What is data lineage? Complete guide + tools, tips, & examples
A guide to data lineage best practices and processes.
By Segment
A guide to data lineage best practices and processes.
Businesses are dealing with a near-constant flow of data from different sources – data that’s then moved, transformed, and consolidated to provide a 360-degree view of business operations and customer experiences.
But without a clear record of why, when, and how data has been moved and modified, businesses will find themselves unable to validate its accuracy or proactively resolve issues in their pipeline.
This is where data lineage comes into play – and why this transparency around the flow of data has become so important for businesses today.
Data lineage is the process of recording and tracking the flow of data throughout its lifecycle. It enables businesses to visualize and understand where data comes from, how it transforms over time, and where it’s ultimately stored.
The goals of data lineage are to ensure visibility into how data moves throughout an organization, and to proactively identify the root cause of any errors during data processing or analysis.
Identifying where changes in data fields occurred (e.g., renaming, deleting, or editing)
Identifying data sets that are highly sensitive and should have restricted access
Troubleshooting data errors or mis-entries
Checking data accuracy and completeness
Data lineage is critical for businesses because it provides a clear view of how their data moves across the tech stack. This is instrumental for protecting against security risks, breaking down data silos, identifying input or system migration errors, and remaining compliant with privacy regulations.
In short, data lineage provides crucial context into how data is managed and how it migrates between different tools and systems.
Data classification involves arranging data into categories according to its similarities, like data origin, sensitivity, access permissions, content, and more. Meanwhile, data lineage is all about gaining visibility into the movement, migration, and transformation of this data.
Best when automated, data lineage and data classification help businesses with risk management, protecting sensitive data, and searching for specific information quickly and efficiently.
Both lineage and classification enable:
Data location/search. Classifying data makes it easy to probe and find relevant data when needed.
Lifecycle investigation. Data classification helps businesses gain visibility into their data lifecycle to check its accuracy and ensure its trustworthiness.
Sensitivity designation. Classification allows companies to tag sensitive data and limit its accessibility to only relevant parties.
There are different approaches to performing data lineage strategically, Below, we explore four options to consider.
Lineage by data tagging involves adding tags to business data as it passes through various systems and processes. These tags function as identifiers that indicate critical information about the data’s source, transformation, and usage over time.
As the data advances through various systems and stages, you can add extra metadata tags to include critical new information about its processing.
To effectively use this method, it’s important to create a standard set of tags and ensure that they are adequately applied.
Self-contained lineage involves capturing and documenting the full history and movement of a specific data set within a single system or entity.
Essentially, this lineage strategy does not cover the transformation or transference of data across multiple systems or apps – just one.
Lineage by parsing involves analyzing data sources like tables and log files to extract critical information and create a lineage graph.
Basically, lineage by parsing entails converting data from one complex form to an easily understood version and then recording that change for future reference.
Pattern-based lineage focuses on tracking recurring trends or patterns in how data changes from one form to another in order to use (and reuse) them to present the history of multiple data sets.
So, instead of tracking data movement across individual elements, pattern-based lineage monitors and records data by common trends across multiple data assets.
Data lineage is a record of how data migrated and transformed throughout its lifecycle. This record aids data transparency and understanding.
Data provenance is the documentation of the origin, access, ownership, modification, and history of a data element. This process helps prove data integrity and accuracy.
Data governance covers the full set of policies and processes for managing data quality, privacy, and compliance.
Data lineage and provenance ensure that you always know where data was sourced and how it moved and transformed from its creation to deletion. Meanwhile, governance ensures that data collection and storage is standardized and follows a predefined set of processes and best practices.
As we alluded to above, poor data lineage is a recipe for confusion and chaos within a company. Without a clear record of data’s movements and transformations, businesses can find themselves second-guessing the accuracy of their data, or unable to pinpoint the root cause of data duplicates or inconsistencies.
Which leads us to the benefits of data lineage, which span from better data models to safeguarding consumer privacy.
Impact analysis is the process of analyzing when changes in a data field occurred to help troubleshoot issues. For example, if analysts discover data loss, they can trace it back to when they scanned an unclear document into their database and re-enter the file.
Data lineage helps with impact analysis by having a running record of any and all data transformations, which makes it easier to identify the root cause of issues.
There are numerous laws and regulations around data collection and usage across the world, from the GDPR to the CCPA and HIPAA. Being compliant with these regulations is easier when you have a clear view into the data lifecycle and can pinpoint which data should be masked or blocked entirely to maintain confidentiality (e.g., personally identifiable information).
