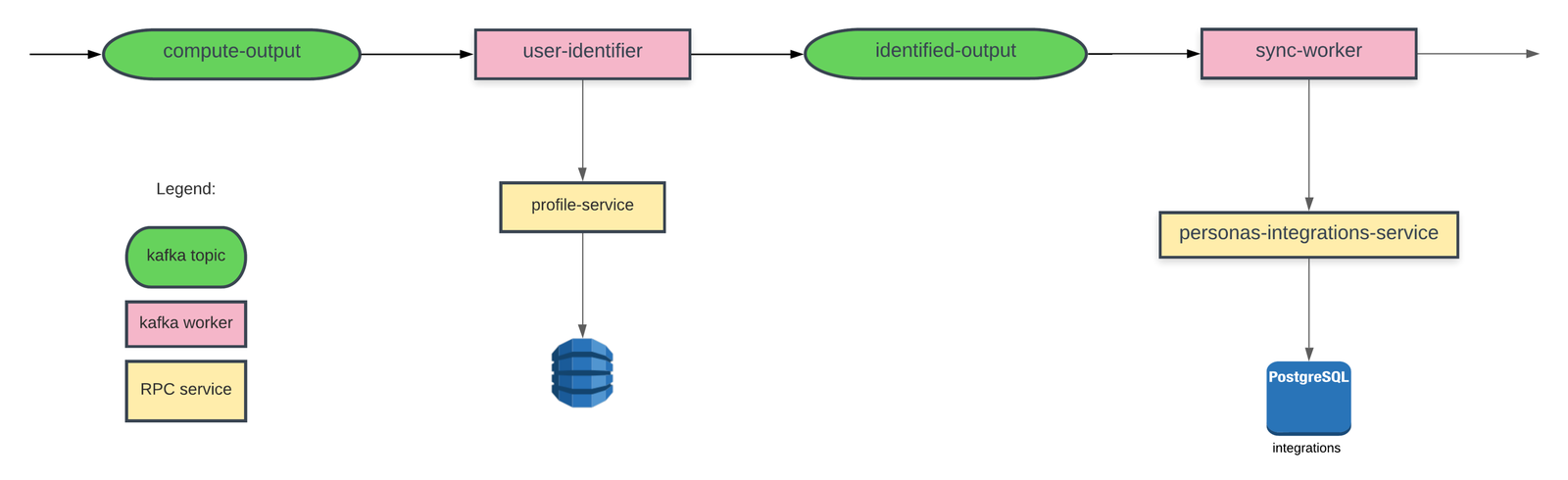
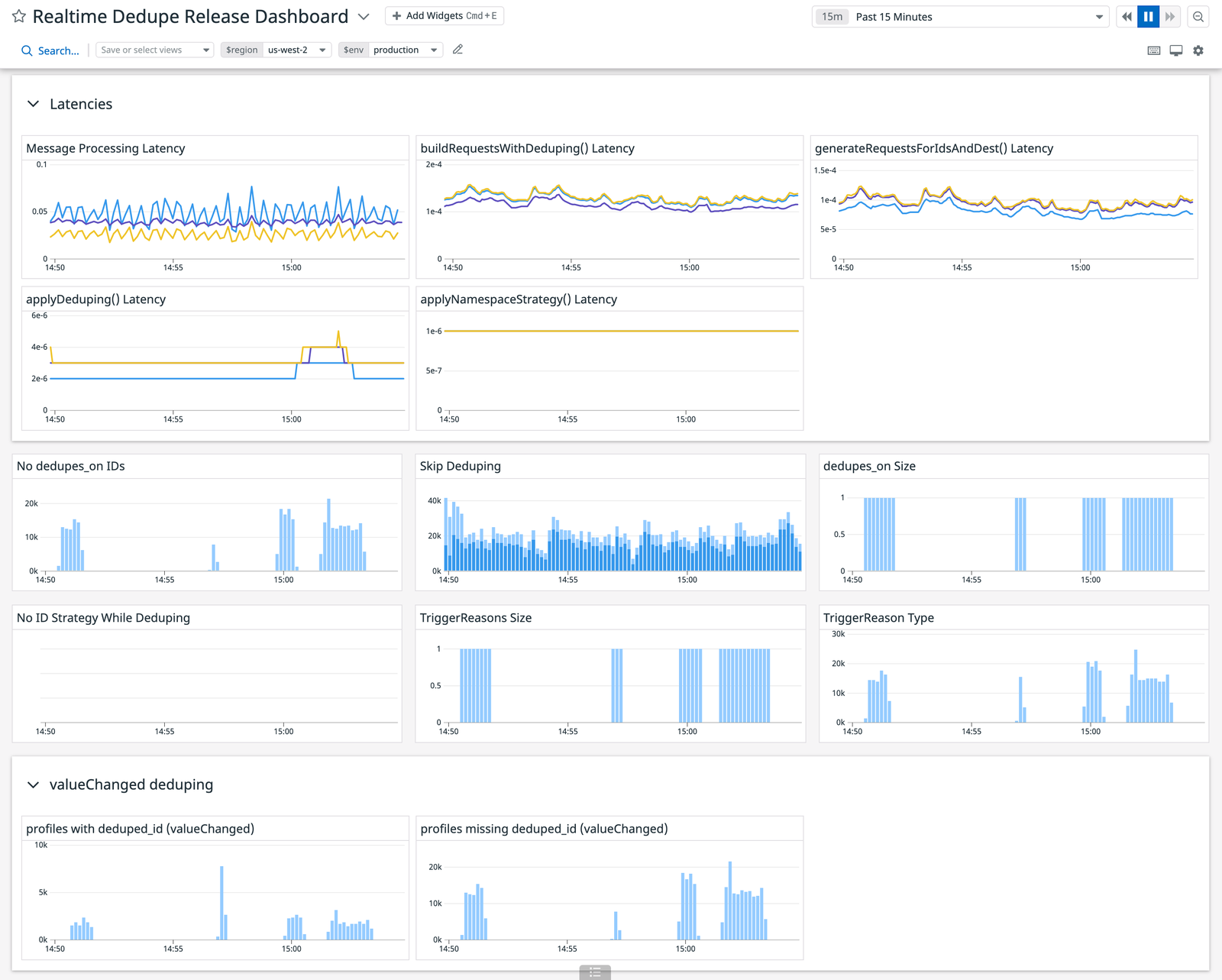
Like many services at Segment, sync-worker service emits metrics using Datadog. By measuring the average P95 and P99 latencies at each method of the dedupe process, we saw exactly how much time it took to dedupe a message in comparison to the legacy code. We could also identify performance bottlenecks at a more granular level. By meticulously introducing metrics during development instead of as a post-deploy afterthought, we could not only de-risk the performance impact, but optimize the code during feature development.
Comparing existing and experiment output
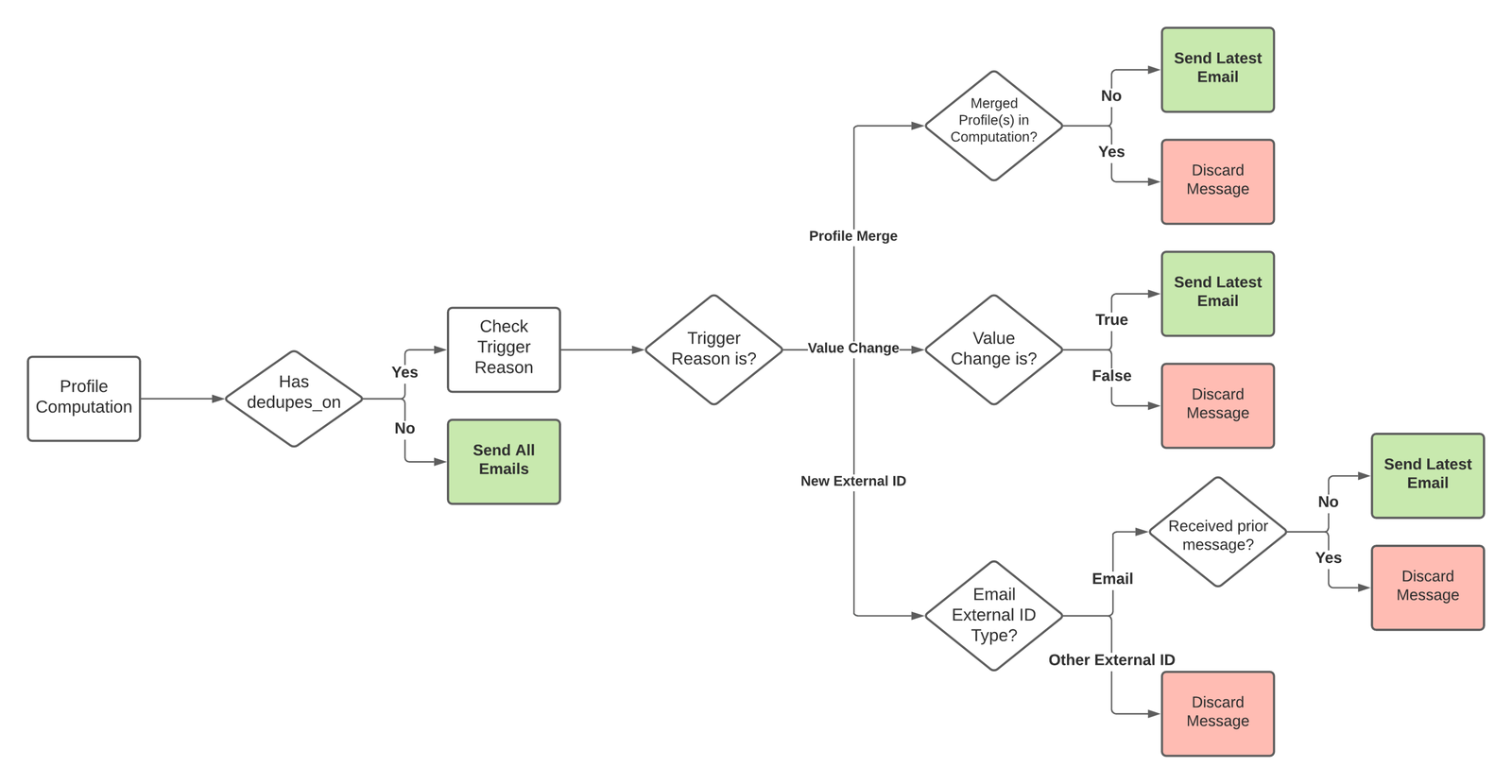
Rewriting large portions of the sync-worker codebase along with the dedupe feature meant we increased the blast radius and potential impact to existing customers. Although we had strong validation from our aforementioned testing strategy, we decided to implement a lightweight realtime output comparator. There were a lot of tests in the code base already, but there was no failproof way to know if there were any corner cases missing.
By comparing the experimental output generated using the new flow with existing output from the legacy flow, we could further validate that we did not introduce any regressions. The count and content of messages that were not configured for dedupe should be identical for both flows.
Similar to the ID group implementation, we stored messages generated in either flow in separate maps. For each outbound message, we generated a SHA128 hash and using it as a key, stored an integer that was incremented every time we saw that key. In the final step we compared the contents of each map.
Deployment gates
Segment’s systems are designed for continuous availability and Segment’s global customer base expects to be able send their data at all times. No matter the feature, large or small, new code always has the potential to introduce regressions or operational issues. Due to the scope and complexity of the dedupe feature, it was important for us to plan for safety- gradually rolling out the changes and quickly repairing the system if a regression was detected.
Segment uses a proprietary feature flag system called Flagon which allows for two types of operational levers. Flags are a simple mechanism that allowed traffic to be diverted to old or new paths based on a percentage. Gates are more granular and allow traffic to be routed depending on Segment’s various customer tiers: Free Tier, Self-Service, Business Tier, etc.
