How Twilio Segment released PII Access Controls
An inside look at our engineering process for releasing PII Access Controls.
By Solon Aguiar Barbosa de Aguiar Neto
An inside look at our engineering process for releasing PII Access Controls.
At Segment, we process tens of billions of events every single day. We process all types of data, including a large quantity of personally identifiable information (PII).
For us, data privacy is a right and in October 2020, we officially announced the release of the least privilege configuration for data access. With this new capability, our customers can grant access to the Segment dashboard to more of their teams while protecting PII and respecting their customers’ privacy.
In this post, we'll cover the untold engineering story of how we took PII Access to general availability. We'll cover all of the details that were left out previously: from the technical challenges to the solution and the release process.
Throughout this post, you'll learn about what drove us to make the decisions that we did and their impact on the project. In the end, you'll have a full picture of how we moved from an idea to a live feature for all users of Segment.
While building software, our team follows a set of principles. These principles are guidelines that hold us true to our ultimate goal: deliver the most value to our customers. These are principles, not practices. Practices and methods evolve whilst our principles remain steady. By adhering to principles instead of practices, we become critical of which tools and processes we follow while staying open to improvements and new ways of thinking.
"The reputation of a thousand years may be undermined by the conduct of one hour" - Proverb
The system will be available. We want to serve our customers all of the time, and regardless of the magnitude of the change (whether it's one CSS line or a permissions migration in the authentication database), the system won't go down.
While striving for no downtime, we push ourselves to think outside the box and develop strategies to mitigate any potential impact on availability. We ask ourselves questions such as:
Can we run this migration online instead of having to bring the database down for a few minutes?
How do we switch between systems seamlessly without deploying any code?
Pushing ourselves to think about downtime doesn't guarantee that problems won't come up. There are always unforeseeable circumstances that cause the system to crash. We know that we can't realistically guarantee 100% uptime - it's a trade-off that we make.
However, aiming for that leads us to think creatively about what we can do to reduce the scope of possible scenarios that can happen. In conjunction with our other principles, we try to make sure that we can quickly act when things go wrong.
“A customer is the most important visitor on our premises. He is not dependent on us. We are dependent on him” - assumed to be Mahatma Gandhi, but not certain.
No customer should experience any disruption of their experience. At first glance, this principle appears to be the same as No downtime, but customer impact goes beyond simply keeping services available at all times. At Segment, we have a broader view of what customer impact is rather than just having the system online. When we consider customer impact, we think of:
The system is online
Any customer can perform any action that they are entitled to
Actions are performed correctly and promptly
These requirements complement each other to guarantee that we deliver a high-quality product. This holistic view of customer impact pushes our team to deliver the highest quality output considering many aspects of the customer experience in the Segment app. As with the No downtime principle, this is not foolproof as we can't think of everything or emulate every possible scenario. Problems do slip through the cracks and we are left to deal with them, which brings us to our next principle…
"Everybody has a plan until they get punched in the mouth" - Mike Tyson
We know what to do when things go wrong. As we said earlier, even when we do our best to prevent problems, issues still arise. Luckily, the space of what can go wrong is, usually, much narrower than how it can go wrong. In these scenarios, our mitigations plans come to the rescue: we have alternatives established. Some examples of mitigations:
Catch and log an exception while calling a remote service that is not essential to the service operation so that we can investigate it later
Use retries for operations when applicable
Use slow processing queues for non-essential items that consume a lot of resources
Hide changes behind feature flags that can easily be turned off (preferably without a code deployment)
Create a runbook of manual procedures that can be performed by an operator
Mitigation plans can span multiple, often distinct but related, domains: from code constructions (such as try…catch statements, retries, and processing queues) to documents that list actions to be taken by an individual. The core of the principle is to recognize that things can and will go wrong. When they do, it’s important to have mechanisms in place that prompt action.
"It is a capital mistake to theorize before one has data" - Sir Arthur Conan Doyle
Decisions are based on known facts. We cannot act on our plans (or even come up with them), know the performance, or find out the status of the system if we don't have data telling us that. We can't rely on feeling or wishful thinking to guarantee quality. Without data, we are bound to failure from the start.