With proper data lineage practices, businesses can ensure efficient data governance, audit their data management processes periodically, and more effectively manage risk.
Data modeling is the process of planning and visualizing how data will be organized, stored, and accessed in a system. It aims to provide a standard as to how data is collected and managed, while defining/cataloging important characteristics like data attributes, how different data elements relate to each other, etc.
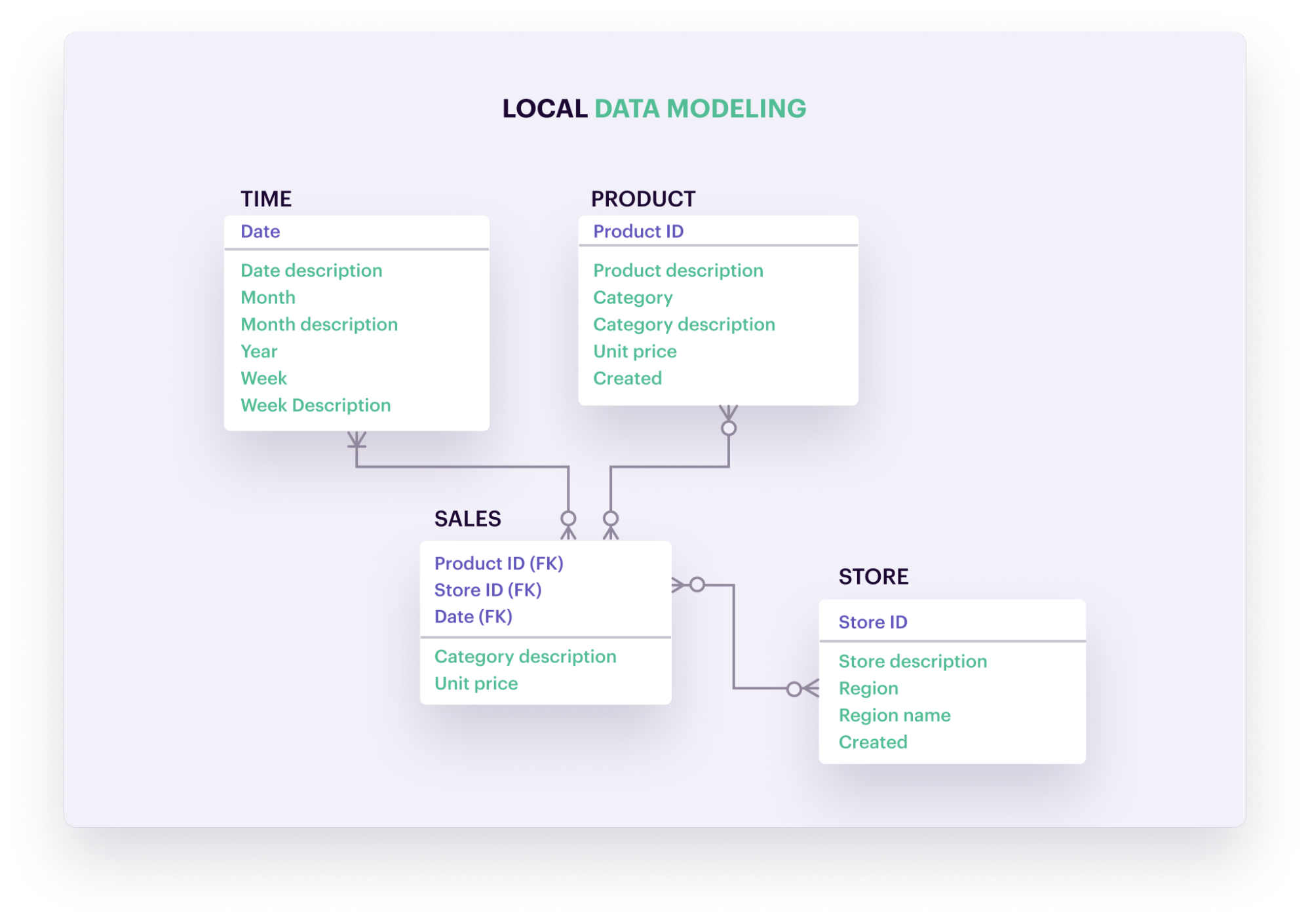
Data lineage helps inform and refine data models, revealing certain relationships between data elements that may have otherwise been unknown or accidentally bypassed. Data lineage also provides real-time context into the current flow of data within an organization – information that can be used to update previous data models and/or make them more precise.
