data integrity and sync performance.
Further minimizing transactions: We delete duplicates from the target table and copy them again from the staging table. This step causes the loader to acquire a lock on the target table which limits concurrent operations on this target table. By deleting duplicates from the staging table instead, we can eliminate the need for a lock, which allows us to further reduce the number of transactions in our sync from two to one.
Customizable distribution key: We use the Message ID as the distribution key, which ensures an even distribution across nodes in a cluster for most customers. However, some data sets can benefit from using other keys.
Parquet files: Loading data via CSV files requires having a consistent column order between the outputs of multiple processors, and it also bloats the files if there are only a few entries with a particular column. Parquet is a much more compact format, especially when the columns in the data being loaded are sparser compared to the columns in the target table.
In November, we loaded over a billion rows every hour into customer warehouses, and we’ll continue to evolve the infrastructure to support this growth behind the scenes!
This project would not have been possible without the efforts of Rakesh Nair, Mallika Sahay, Y Nguyen, Maggie Yu, Dominic Barnes and Udit Mehta. My sincere thanks to Brandon Schur and Gal Barnea from AWS guiding us every step of the way, and to Benjamin Yolkien, Tyson Mote and Geoffrey Keating for reviewing this post.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.