We need visibility into all of the aspects (latency, errors, requests, wait time, operations, alarms, profiling, etc.) of the system to know what is going on and, ultimately, how to act. To have proper visibility, we need to think about what we need to measure and how to do so; we carefully consider what data points that we need to obtain (if they aren't available already) to guide our decision making when the time comes.
Visibility is one of the fundamental stepping stones upon which all of the other principles (and thus any solution that we create) are built upon.
When we set out to build PII Access, we didn't build the components from scratch. All of the major systems that comprise the feature existed before we started. Our work consisted of extending each one of them according to our needs. We will provide details into the three most critical components in the following sections and elaborate on the challenges later on in this post.
Before we dive deep into the functional components that created PII Access, we have to recognize the infrastructure and observability at Segment. These systems won't be detailed below as we chose to focus on functional aspects, but they were nonetheless extremely critical to us (see Act on what you know above). We couldn't release PII Access without all of the feature flagging, deployment automation, metrics, alarming, security checks, provisioning and monitoring that Segment engineering teams have built.
Before PII Access was released, the permission model in the Segment app already supported many levels of flexibility. Workspace users were divided into two groups: owners and members. Owners had sudo power to perform any operation. Members were limited to a pre-defined set of operations based on the subgroup they belonged to (example: Source Admin, Source Read-Only etc.). Regardless of which subgroup they belonged to, members had a subset of the permissions that owners had.
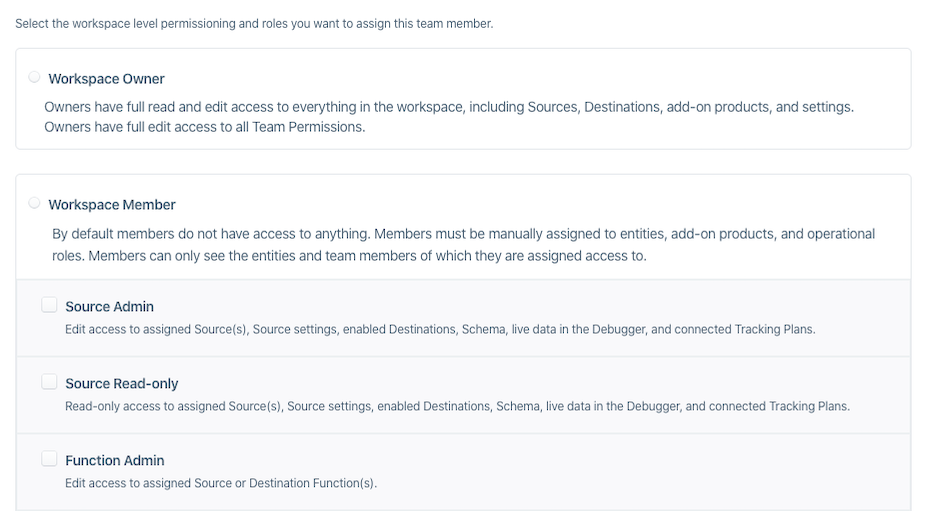
Snippet of the Access Management page before any changes were made
All of these permissions made a basic assumption: there was no limit to access personally identifiable information. This meant that any user with access to a page in the workspace that displayed PII would be able to see that data, which posed a limitation to our customers. On the one hand, they could limit the access to customers' PII, but on the other, it also limited the workspace access within their organization. This limitation turned into a burden when customers wanted to expand usage of Segment to other parts of their organization (for example: allow the marketing team to use Personas), but couldn't bear the risk of allowing PII to be widely accessible.
With the release of Privacy Portal, the privacy team at Segment created the infrastructure to detect and process PII in our data plane (learn more on our separation of data and control plane): the pii-classifier. This is a powerful and extremely fast system that classifies and tokenizes any piece of data that may contain PII.
Before PII Access came into place, the pii-classifier was used only in the data processing pipelines and didn't power any feature in the Segment app, which is part of the control plane. There were two reasons for this: as much as possible, we like to keep services scoped only to a single plane (avoiding cross-plane dependencies), and there was no need for pii-classifier in the control plane. When the work started for PII Access, we quickly changed the interpretation of the latter.