There’s a major caveat to being “data driven”: you have to trust the data you’re working with. Bad data can wreak havoc on decision making, the customer experience, and a brand’s reputation.
Data lineage helps protect against bad data by creating transparency around its collection, transformations, and storage. Armed with this knowledge, businesses can trust the data they’re using is in fact accurate and up to date.
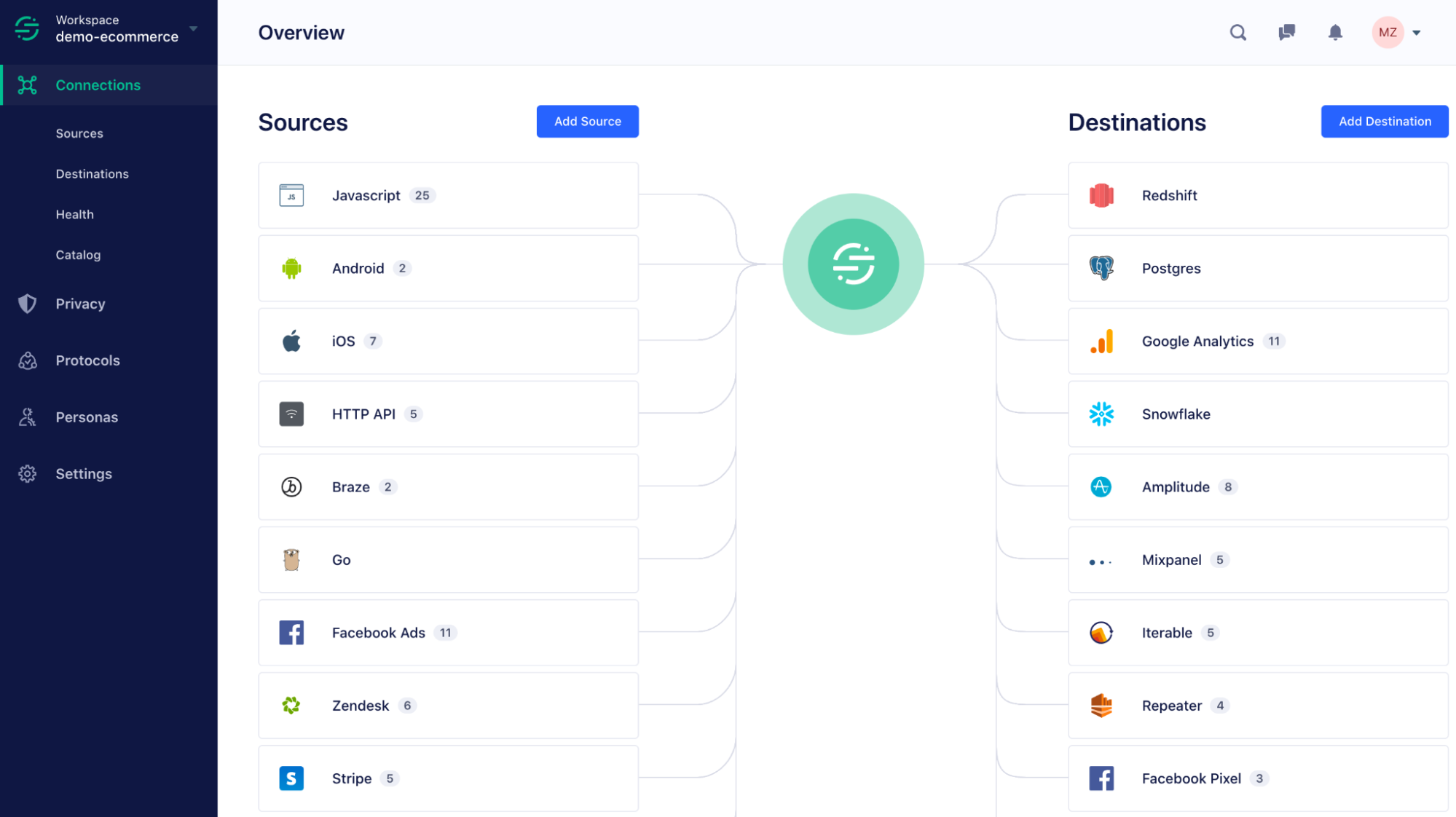
A customer data platform (CDP) like Segment helps businesses manage their data at scale, and can empower data lineage. Here are a few ways Segment provides greater control and visibility around data collection, processing, transformation, and activation.