With that in mind, we adopted a combination flag + gate approach for releasing the feature. The flag dictated whether sync-worker should generate a second set of events using the new dedupe flow and compare them against events generated using the legacy flow. It also acted as our emergency shutoff valve to completely disable the entire dedupe codepath if necessary. The gate, on the other hand, controlled how we rolled the feature out at a per-customer basis. This gate governed if sync-worker should send messages to the destination Kafka topic that were generated using the dedupe or legacy flow.
Over the course of several days, we slowly migrated customers over to the new deduplication flow until all customers were on a single codepath. All of this was done without any code changes.
Out in the wild
The new dedupe functionality we released was designed and implemented as a backend-only feature on Segment’s data plane. And that meant that the best news is no news at all. Despite this feature being designed to support the new Twilio Engage platform to be released in 2022, we were rebuilding our infrastructure in the present to support the new dedupe use case and set our systems up for success in the long term.
Over the course of the week-long rollout to our customers, we kept our eyes locked on our metrics dashboards and on all the relevant escalation Slack channels. During that time we did not detect any mismatched events between our two message streams and we received no customer complaints. And most importantly, we did not have to revert any of our changes. That is not to say we were completely free from incidents (which we will detail in our lessons learned) but considering we rewrote one of Twilio Engage’s most critical and high volume systems, we were very pleased with the outcome.
Some numbers
After implementing dedupe and moving every customer onto the new feature, the end result was:
-
-
-
3,845 New Lines of Code (including tests)
And most importantly…
-
0 Customer Zendesk Tickets related to dedupe
There were countless take-aways from this project. Below are some of the most important ones for us.
Re-writing is not always the answer
Completely rewriting sync-worker was not an obvious decision. It slowly dawned on us as we analyzed the unique characteristics of the codebase, the new requirements, the timeline, and the existing test coverage.
Even then, it didn't come for free. There were times were we questioned whether this was the best path. During those times, we always remembered that not rewriting it would be even costlier. Because of our decision to rewrite, due to the importance of this component to Personas, we had to come up with the elaborate release process described above to double check the work.
A full rewrite is not always the silver bullet. It is a decision that shouldn't be taken lightly and that doesn't come for free. It is important to understand the trade-offs and explore possibilities before going down this path.
Ah, that edge case scenario
When we initially deployed our changes to production, we kept a close eye on memory usage and response time. We knew that we were going to take a hit, since we essentially did twice the work (remember that the test, new code, and control, old code, were running simultaneously so that we could compare outputs). The main question was, how much of a hit? For a couple of days, we kept a close eye on our metrics which were very promising: no considerable memory or latency increase.
Until a fateful Wednesday at 1:00 AM, when we received alerts that hosts were being killed off due to out of memory errors (OOM). Our Kafka partitions were starting to build up lag leading to delays and we would start to loose data if they exceeded the retention window. We had not encountered this during our stage testing or throughout the previous days that our code was being gradually released to all customers.
At this point during the incident, we did not have conclusive evidence that there was a problem with the dedupe feature or a general problem with the system. However, we quickly validated this by using the emergency shutoff switch and sure enough, the OOM issues subsided and data began processing as usual.
This was a clear indicator that our deploy was responsible and we had to find out why. Looking for root cause in a Kafka topic that processes millions of messages a day is a modern day equivalent of looking for a needle in a haystack. To our advantage, during the incident we saved the messages at the current offset of the stuck partitions and upon inspection, the reason for the OOM became clear.
Since our comparison tester was checking the new and legacy outputs, our memory footprint was doubled (as expected). This memory overhead was not a problem for a majority of our customers, but for some highly complex and extremely rare profile configurations, the resulting amplification factor could be as high as 150,000x. That mean one input message resulted in over 150,000 outbound messages! With the double processing, that would amount to 300k messages stored in memory.
At this point our changes were diffed for many days without any regressions. We were very confident that the new code worked well and didn't introduce any different behavior. Our mitigation strategy was to disable the comparator altogether and complete the release. Our main learning from this story is that while we were diligent about our code correctness and didn’t see any performance discrepancies between the new and old flows, we failed to account for the performance impact of our validator in very rare cases. Our testing and validation mechanisms must be held to same level of scrutiny.