The idea behind PII Access is simple: workspace owners can control, via a new role, which members of their workspace can see personally identifiable information when browsing through the web application.
Because the basic functional parts were already in place, our scope was narrower: extend existing systems to support the new use cases and integrate them. Our work can be summarized by answering three questions:
How do we integrate this new permission type with the existing model?
Which system will be responsible for the data manipulation?
How will we plug the data masking all of the necessary systems?
Question #1 was relatively easy to answer, knowing the permissions model already described. We created a new permission role (which is an abstraction on a set of actions allowed to an actor) to allow PII access. Any member could be granted this role (workspace owners would have this new role assigned to them by default), and any part of the infrastructure that displayed PII would check whether a user requesting the data belonged to it before allowing it to flow through. For backwards compatibility, any pre-existing PII-viewing permissions were folded into the newly created role and eventually stripped from all other existing roles.
Answering question #2 was also relatively easy. The pii-classifier already performed PII detection for our data pipeline. Furthermore, in one of our hacking sessions, a couple of engineers experimented using those PII detection capabilities to plug-in PII masking in sections of the app. The experiment was successful at the time, but still had some rough edges that required some time to make it production-ready. When working on PII Access, we were able to pick up where that work had stopped: we added new features to masking, extended it to new use cases, improved the overall performance of the operations, formalized the permission checking, and established the cross-plane connection. Having that first hack as a starting point allowed us to move quicker and see results sooner than we expected.
The hardest question to answer was #3. The options that we considered had many trade-offs and we were often unable to evaluate them due to our unfamiliarity with the system. We had to do extensive investigation, read a lot of code, and leverage other engineers to pick their brains on the possible and best alternatives for us.
To understand the solution that we chose, it is important to know a little bit more about the architecture of our app. The Segment web app reads all of its data from our public gateway-api. This API acts as proxy that fans out incoming requests to the many control plane backend services that manage the data - it's in these services that the business logic lives.
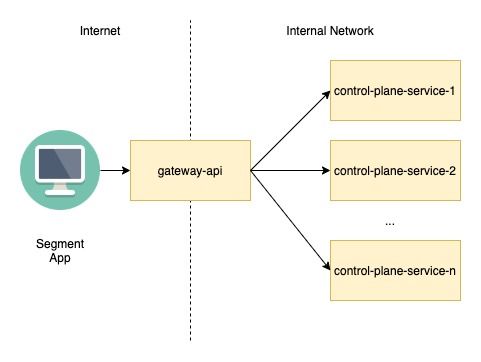
Simplified architecture of the Segment backend
After much deliberation and many consultations with the different domain teams, we agreed that each service that processes PII would integrate directly with the PII Access solution via a single backend system called privacy-service. It would verify permissions and release status of the feature as well as forward the data manipulation to pii-classifier, which meant that it also made the cross between the data and control plane. The reasoning behind this architecture was that it centralized all of the logic in one place (maintaining control of bug fixes, release schedule etc.) while still keeping the gateway-api as a thin proxy. Any client (in this case, a backend system) that needed to handle sensitive data properly was extended to forward that concern to privacy-service. A downside of our solution, which we accepted as a valid trade-off, was that we had to catalog and change all of the different systems to include the proper data handling logic.
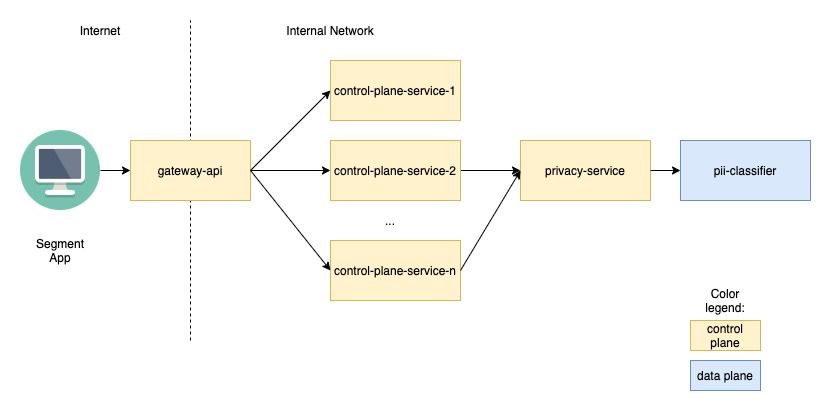
Updated architecture showing interactions with the PII Access feature
When we set sail to define how to solve for PII Access, we didn't have just the functional requirements in mind. A major question throughout all of the design and review process was: How will we seamlessly and incrementally release this feature?