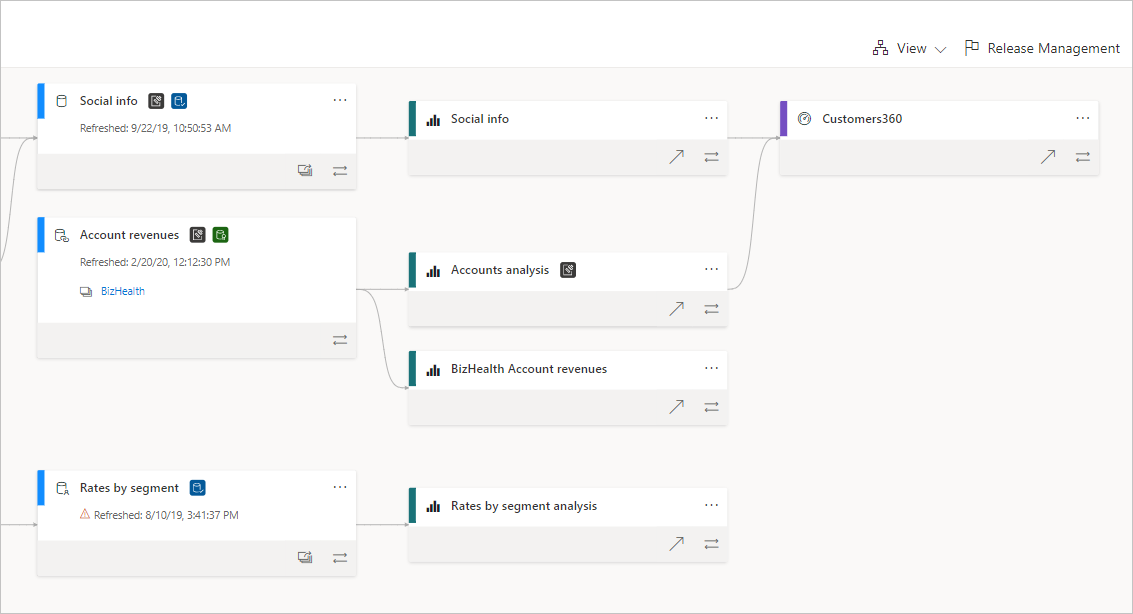
With all your data sources and destinations connected with the CDP, you can gain a complete view of how data flows from its source to final destinations (along with any transformations that took place along the way).
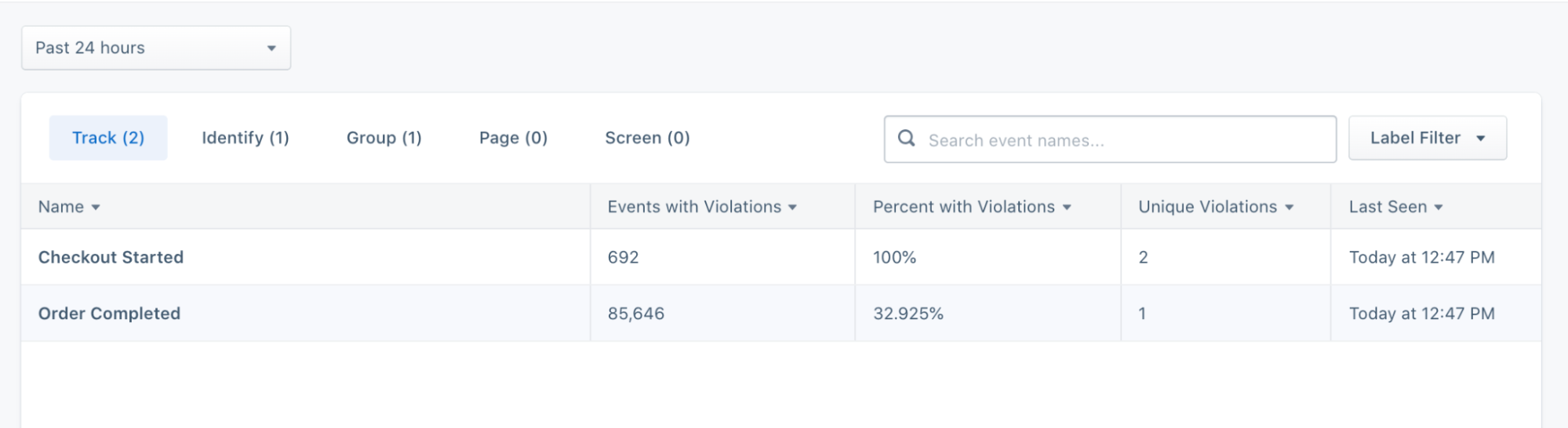
With Segment Protocols, you can seamlessly align your company around standard data specifications and enforce them at the point of collection or input. For instance, with Segment businesses can implement a universal Tracking Plan (or a data plan that outlines which events and properties you’ll be collecting across data Sources).
A data tracking plan helps businesses clarify what events they’re tracking, how they’re tracking them, and why. Use this template to help create your own tracking plan.
Thank you for downloading this content. We've also sent a copy to your inbox.
You can also customize your schema controls to selectively block certain events, properties, or traits.
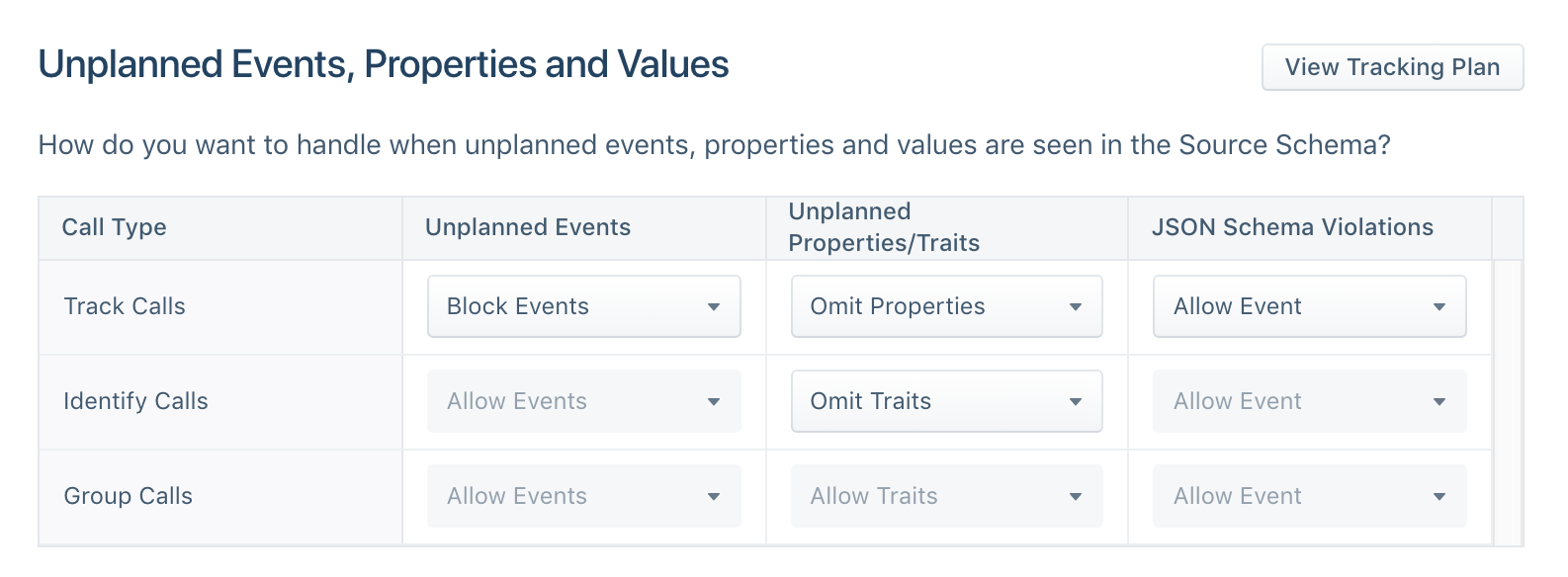
By implementing real-time data validation workflows and automatic enforcement controls within Segment, you can diagnose issues before they reach your data warehouse or downstream tools. You can then choose to forward blocked events to a relevant stakeholder for review.

Our annual look at how attitudes, preferences, and experiences with personalization have evolved over the past year.
Data lineage involves recording and tracking the flow of data throughout its lifecycle – from its source, to how it’s transformed, and where it’s ultimately stored. It provides businesses with important context as to why data underwent certain modifications, who was responsible for those modifications, and where the data came from in the first place. Having a clear record of how data is moved and transformed throughout the ETL process helps businesses better identify any potential issues, and validate the accuracy of the data they collect.
The different types of data lineage are: - Descriptive - Automated - Design - Business - Operations - Technical
Create a data lineage through either of the following four techniques: - Lineage by data tagging - Self-contained lineage - Lineage by parsing - Pattern-based lineage
__Data lineage__ is the record of the origin, movement, transformation, and connection of data elements throughout their lifecycle. __Data provenance__ is the documentation of the source, access, ownership, modification, and history of a dataset.