This is not a question that we take lightly (see the Principles section above). We grapple with it on most features we build (see how we released our app update). Since most of our services are released dozens of times a day, it was paramount that we didn't keep our changes isolated in feature branches, which would become unmanageable very quickly. Instead, we kept merging our code while guaranteeing that we didn't impact any of the live features. Additionally, due to distributed nature of the feature, in order to go live, we needed a mechanism that would globally and simultaneously turn it on for all of our customers.
Despite the new particulars of our feature, this class of problems is not new to us at Segment. We have spent a considerable amount of time solving for that and built robust feature flagging systems (flagon) around those problems (learn more about the system behind it). Therefore, for PII Access, the way to use the flags was another design decision: we ended up with a single global flag that we could dial up incrementally (phased release) and add specific overrides (for internal testing and beta testing). Because all of the business logic was centralized in a single system, any system would make the request to privacy-service and that would decide, based on the flag and user permissions, how to manipulate the data.
With flagon, we easily released our changes without worrying it would cause any issue. Even if we did, we would be able to turn it off with a single command.
Once all of the changes were completed, we moved on to the next step of the project: the phased release. During this time, we split our work into three major phases that increased in complexity, impact, and scrutiny: Internal Testing, Beta Release, and Public Release. Moving from one phase to another involved data validation on performance, correctness, user experience, security, reversibility (e.g., can we undo this in case things go wrong?) and answered questions on whether we had everything that we needed to proceed (e.g., are we missing any data point that can give us more insight?).
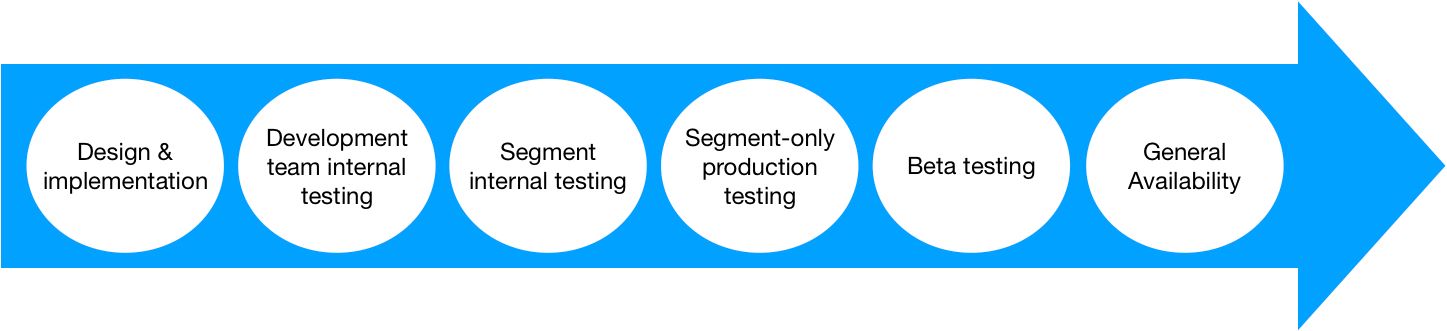
Project phases combined
For us, when we refer to release, we assume that all of the code is thoroughly tested (via automated and integration tests as well as, when applicable, manual validation), that it is already deployed both to the testing and production environments behind feature flags, and that all of the security checks and preventive measures are in place. This is all part of our definition of done for any task before we can move on.
The first major milestone of our release was the internal testing phase. This phase was divided into two parts:
Testing in the staging environment
Production testing
Because we used feature flags, turning on the changes only in our internal environment was a simple step. As we were releasing for the first time, we defaulted the feature to off for all of the workspaces except a handful owned and operated only by the development team. With PII Access available to us, we tested the feature in practice, generated failure scenarios, and, consequently, uncovered gaps and bugs. Most important of all, we validated assumptions and got to see firsthand the experience that our end users would eventually have.
After the development team fixed all of the issues and was comfortable with our data, we released the feature to all internal workspaces and solicited feedback from any internal users that came across it. This strategy gave us the chance to gather feedback from people who were not directly involved in the project and, thus, weren't biased or knowledgeable of its inner workings. This period was extremely valuable to get thoughts on user experience and clarify usability issues that we were oblivious to.
When we were completely comfortable with usability, fixed more bugs, and had more data, we moved on to production testing. Since, at this point, everyone in the company knew about the feature, we went ahead and skipped the development-team-only testing and turned on the feature for everyone in a few selected internal production workspaces. We were extremely cautious about limiting the exposure as not to affect any customers while still having the feature live in production to gather data and feedback. Thanks to our feature flag usage, this happened without any hiccups.
We were ready to release it to customers.
It was now time to put the feature in the hands of our customers. Due to the delicate nature of PII Access and the fact that it had the potential to affect the experience of a large number of users of the Segment app, we chose to release it first to a subset of customers. These customers were aware of its new state and were willing to be beta testers. This initial set of users were valuable throughout the process, experimenting with the feature and pointing out any caveats that they observed.
During the beta testing, we observed data on usage, performance, and usability. We also kept a close eye on whether the feature was working correctly and if it was performing within the acceptable thresholds under load. The customer feedback and the data we gathered was fundamental for us to know that we could move on.
After a couple of months of testing, data gathering, and feedback, when to bring PII Access to general availability was a business decision. With all of our infrastructure in place and ready to go, we agreed on a time and date to flip the switch.
At the arranged time, one of our engineers ran the command and, a few seconds later, all of the workspaces were able to use PII Access. It was a simple and quick operation that only required two people (one to run the command and another to double-check it beforehand). After we turned the feature on, we had one engineer allocated to observe metrics and eventually make small adjustments during the day.
In a way, the PII Access release was anti-climatic. There was no major focus, war room, nor many eyes on multiple screens to check out what was going on. This may seem odd, but that was always the goal. We didn't want that (or any feature for that matter) to require a big bang release - we strive to make our releases smooth and straightforward. With our feature flags, phased testing and feedback sessions, we accomplished it. We were completely confident in the work and, at that point, general availability was business as usual: it was just a procedure to flip the switch.
It is important not to mix that approach with carelessness. As mentioned before, we had an engineer dedicated to watching metrics, making sure everything was going on as expected, and many plans of action in case of issues. We were ready in case anything came up.
This post wouldn't be completely true without this step. Using feature flags for controlling our release doesn't come without downsides. One of these is the extra code complexity and overhead to toggle between the many code branches based on the flags' values. This bloats the production code and tests, so it is important to go back and remove any obsolete references once a feature is live and working well.
That's exactly what we did for PII Access. A few weeks after our release, we knew that we weren't going to need the feature flags anymore and so we removed all of them.
The PII Access project had its unique set of challenges. Despite it being composed of components that already existed, we had to drive agreement across multiple engineering teams in three different business organizations, change core systems of the Segment infrastructure that were completely novel to us, solve the hard problem of PII identification and masking, and think about extensibility. All of that while making sure that no user experience was ever affected.
The whole team did a great job at navigating those and many other issues. We did so not only because we enjoyed what we were doing but also because we believed in protecting user data. In the end, we were happy with the product that we delivered, the process that we followed and the lessons that we learned along the way.
We would not be able to accomplish this work without the help of the many engineers that reviewed our designs, our code and built the amazing features that we stood upon; product managers that discussed features and ideas; designers that carefully thought about the user experience; and development managers that guided us in the process of evaluating and choosing options. Thanks to Drew Thompson, Ife Ajiboye, Rachel Landers, Kevin Tu, Matthew Shwery, Netto Farah, Daniel St.Jules, Tyson Mote, and Frances Thai.
Last, but not least, special thanks to the people that reviewed and provided feedback on this post: Gurdas Nijor, Doug Roberge, and Jon So.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.